溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Spark Streaming編程方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Spark Streaming編程方法是什么”吧!
上一篇文章中介紹了常見的無狀態的轉換操作,比如在WordCount的例子中,輸出的結果只與當前batch interval的數據有關,不會依賴于上一個batch interval的計算結果。spark Streaming也提供了有狀態的操作:updateStateByKey,該算子會維護一個狀態,同時進行信息更新 。該操作會讀取上一個batch interval的計算結果,然后將其結果作用到當前的batch interval數據統計中。其源碼如下:
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
該算子只能在key–value對的DStream上使用,需要接收一個狀態更新函數 updateFunc作為參數。使用案例如下:
object StateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName(StateWordCount.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(5))
// 必須開啟checkpoint,否則會報錯
ssc.checkpoint("file:///e:/checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
// 狀態更新函數
def updateFunc(newValues: Seq[Int], stateValue: Option[Int]): Option[Int] = {
var oldvalue = stateValue.getOrElse(0) // 獲取狀態值
// 遍歷當前數據,并更新狀態
for (newValue <- newValues) {
oldvalue += newValue
}
// 返回最新的狀態
Option(oldvalue)
}
val count = lines.flatMap(_.split(" "))
.map(w => (w, 1))
.updateStateByKey(updateFunc)
count.print()
ssc.start()
ssc.awaitTermination()
}
}
尖叫提示:上面的代碼必須要開啟checkpoint,否則會報錯:
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint()
運行上面的代碼會發現一個現象:即便沒有數據源輸入,Spark也會為新的batch interval更新狀態,即如果沒有數據源輸入,則會不斷地輸出之前的計算狀態結果。
updateStateByKey可以在指定的批次間隔內返回之前的全部歷史數據,包括新增的,改變的和沒有改變的。由于updateStateByKey在使用的時候一定要做checkpoint,當數據量過大的時候,checkpoint會占據龐大的數據量,會影響性能,效率不高。
mapwithState是Spark提供的另外一個有狀態的算子,該操作克服了updateStateByKey的缺點,從Spark 1.5開始引入。源碼如下:
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self,
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
}
mapWithState只返回發生變化的key的值,對于沒有發生變化的Key,則不返回。這樣做可以只關心那些已經發生的變化的key,對于沒有數據輸入,則不會返回那些沒有變化的key 的數據。這樣的話,即使數據量很大,checkpint也不會updateBykey那樣,占用太多的存儲,效率比較高(生產環境中建議使用)。
object StatefulNetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("StatefulNetworkWordCount")
.setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("file:///e:/checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
/**
* word:當前key的值
* one:當前key對應的value值
* state:狀態值
*/
val mappingFunc = (batchTime: Time, word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
println(s">>> batchTime = $batchTime")
println(s">>> word = $word")
println(s">>> one = $one")
println(s">>> state = $state")
val output = (word, sum)
state.update(sum) //更新當前key的狀態值
Some(output) //返回結果
}
// 通過StateSpec.function構建StateSpec
val spec = StateSpec.function(mappingFunc)
val stateDstream = wordDstream.mapWithState(spec)
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
Spark Streaming提供了兩種類型的窗口操作,分別是滾動窗口和滑動窗口。具體分析如下:
滾動窗口的示意圖如下:滾動窗口只需要傳入一個固定的時間間隔,滾動窗口是不存在重疊的。
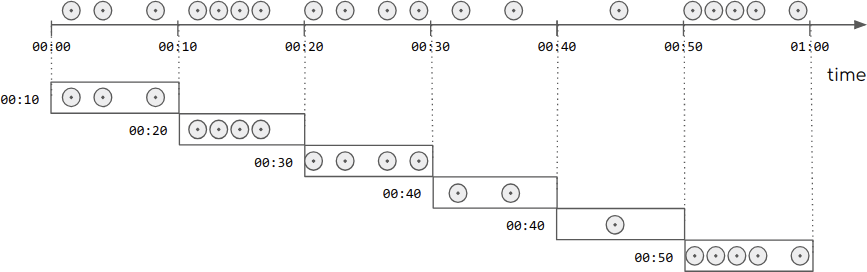
源碼如下:
/**
* @param windowDuration:窗口的長度; 必須是batch interval的整數倍.
