溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Spark Streaming算子開發的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Spark Streaming算子開發實例
transform算子開發
transform操作應用在DStream上時,可以用于執行任意的RDD到RDD的轉換操作,還可以用于實現DStream API中所沒有提供的操作,比如說,DStreamAPI中并沒有提供將一個DStream中的每個batch,與一個特定的RDD進行join的操作,DStream中的join算子只能join其他DStream,但是我們自己就可以使用transform操作來實現該功能。
實例:黑名單用戶實時過濾
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 實時黑名單過濾
*/
object TransformDemo {
def main(args: Array[String]): Unit = {
//設置日志級別
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
//創建一個黑名單的RDD
val blackRDD =
ssc.sparkContext.parallelize(Array(("zs", true), ("lisi", true)))
//通過socket從nc中獲取數據
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
/**
* 過濾黑名單用戶發言
* zs sb sb sb sb
* lisi fuck fuck fuck
* jack hello
*/
linesDStream
.map(x => {
val info = x.split(" ")
(info(0), info.toList.tail.mkString(" "))
})
.transform(rdd => { //transform是一個RDD->RDD的操作,所以返回值必須是RDD
/**
* 經過leftouterjoin操作之后,產生的結果如下:
* (zs,(sb sb sb sb),Some(true)))
* (lisi,(fuck fuck fuck),some(true)))
* (jack,(hello,None))
*/
val joinRDD = rdd.leftOuterJoin(blackRDD)
//如果是Some(true)的,說明就是黑名單用戶,如果是None的,說明不在黑名單內,把非黑名單的用戶保留下來
val filterRDD = joinRDD.filter(x => x._2._2.isEmpty)
filterRDD
})
.map(x=>(x._1,x._2._1)).print()
ssc.start()
ssc.awaitTermination()
}
}測試
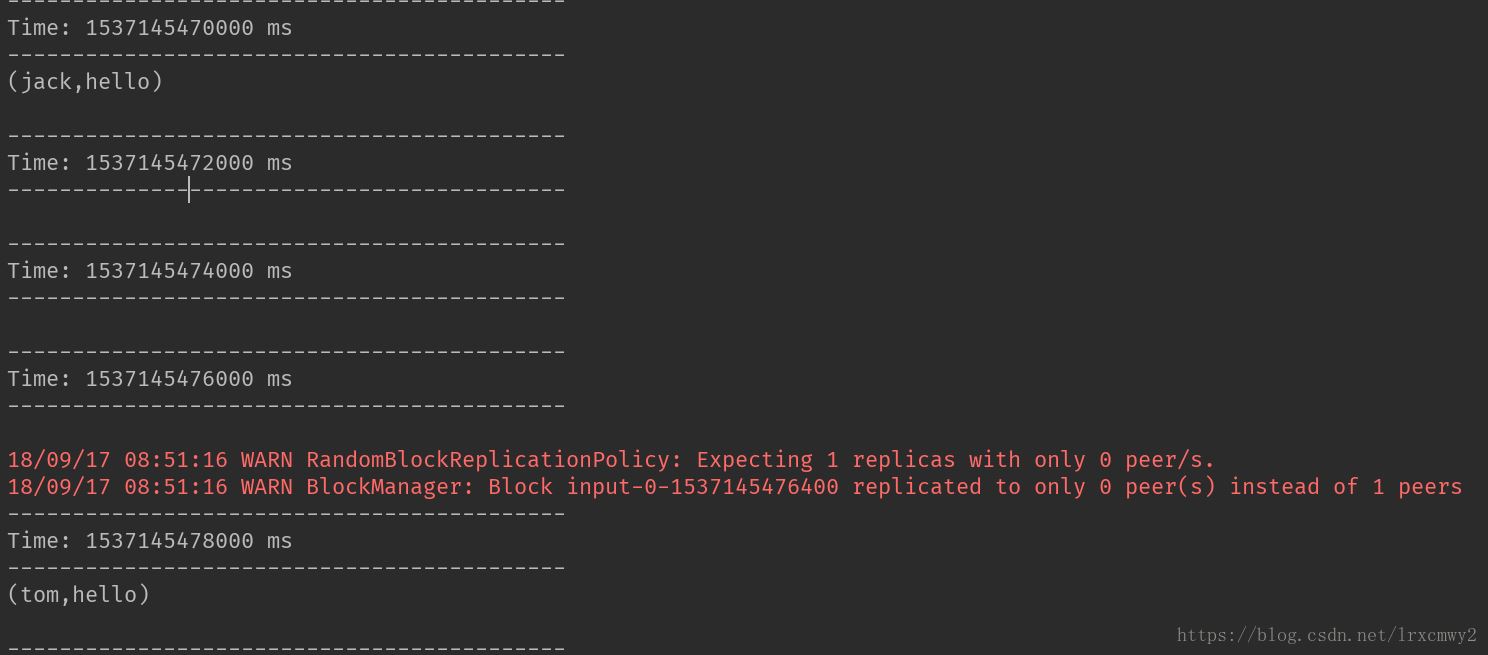
啟動nc,傳入用戶及其發言信息

可以看到程序實時的過濾掉了在黑名單里的用戶發言
updateStateByKey算子開發
updateStateByKey算子可以保持任意狀態,同時不斷有新的信息進行更新,這個算子可以為每個key維護一份state,并持續不斷的更新state。對于每個batch來說,Spark都會為每個之前已經存在的key去應用一次State更新函數,無論這個key在batch中是否有新的值,如果State更新函數返回的值是none,那么這個key對應的state就會被刪除;對于新出現的key也會執行state更新函數。
