溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
[TOC]
1、Spark Streaming,其實就是一種Spark提供的,對于大數據,進行實時計算的一種框架。它的底層,其實,也是基于我們之前講解的Spark Core的。基本的計算模型,還是基于內存的大數據實時計算模型。而且,它的底層的核心組件還是我們在Spark Core中經常用到的RDD。
2、針對實時計算的特點,在RDD之上,進行了一層封裝,叫做DStream。其實,學過了Spark SQL之后,你理解這種封裝就容易了。之前學習Spark SQL是不是也是發現,它針對數據查詢這種應用,提供了一種基于RDD之上的全新概念,DataFrame,但是,其底層還是基于RDD的。所以,RDD是整個Spark技術生態中的核心。
正如市面上存在眾多可用的流處理引擎,人們經常詢問我們Spark Streaming有何獨特的優勢?那么首先要說的就是Apache Spark在批處理以及流處理上提供了原生支持。這與別的系統不同之處在于其他系統的處理引擎要么只專注于流處理,要么只負責批處理且僅提供需要外部實現的流處理API接口而已。Spark 憑借其執行引擎以及統一的編程模型可實現批處理與流處理,這就是與傳統流處理系統相比Spark Streaming所具備獨一無二的優勢。尤其特別體現在以下四個重要部分:
1.能在故障報錯與straggler的情況下迅速恢復狀態;
2.更好的負載均衡與資源使用;
3.靜態數據集與流數據的整合和可交互查詢;
4.內置豐富高級算法處理庫(SQL、機器學習、圖處理)當前分布式流處理管道執行方式如下所述:
1、接收來自數據源的流數據(比如時日志、系統遙測數據、物聯網設備數據等等),處理成為數據攝取系統,比如Apache Kafka、Amazon Kinesis等等。
2、在集群上并行處理數據。這也是設計流處理引擎的關鍵所在,我們將在下文中做出更細節性的討論。
3、輸出結果存放至下游系統(例如HBase、Cassandra, Kafka等等)。
為了處理這些數據,大部分傳統的流處理系統被設計為連續算子 模型,其工作方式如下:
1、有一系列的工作節點,每組節點運行一至多個連續算子;
2、對于流數據,每個連續算子一次處理一條記錄,并且將記錄傳輸給管道中別的算子;
3、源算子從攝入系統接收數據,接著輸出到下游系統。
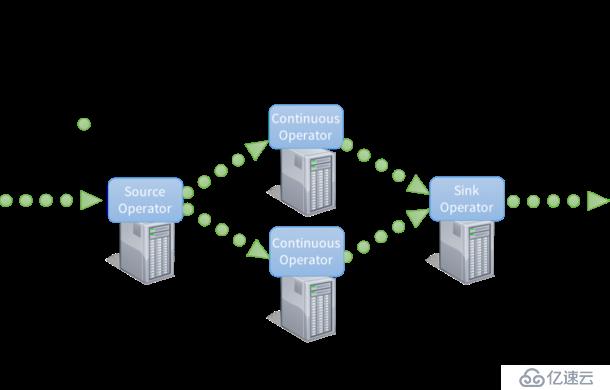
1、連續算子是一種較為簡單、自然的模型。然而,隨著如今大數據時代下,數據規模的不斷擴大以及越來越復雜的實時分析,這個傳統的架構也面臨著嚴峻的挑戰。因此,我們設計Spark Streaming就是為了解決如下幾點需求:
2、故障迅速恢復–數據越龐大,出現節點故障與節點運行變慢(例如straggler)情況的概率也越來越高。因此,系統要是能夠實時給出結果,就必須能夠自動修復故障。可惜在傳統流處理系統中,在這些工作節點靜態分配的連續算子要迅速完成這項工作仍然是個挑戰;
3、負載均衡–在連續算子系統中工作節點間不平衡分配加載會造成部分節點性能的bottleneck(運行瓶頸)。這些問題更常見于大規模數據與動態變化的工作量面前。為了解決這個問題,那么要求系統必須能夠根據工作量動態調整節點間的資源分配;
4、統一的流處理與批處理以及交互工作–在許多用例中,與流數據的交互是很有必要的(畢竟所有流系統都將這置于內存中)或者與靜態數據集結合(例如pre-computed model)。這些都很難在連續算子系統中實現,當系統動態地添加新算子時,并沒有為其設計臨時查詢功能,這樣大大的削弱了用戶與系統的交互能力。因此我們需要一個引擎能夠集成批處理、流處理與交互查詢;