*/
def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration
滑動窗口的示意圖如下:滑動窗口只需要傳入兩個參數,一個為窗口的長度,一個是滑動時間間隔。可以看出:滑動窗口是存在重疊的。
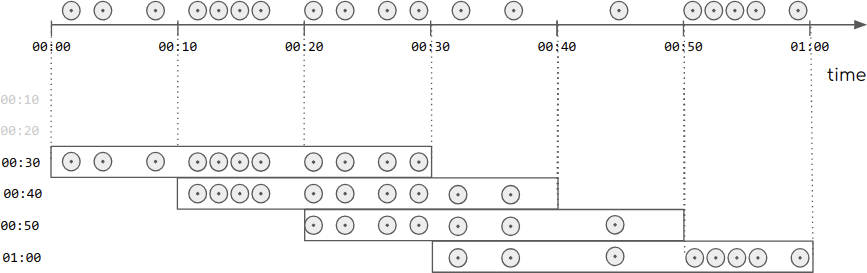
源碼如下:
/**
* @param windowDuration 窗口長度;必須是batching interval的整數倍
*
* @param slideDuration 滑動間隔;必須是batching interval的整數倍
*/
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
window(windowLength, slideInterval)
解釋
基于源DStream產生的窗口化的批數據,計算得到一個新的Dstream
源碼
def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration)
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
countByWindow(windowLength, slideInterval)
返回一個滑動窗口的元素個數
源碼
/**
* @param windowDuration window長度,必須是batch interval的倍數
* @param slideDuration 滑動的時間間隔,必須是batch interval的倍數
* 底層調用的是reduceByWindow
*/
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long] = ssc.withScope {
this.map(_ => 1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
}
reduceByWindow(func, windowLength, slideInterval)
返回一個單元素流。利用函數func聚集滑動時間間隔的流的元素創建這個單元素流。函數func必須滿足結合律,從而可以支持并行計算
源碼
def reduceByWindow(
reduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.reduce(reduceFunc).window(windowDuration, slideDuration).reduce(reduceFunc)
}
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
應用到一個(K,V)鍵值對組成的DStream上時,會返回一個由(K,V)鍵值對組成的新的DStream。每一個key的值均由給定的reduce函數(func函數)進行聚合計算。注意:在默認情況下,這個算子利用了Spark默認的并發任務數去分組。可以通過numTasks參數的設置來指定不同的任務數
源碼
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration, defaultPartitioner())
}
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
更加高效的reduceByKeyAndWindow,每個窗口的reduce值,是基于先前窗口的reduce值進行增量計算得到的;它會對進入滑動窗口的新數據進行reduce操作,并對離開窗口的老數據進行
逆向reduce操作。但是,只能用于可逆reduce函數,即那些reduce函數都有一個對應的逆向reduce函數(以InvFunc參數傳入)注意:必須開啟 checkpointing
源碼
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner,
filterFunc: ((K, V)) => Boolean
): DStream[(K, V)] = ssc.withScope {
val cleanedReduceFunc = ssc.sc.clean(reduceFunc)
val cleanedInvReduceFunc = ssc.sc.clean(invReduceFunc)
val cleanedFilterFunc = if (filterFunc != null) Some(ssc.sc.clean(filterFunc)) else None
new ReducedWindowedDStream[K, V](
self, cleanedReduceFunc, cleanedInvReduceFunc, cleanedFilterFunc,
windowDuration, slideDuration, partitioner
)
}
countByValueAndWindow(windowLength, slideInterval, [numTasks])
解釋
當應用到一個(K,V)鍵值對組成的DStream上,返回一個由(K,V)鍵值對組成的新的DStream。每個key的對應的value值都是它們在滑動窗口中出現的頻率
源碼
def countByValueAndWindow(
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int = ssc.sc.defaultParallelism)
(implicit ord: Ordering[T] = null)
: DStream[(T, Long)] = ssc.withScope {
this.map((_, 1L)).reduceByKeyAndWindow(
(x: Long, y: Long) => x + y,
(x: Long, y: Long) => x - y,
windowDuration,
slideDuration,
numPartitions,
(x: (T, Long)) => x._2 != 0L
)
}
val lines = ssc.socketTextStream("localhost", 9999)
val count = lines.flatMap(_.split(" "))
.map(w => (w, 1))
.reduceByKeyAndWindow((w1: Int, w2: Int) => w1 + w2, Seconds(30), Seconds(10))
.print()
//滾動窗口
/* lines.window(Seconds(20))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()*/
持久化是提升Spark應用性能的一種方式,在第二篇|Spark core編程指南一文中講解了RDD持久化的使用方式。其實,DStream也是支持持久化的,同樣是使用persist()與cache()方法,持久化通常在有狀態的算子中使用,比如窗口操作,默認情況下,雖然沒有顯性地調用持久化方法,但是底層已經幫用戶做了持久化操作,通過下面的源碼可以看出。
private[streaming]
class WindowedDStream[T: ClassTag](
parent: DStream[T],
_windowDuration: Duration,
_slideDuration: Duration)
extends DStream[T](parent.ssc) {
// 省略代碼...