要使用該算子,必須進行兩個步驟
定義state——state可以是任意的數據類型
定義state更新函數——用一個函數指定如何使用之前的狀態,以及從輸入流中獲取新值更新狀態
注意:updateStateByKey操作,要求必須開啟Checkpoint機制
實例:基于緩存的實時WordCount
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于緩存的實時WordCount,在全局范圍內統計單詞出現次數
*/
object UpdateStateByKeyDemo {
def main(args: Array[String]): Unit = {
//設置日志級別
Logger.getLogger("org").setLevel(Level.WARN)
/**
* 如果沒有啟用安全認證或者從Kerberos獲取的用戶為null,那么獲取HADOOP_USER_NAME環境變量,
* 并將它的值作為Hadoop執行用戶設置hadoop username
* 這里實驗了一下在沒有啟用安全認證的情況下,就算不顯式添加,也會自動獲取我的用戶名
*/
//System.setProperty("HADOOP_USER_NAME","Setsuna")
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
//設置Checkpoint存放的路徑
ssc.checkpoint("hdfs://Hadoop01:9000/checkpoint")
//創建輸入DStream
val lineDStream = ssc.socketTextStream("Hadoop01", 6666)
val wordDStream = lineDStream.flatMap(_.split(" "))
val pairsDStream = wordDStream.map((_, 1))
/**
* state:代表之前的狀態值
* values:代表當前batch中key對應的values值
*/
val resultDStream =
pairsDStream.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
//當state為none,表示沒有對這個單詞做統計,則返回0值給計數器count
var count = state.getOrElse(0)
//遍歷values,累加新出現的單詞的value值
for (value <- values) {
count += value
}
//返回key對應的新state,即單詞的出現次數
Option(count)
})
//在控制臺輸出
resultDStream.print()
ssc.start()
ssc.awaitTermination()
}
}測試
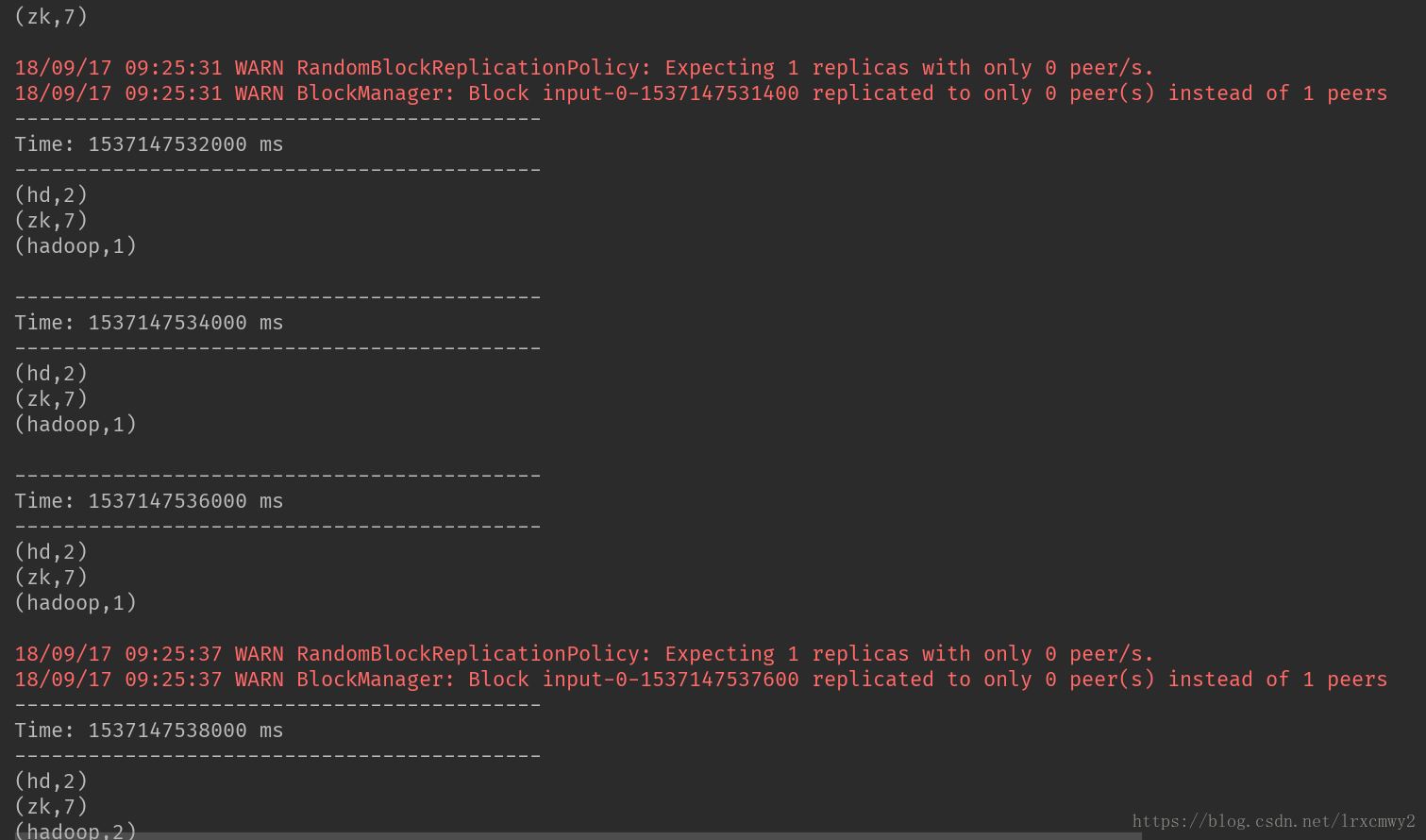
開啟nc,輸入單詞

控制臺實時輸出的結果
window滑動窗口算子開發
Spark Streaming提供了滑動窗口操作的支持,可以對一個滑動窗口內的數據執行計算操作
在滑動窗口中,包含批處理間隔、窗口間隔、滑動間隔
對于窗口操作而言,在其窗口內部會有N個批處理數據
