溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Spark Streaming怎么使用”,在日常操作中,相信很多人在Spark Streaming怎么使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Spark Streaming怎么使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
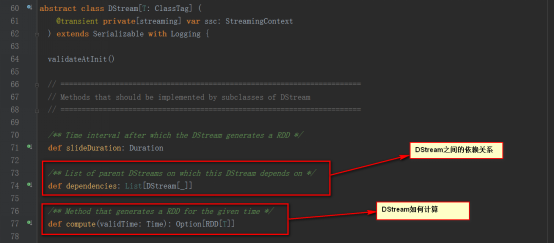
DStream是邏輯級別的,而RDD是物理級別的。DStream是隨著時間的流動內部將集合封裝RDD。對DStream的操作,轉過來對其內部的RDD操作。
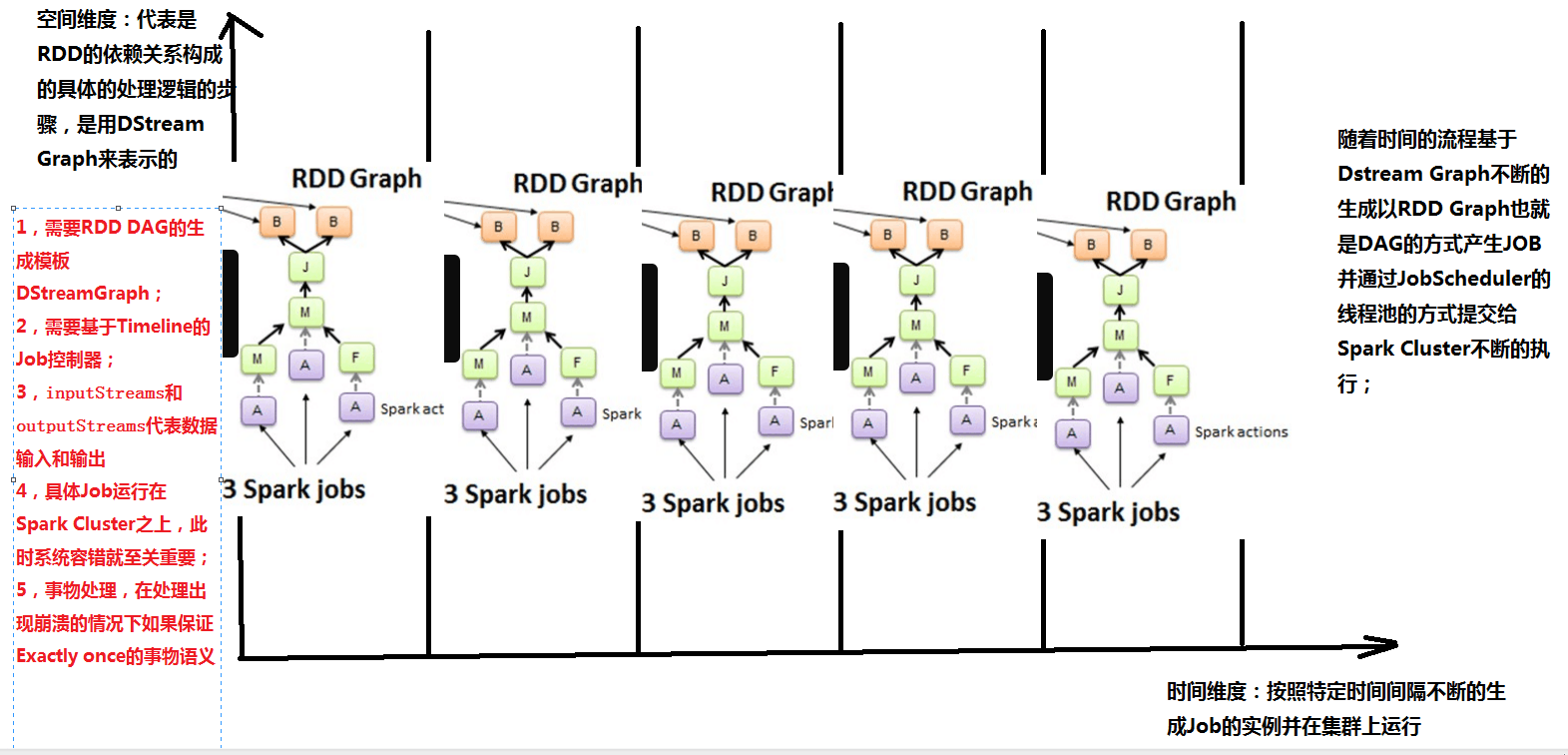
縱軸為空間維度:代表的是RDD的依賴關系構成的具體的處理邏輯的步驟,是用DStream來表示的。
橫軸為時間維度:按照特定的時間間隔不斷地生成job對象,并在集群上運行。
隨著時間的推移,基于DStream Graph 不斷生成RDD Graph ,也即DAG的方式生成job,并通過Job Scheduler的線程池的方式提交給spark cluster不斷的執行。
由上可知,RDD 與 DStream的關系如下
RDD是物理級別的,而 DStream 是邏輯級別的
DStream是RDD的封裝類,是RDD進一步的抽象