5、高級分析(例如機器學習、SQL查詢等等)–一些更復雜的工作需要不斷學習和更新數據模型,或者利用SQL查詢流數據中最新的特征信息。因此,這些分析任務中需要有一個共同的集成抽象組件,讓開發人員更容易地去完成他們的工作。
6、為了解決這些要求,Spark Streaming使用了一個新的結構,我們稱之為discretized streams(離散化的流數據處理),它可以直接使用Spark引擎中豐富的庫并且擁有優秀的故障容錯機制。
1、Spark的運行模式多種多樣,靈活多變,部署在單機上時,既可以用本地模式運行,也可以用偽分布式模式運行;而當以分布式集群的方式部署時,也有眾多的運行模式可供選擇,這取決于集群的實際情況,底層的資源調度既可以依賴于外部的資源調度框架,也可以使用Spark內建的Standalone模式。對于外部資源調度框架的支持,目前的實現包括相對穩定的Mesos模式,以及還在持續開發更新中的Hadoop YARN模式。
2、Spark Streaming是Spark Core API的一種擴展,它可以用于進行大規模、高吞吐量、容錯的實時數據流的處理。它支持從很多種數據源中讀取數據,比如Kafka、Flume、Twitter、ZeroMQ、Kinesis、ZMQ或者是TCP Socket。并且能夠使用類似高階函數的復雜算法來進行數據處理,比如map、reduce、join和window。處理后的數據可以被保存到文件系統、數據庫、Dashboard等存儲中。

接收實時輸入數據流,然后將數據拆分成多個batch,比如每收集1秒的數據封裝為一個batch,然后將每個batch交給Spark的計算引擎進行處理,最后會生產出一個結果數據流,其中的數據,也是由一個一個的batch所組成的。
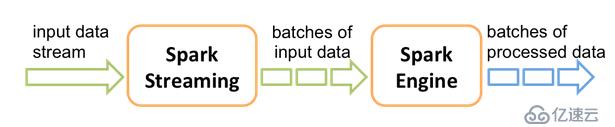
1、Spark Streaming提供了一種高級的抽象,叫做DStream,英文全稱為Discretized Stream,中文翻譯為“離散流”,它代表了一個持續不斷的數據流。DStream可以通過輸入數據源來創建,比如Kafka、Flume、ZMQ和Kinesis;也可以通過對其他DStream應用高階函數來創建,比如map、reduce、join、window。
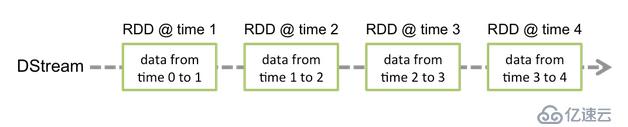
2、DStream的內部,其實一系列持續不斷產生的RDD。RDD是Spark Core的核心抽象,即,不可變的,分布式的數據集。DStream中的每個RDD都包含了一個時間段內的數據。
1、對DStream應用的算子,比如map,其實在底層會被翻譯為對DStream中每個RDD的操作。比如對一個DStream執行一個map操作,會產生一個新的DStream。但是,在底層,其實其原理為,對輸入DStream中每個時間段的RDD,都應用一遍map操作,然后生成的新的RDD,即作為新的DStream中的那個時間段的一個RDD。底層的RDD的transformation操作。
2、還是由Spark Core的計算引擎來實現的。Spark Streaming對Spark Core進行了一層封裝,隱藏了細節,然后對開發人員提供了方便易用的高層次的API。
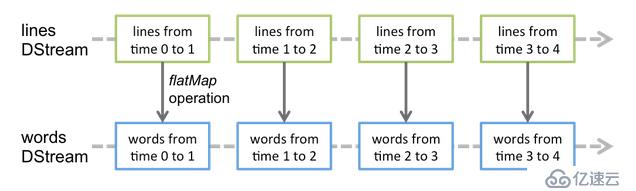
| 對比點 | Storm | Spark Streaming | Flink |
|---|---|---|---|
| 實時計算模型 | 純實時,來一條數據處理一條 | 1、準實時,對一個時間段的RDD數據收集起來,一起處理 | 流式計算和批處理分別采用DataStream和DataSet |