批處理數據的大小由窗口間隔決定,而窗口間隔指的就是窗口的持續時間,也就是窗口的長度
滑動時間間隔指的是經過多長時間窗口滑動一次,形成新的窗口,滑動間隔默認情況下和批處理時間間隔的相同
注意:滑動時間間隔和窗口時間間隔的大小一定得設置為批處理間隔的整數倍
用一個官方的圖來作為說明
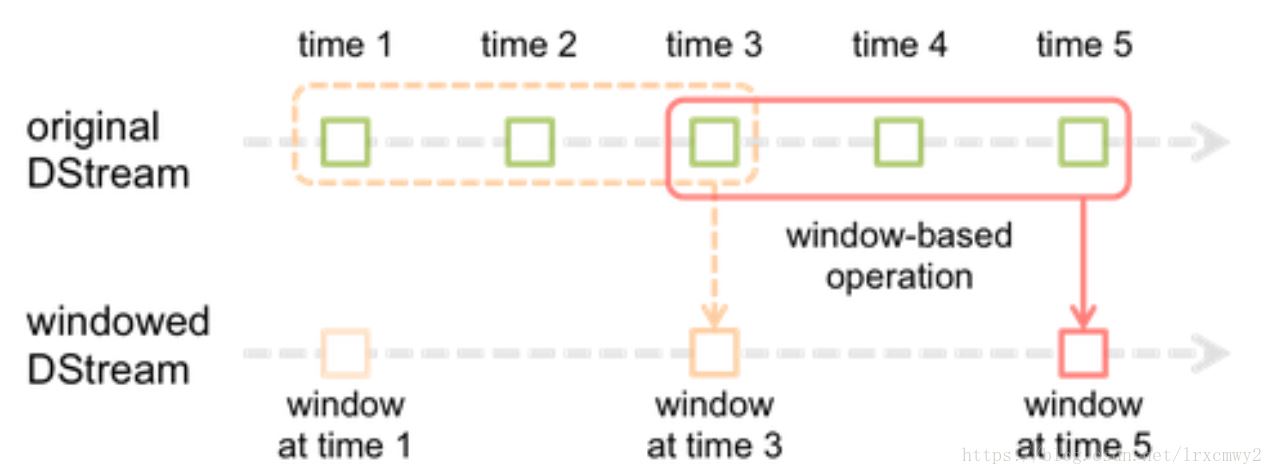
批處理間隔是1個時間單位,窗口間隔是3個時間單位,滑動間隔是2個時間單位。對于初始的窗口time1-time3,只有窗口間隔滿足了才觸發數據的處理。所以滑動窗口操作都必須指定兩個參數,窗口長度和滑動時間間隔。在Spark Streaming中對滑動窗口的支持是比Storm更加完善的。
Window滑動算子操作
| 算子 | 描述 |
| window() | 對每個滑動窗口的數據執行自定義的計算 |
| countByWindow() | 對每個滑動窗口的數據執行count操作 |
| reduceByWindow() | 對每個滑動窗口的數據執行reduce操作 |
| reduceByKeyAndWindow() | 對每個滑動窗口的數據執行reduceByKey操作 |
| countByValueAndWindow() | 對每個滑動窗口的數據執行countByValue操作 |
reduceByKeyAndWindow算子開發
實例:在線熱點搜索詞實時滑動統計
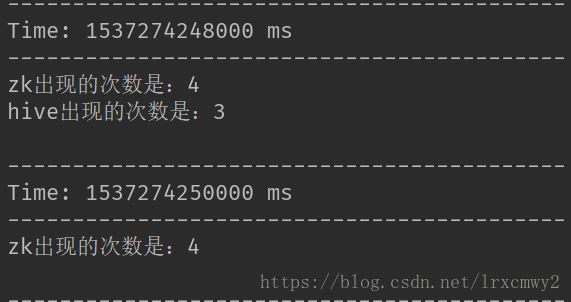
每隔2秒鐘,統計最近5秒鐘的搜索詞中排名最靠前的3個搜索詞以及出現次數
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 需求:每隔2秒鐘,統計最近5秒鐘的搜索詞中排名最靠前的3個搜索詞以及出現次數
*/
object ReduceByKeyAndWindowDemo {
def main(args: Array[String]): Unit = {
//設置日志級別
Logger.getLogger("org").setLevel(Level.WARN)
//基礎配置
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
//批處理間隔設置為1s
val ssc = new StreamingContext(conf, Seconds(1))
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
linesDStream
.flatMap(_.split(" ")) //根據空格來做分詞
.map((_, 1)) //返回(word,1)
.reduceByKeyAndWindow(
//定義窗口如何計算的函數
//x代表的是聚合后的結果,y代表的是這個Key對應的下一個需要聚合的值
(x: Int, y: Int) => x + y,
//窗口長度為5秒
Seconds(5),
//窗口時間間隔為2秒
Seconds(2)
)
.transform(rdd => { //transform算子對rdd做處理,轉換為另一個rdd
//根據Key的出現次數來進行排序,然后降序排列,獲取最靠前的3個搜索詞
val info: Array[(String, Int)] = rdd.sortBy(_._2, false).take(3)
//將Array轉換為resultRDD
val resultRDD = ssc.sparkContext.parallelize(info)
resultRDD