DStream 是RDD的模板。DStream要依賴RDD進行具體的數據計算
注意:縱軸維度需要RDD,DAG的生成模板,需要TimeLine的job控制器
橫軸維度(時間維度)包含batch interval,窗口長度,窗口滑動時間等。
3,Spark Streaming源碼解析
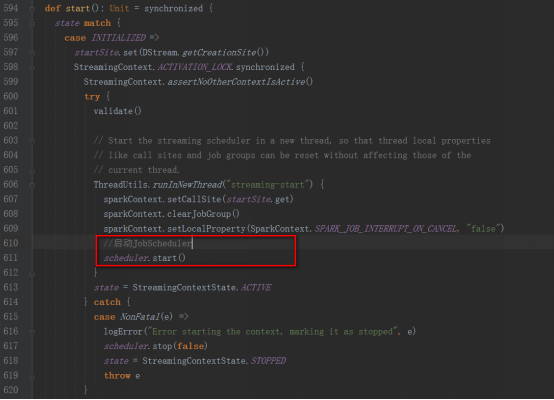
StreamingContext方法中調用JobScheduler的start方法
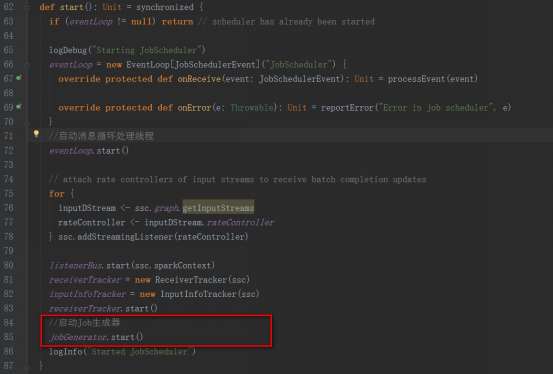
JobGenerator的start方法中,調用startFirstTime方法,來開啟定時生成Job的定時器
startFirstTime方法,首先調用DStreamGraph的start方法,然后再調用RecurringTimer的start方法。
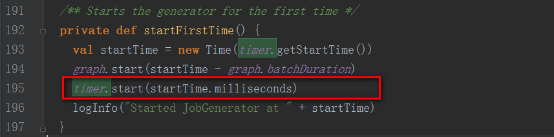
timer對象為一個定時器,根據batchInterval時間間隔定期向EventLoop發送GenerateJobs的消息。

接收到GenerateJobs消息后,會回調generateJobs方法。
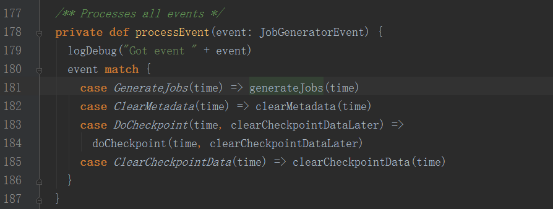
generateJobs方法再調用DStreamGraph的generateJobs方法生成Job
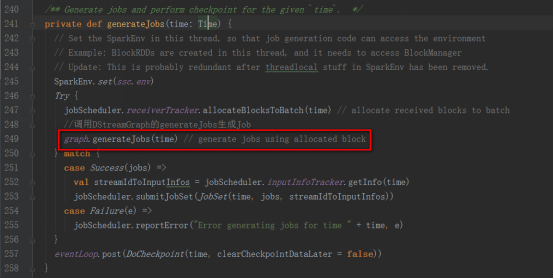
