溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何使用Spark Streaming SQL基于時間窗口進行數據統計”,在日常操作中,相信很多人在如何使用Spark Streaming SQL基于時間窗口進行數據統計問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何使用Spark Streaming SQL基于時間窗口進行數據統計”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
流式計算一個很常見的場景是基于事件時間進行處理,常用于檢測、監控、根據時間進行統計等系統中。比如埋點日志中每條日志記錄了埋點處操作的時間,或者業務系統中記錄了用戶操作時間,用于統計各種操作處理的頻率等,或者根據規則匹配,進行異常行為檢測或監控系統告警。這樣的時間數據都會包含在事件數據中,需要提取時間字段并根據一定的時間范圍進行統計或者規則匹配等。
使用Spark Streaming SQL可以很方便的對事件數據中的時間字段進行處理,同時Spark Streaming SQL提供的時間窗口函數可以將事件時間按照一定的時間區間對數據進行統計操作。
本文通過講解一個統計用戶在過去5秒鐘內點擊網頁次數的案例,介紹如何使用Spark Streaming SQL對事件時間進行操作。
Spark Streaming SQL支持兩類窗口操作:滾動窗口(TUMBLING)和滑動窗口(HOPPING)。
滾動窗口(TUMBLING)根據每條數據的時間字段將數據分配到一個指定大小的窗口中進行操作,窗口以窗口大小為步長進行滑動,窗口之間不會出現重疊。例如:如果指定了一個5分鐘大小的滾動窗口,數據會根據時間劃分到 [0:00 - 0:05)、 [0:05, 0:10)、[0:10, 0:15)等窗口。
語法
GROUP BY TUMBLING ( colName, windowDuration )
示例
對inventory表的inv_data_time時間列進行窗口操作,統計inv_quantity_on_hand的均值;窗口大小為1分鐘。
SELECT avg(inv_quantity_on_hand) qohFROM inventoryGROUP BY TUMBLING (inv_data_time, interval 1 minute)
滑動窗口(HOPPING),也被稱作Sliding Window。不同于滾動窗口,滑動窗口可以設置窗口滑動的步長,所以窗口可以重疊。滑動窗口有兩個參數:windowDuration和slideDuration。slideDuration為每次滑動的步長,windowDuration為窗口的大小。當slideDuration < windowDuration時窗口會重疊,每個元素會被分配到多個窗口中。
所以,滾動窗口其實是滑動窗口的一種特殊情況,即slideDuration = windowDuration則等同于滾動窗口。
語法
GROUP BY HOPPING ( colName, windowDuration, slideDuration )
示例
對inventory表的inv_data_time時間列進行窗口操作,統計inv_quantity_on_hand的均值;窗口為1分鐘,滑動步長為30秒。
SELECT avg(inv_quantity_on_hand) qohFROM inventoryGROUP BY HOPPING (inv_data_time, interval 1 minute, interval 30 second)
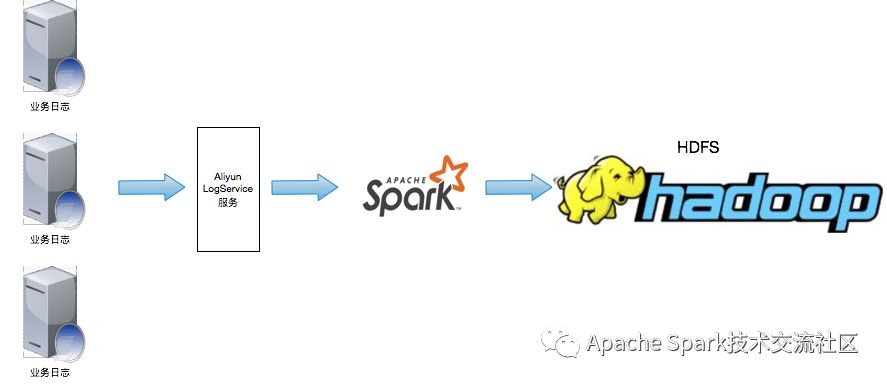
業務日志收集到Aliyun SLS后,Spark對接SLS,通過Streaming SQL對數據進行處理并將統計后的結果寫入HDFS中。后續的操作流程主要集中在Spark Streaming SQL接收SLS數據并寫入HDFS的部分,有關日志的采集請參考日志服務。
創建E-MapReduce 3.21.0以上版本的Hadoop集群。
下載并編譯E-MapReduce-SDK包
git clone git@github.com:aliyun/aliyun-emapreduce-sdk.gitcd aliyun-emapreduce-sdkgit checkout -b master-2.x origin/master-2.xmvn clean package -DskipTests
編譯完后, assembly/target目錄下會生成emr-datasources_shaded_${version}.jar,其中${version}為sdk的版本。
命令行啟動spark-sql客戶端
spark-sql --master yarn-client --num-executors 2 --executor-memory 2g --executor-cores 2 --jars emr-datasources_shaded_2.11-${version}.jar --driver-class-path emr-datasources_shaded_2.11-${version}.jar
創建SLS和HDFS表
spark-sql> CREATE DATABASE IF NOT EXISTS default;spark-sql> USE default;-- 數據源表spark-sql> CREATE TABLE IF NOT EXISTS sls_user_logUSING loghubOPTIONS (sls.project = "${logProjectName}",sls.store = "${logStoreName}",access.key.id = "${accessKeyId}",access.key.secret = "${accessKeySecret}",endpoint = "${endpoint}");--結果表spark-sql> CREATE TABLE hdfs_user_click_countUSING org.apache.spark.sql.jsonOPTIONS (path '${hdfsPath}');
其中,內建函數delay()用來設置Streaming SQL中的watermark,后續會有專門的文章介紹Streaming SQL watermark的相關內容。

可以看到,產生的結果會自動生成一個window列,包含窗口的起止時間信息。
到此,關于“如何使用Spark Streaming SQL基于時間窗口進行數據統計”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