})
.map(x => s"${x._1}出現的次數是:${x._2}")
.print()
ssc.start()
ssc.awaitTermination()
}
}測試結果
DStream Output操作概覽
Spark Streaming允許DStream的數據輸出到外部系統,DSteram中的所有計算,都是由output操作觸發的,foreachRDD輸出操作,也必須在里面對RDD執行action操作,才能觸發對每一個batch的計算邏輯。
| 轉換 | 描述 |
| print() | 在Driver中打印出DStream中數據的前10個元素。主要用于測試,或者是不需要執行什么output操作時,用于簡單觸發一下job。 |
| saveAsTextFiles(prefix, [suffix]) | 將DStream中的內容以文本的形式保存為文本文件,其中每次批處理間隔內產生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsObjectFiles(prefix , [suffix]) | 將DStream中的內容按對象序列化并且以SequenceFile的格式保存。其中每次批處理間隔內產生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsHadoopFiles(pref ix, [suffix]) | 將DStream中的內容以文本的形式保存為Hadoop文件,其中每次批處理間隔內產生的文件 以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的輸出操作,將func函數應用于DStream中的RDD上,這個操作會輸出數據到外部系 統,比如保存RDD到文件或者網絡數據庫等。需要注意的是func函數是在運行該streaming 應用的Driver進程里執行的。 |
foreachRDD算子開發
foreachRDD是最常用的output操作,可以遍歷DStream中的每個產生的RDD并進行處理,然后將每個RDD中的數據寫入外部存儲,如文件、數據庫、緩存等,通常在其中針對RDD執行action操作,比如foreach
使用foreachRDD操作數據庫
通常在foreachRDD中都會創建一個Connection,比如JDBC Connection,然后通過Connection將數據寫入外部存儲
誤區一:在RDD的foreach操作外部創建Connection
dstream.foreachRDD { rdd =>
val connection=createNewConnection()
rdd.foreach { record => connection.send(record)
}
}這種方式是錯誤的,這樣的方式會導致Connection對象被序列化后被傳輸到每一個task上,但是Connection對象是不支持序列化的,所以也就無法被傳輸
誤區二:在RDD的foreach操作內部創建Connection
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}這種方式雖然是可以的,但是執行效率會很低,因為它會導致對RDD中的每一條數據都創建一個Connection對象,通常Connection對象的創建都是很消耗性能的
合理的方式
第一種:使用RDD的foreachPartition操作,并且在該操作內部創建Connection對象,這樣就相當于為RDD的每個partition創建一個Connection對象,節省了很多資源