// Persist parent level by default, as those RDDs are going to be obviously reused.
parent.persist(StorageLevel.MEMORY_ONLY_SER)
}
注意:與RDD的持久化不同,DStream的默認持久性級別將數據序列化在內存中,通過下面的源碼可以看出:
/** 給定一個持計劃級別 */
def persist(level: StorageLevel): DStream[T] = {
if (this.isInitialized) {
throw new UnsupportedOperationException(
"Cannot change storage level of a DStream after streaming context has started")
}
this.storageLevel = level
this
}
/** 默認的持久化級別為(MEMORY_ONLY_SER) */
def persist(): DStream[T] = persist(StorageLevel.MEMORY_ONLY_SER)
def cache(): DStream[T] = persist()
從上面的源碼可以看出persist()與cache()的主要區別是:
流應用程序通常是24/7運行的,因此必須對與應用程序邏輯無關的故障(例如系統故障,JVM崩潰等)具有彈性的容錯能力。為此,Spark Streaming需要將足夠的信息checkpoint到容錯存儲系統(比如HDFS),以便可以從故障中恢復。檢查點包括兩種類型:
元數據檢查點
元數據檢查點可以保證從Driver程序失敗中恢復。即如果運行drive的節點失敗時,可以查看最近的checkpoin數據獲取最新的狀態。典型的應用程序元數據包括:
數據檢查點
將生成的RDD保存到可靠的存儲中。在某些有狀態轉換中,需要合并多個批次中的數據,所以需要開啟檢查點。在此類轉換中,生成的RDD依賴于先前批次的RDD,這導致依賴鏈的長度隨時間不斷增加。為了避免恢復時間無限制的增加(與依賴鏈成比例),有狀態轉換的中間RDD定期 checkpoint到可靠的存儲(例如HDFS),以切斷依賴鏈,功能類似于持久化,只需要從當前的狀態恢復,而不需要重新計算整個lineage。
總而言之,從Driver程序故障中恢復時,主要需要元數據檢查點。而如果使用有狀態轉換,則需要數據或RDD檢查點。
必須為具有以下類型的應用程序啟用檢查點:
使用了有狀態轉換轉換操作
如果在應用程序中使用updateStateByKey或reduceByKeyAndWindow,則必須提供檢查點目錄以允許定期進行RDD檢查點。
從運行應用程序的Driver程序故障中恢復
元數據檢查點用于恢復進度信息。
注意,沒有前述狀態轉換的簡單流應用程序可以在不啟用檢查點的情況下運行。在這種情況下,從驅動程序故障中恢復也將是部分的(某些丟失但未處理的數據可能會丟失)。這通常是可以接受的,并且許多都以這種方式運行Spark Streaming應用程序。預計將來會改善對非Hadoop環境的支持。
可以通過具有容錯的、可靠的文件系統(例如HDFS,S3等)中設置目錄來啟用檢查點,將檢查點信息保存到該目錄中。開啟檢查點,需要開啟下面的兩個配置:
其中配置檢查點的時間間隔是可選的。如果不設置,會根據DStream的類型選擇一個默認值。對于MapWithStateDStream,默認的檢查點間隔是batch interval的10倍。對于其他的DStream,默認的檢查點間隔是10S,或者是batch interval的間隔時間。需要注意的是:checkpoint的頻率必須是 batch interval的整數倍,否則會報錯。
此外,如果要使應用程序從Driver程序故障中恢復,則需要使用下面的方式創建StreamingContext:
def createStreamingContext (conf: SparkConf,checkpointPath: String):
StreamingContext = {
val ssc = new StreamingContext( <ConfInfo> )
// .... other code ...
ssc.checkPoint(checkpointDirectory)
ssc
}
#創建一個新的StreamingContext或者從最近的checkpoint獲取
val context = StreamingContext.getOrCreate(checkpointDirectory,
createStreamingContext _)
#啟動
context.start()
context.awaitTermination()
注意:
RDD的檢查點需要將數據保存到可靠存儲上,由此帶來一些成本開銷。這可能會導致RDD獲得檢查點的那些批次的處理時間增加。因此,需要設置一個合理的檢查點的間隔。在batch interval較小時(例如1秒),每個batch interval都進行檢查點可能會大大降低吞吐量。相反,檢查點時間間隔太長會導致 lineage和任務規模增加,這可能會產生不利影響。對于需要RDD檢查點的有狀態轉換,默認間隔為batch interval的倍數,至少應為10秒。可以使用 **dstream.checkpoint(checkpointInterval)**進行配置。通常,DStream的5-10個batch interval的檢查點間隔是一個較好的選擇。
持久化
檢查點
在Spark Streaming應用中,可以輕松地對流數據使用DataFrames和SQL操作。使用案例如下:
object SqlStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(SqlStreaming.getClass.getSimpleName)
.setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
words.foreachRDD { rdd =>
// 調用SparkSession單例方法,如果已經創建了,則直接返回
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
val wordsDataFrame = rdd.toDF("word")
wordsDataFrame.show()
wordsDataFrame.createOrReplaceTempView("words")
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
}
/** SparkSession單例 */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}感謝各位的閱讀,以上就是“Spark Streaming編程方法是什么”的內容了,經過本文的學習后,相信大家對Spark Streaming編程方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