| 實時計算延遲度 | 毫秒級 | 秒級 | 秒級 |
| 吞吐量 | 低 | 高 | 高 |
| 事務機制 | 支持完善 | 支持,但不夠完善 | 支持,但不夠完善 |
| 健壯性/容錯性 | ZK、Acker,很好 | CheckPoint,WAL一般 | CheckPoint一般 |
| 動態調整并行度 | 支持 | 不支持 | 支持 |
| 運行時同時支持流失和離線處理 | 不支持 | 支持 | 支持 |
| 成熟度 | 高 | 高 | 低 |
| 模型 | native | Micro-batching | native |
| API | 組合式 | 聲明式 | 組合式 |
1、Spark Streaming絕對談不上比Storm、Flink優秀。這兩個框架在實時計算領域中,都很優秀,只是擅長的細分場景并不相同。
2、Spark Streaming在吞吐量上要比Storm優秀。
3、Storm在實時延遲度上,比Spark Streaming就好多了,前者是純實時,后者是準實時。而且,Storm的事務機制、健壯性/容錯性、動態調整并行度等特性,都要比Spark Streaming更加優秀。
4、Spark Streaming,有一點是Storm絕對比不上的,就是:它位于Spark整個生態技術棧中,因此Spark Streaming可以和Spark Core、Spark SQL、Spark Graphx無縫整合,換句話說,我們可以對實時處理出來的中間數據,立即在程序中無縫進行延遲批處理、交互式查詢等操作。這個特點大大增強了Spark Streaming的優勢和功能。
1、建議在需要純實時,不能忍受1秒以上延遲的場景下使用,比如實時計算系統,要求純實時進行交易和分析時。
2、在實時計算的功能中,要求可靠的事務機制和可靠性機制,即數據的處理完全精準,一條也不能多,一條也不能少,也可以考慮使用Storm,但是Spark Streaming也可以保證數據的不丟失。
3、如果我們需要考慮針對高峰低峰時間段,動態調整實時計算程序的并行度,以最大限度利用集群資源(通常是在小型公司,集群資源緊張的情況),我們也可以考慮用Storm
1、不滿足上述3點要求的話,我們可以考慮使用Spark Streaming來進行實時計算。
2、考慮使用Spark Streaming最主要的一個因素,應該是針對整個項目進行宏觀的考慮,即,如果一個項目除了實時計算之外,還包括了離線批處理、交互式查詢、圖計算和MLIB機器學習等業務功能,而且實時計算中,可能還會牽扯到高延遲批處理、交互式查詢等功能,那么就應該首選Spark生態,用Spark Core開發離線批處理,用Spark SQL開發交互式查詢,用Spark Streaming開發實時計算,三者可以無縫整合,給系統提供非常高的可擴展性。
1.支持高吞吐、低延遲、高性能的流處理
2.支持帶有事件時間的窗口(Window)操作
3.支持有狀態計算的Exactly-once語義
4.支持高度靈活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
5.支持具有Backpressure功能的持續流模型
6.支持基于輕量級分布式快照(Snapshot)實現的容錯
7.一個運行時同時支持Batch on Streaming處理和Streaming處理
8.Flink在JVM內部實現了自己的內存管理
9.支持迭代計算
10.支持程序自動優化:避免特定情況下Shuffle、排序等昂貴操作,中間結果有必要進行緩存免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