第二種:自己手動封裝一個靜態連接池,使用RDD的foreachPartition操作,并且在該操作內部從靜態連接池中,通過靜態方法獲取到一個連接,連接使用完之后再放回連接池中。這樣的話,可以在多個RDD的partition之間復用連接了
實例:實時全局統計WordCount,并將結果保存到MySQL數據庫中
MySQL數據庫建表語句如下
CREATE TABLE wordcount ( word varchar(100) CHARACTER SET utf8 NOT NULL, count int(10) NOT NULL, PRIMARY KEY (word) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
在IDEA中添加mysql-connector-java-5.1.40-bin.jar

代碼如下
連接池的代碼,其實一開始有想過用靜態塊來寫個池子直接獲取,但是如果考慮到池子寬度不夠用的問題,這樣的方式其實更好,一開始,實例化一個連接池出來,被調用獲取連接,當連接全部都被獲取了的時候,池子空了,就再實例化一個池子出來
package StreamingDemo
import java.sql.{Connection, DriverManager, SQLException}
import java.util
object JDBCManager {
var connectionQue: java.util.LinkedList[Connection] = null
/**
* 從數據庫連接池中獲取連接對象
* @return
*/
def getConnection(): Connection = {
synchronized({
try {
//如果連接池是空的,那么就實例化一個Connection類型的鏈表
if (connectionQue == null) {
connectionQue = new util.LinkedList[Connection]()
for (i <- 0 until (10)) {
//生成10個連接,并配置相關信息
val connection = DriverManager.getConnection(
"jdbc:mysql://Hadoop01:3306/test?characterEncoding=utf-8",
"root",
"root")
//將連接push進連接池
connectionQue.push(connection)
}
}
} catch {
//捕獲異常并輸出
case e: SQLException => e.printStackTrace()
}
//如果連接池不為空,則返回表頭元素,并將它在鏈表里刪除
return connectionQue.poll()
})
}
/**
* 當連接對象用完后,需要調用這個方法歸還連接
* @param connection
*/
def returnConnection(connection: Connection) = {
//插入元素
connectionQue.push(connection)
}
def main(args: Array[String]): Unit = {
//main方法測試
getConnection()
println(connectionQue.size())
}
}wordcount代碼
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, streaming}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object ForeachRDDDemo {
def main(args: Array[String]): Unit = {
//設置日志級別,避免INFO信息過多
Logger.getLogger("org").setLevel(Level.WARN)
//設置Hadoop的用戶,不加也可以
System.setProperty("HADOOP_USER_NAME", "Setsuna")
//Spark基本配置
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, streaming.Seconds(2))
//因為要使用updateStateByKey,所以需要使用checkpoint
ssc.checkpoint("hdfs://Hadoop01:9000/checkpoint")
//設置socket,跟nc配置的一樣
val linesDStream = ssc.socketTextStream("Hadoop01", 6666)
val wordCountDStream = linesDStream
.flatMap(_.split(" ")) //根據空格做分詞
.map((_, 1)) //生成(word,1)
.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
//實時更新狀態信息
var count = state.getOrElse(0)
for (value <- values) {
count += value
}
Option(count)
})
wordCountDStream.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
rdd.foreachPartition(part => {
//從連接池中獲取連接
val connection = JDBCManager.getConnection()
part.foreach(data => {
val sql = //往wordcount表中插入wordcount信息,on duplicate key update子句是有則更新無則插入
s"insert into wordcount (word,count) " +
s"values ('${data._1}',${data._2}) on duplicate key update count=${data._2}"
//使用prepareStatement來使用sql語句
val pstmt = connection.prepareStatement(sql)
pstmt.executeUpdate()
})
//在連接處提交完數據后,歸還連接到連接池
JDBCManager.returnConnection(connection)
})
}
})
ssc.start()
ssc.awaitTermination()
}
}打開nc,輸入數據

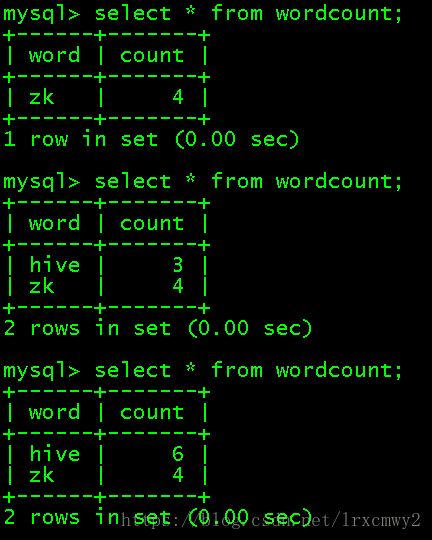
在另一個終端對wordcount的結果進行查詢,可以發現是實時發生變化的
感謝各位的閱讀!關于“Spark Streaming算子開發的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