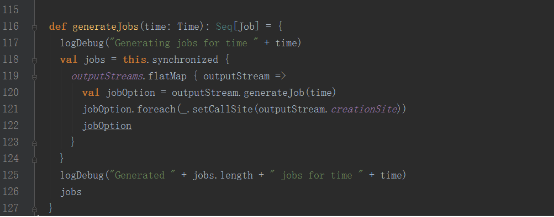
DStreamGraph的generateJobs方法
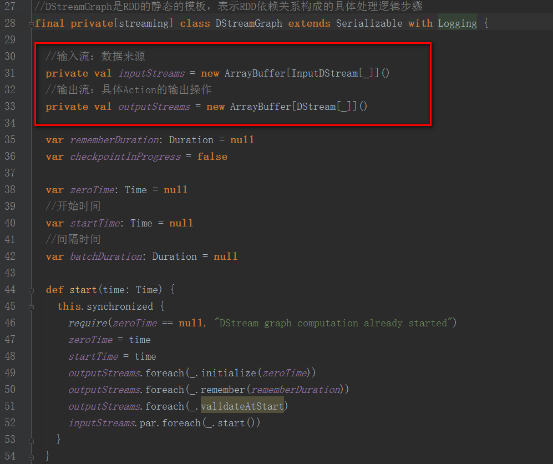
DStreamGraph的實例化是在StreamingContext中的

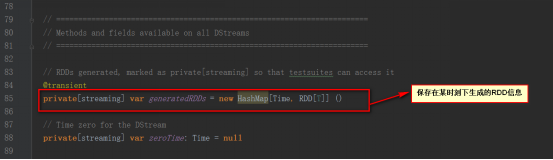
DStreamGraph類中保存了輸入流和輸出流信息
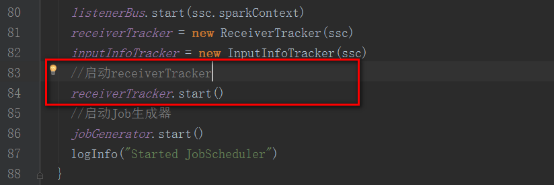
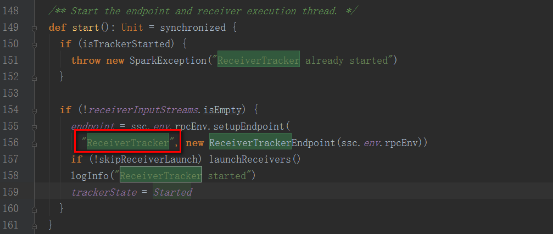
回到JobGenerator的start方法中receiverTracker.start()
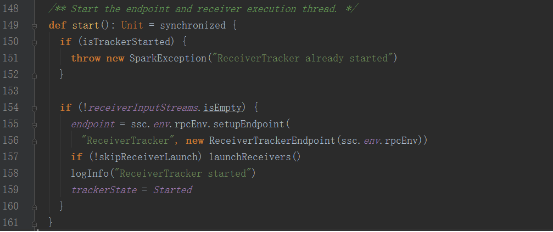
其中ReceiverTrackerEndpoint對象為一個消息循環體
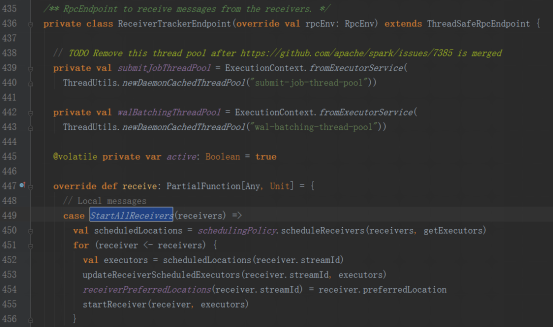
launchReceivers方法中發送StartAllReceivers消息
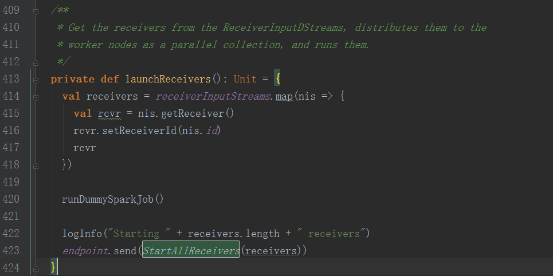
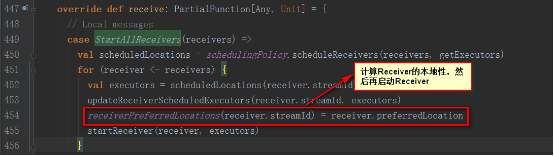
接收到StartAllReceivers消息后,進行如下處理
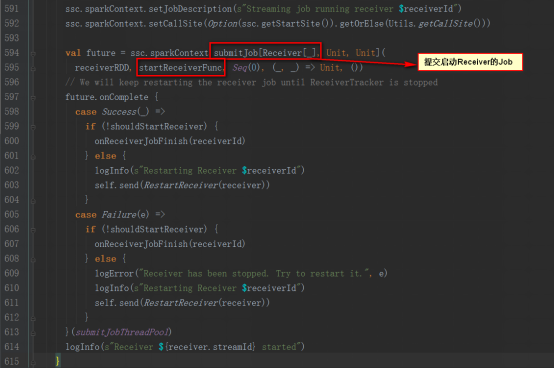
StartReceiverFunc方法如下,實例化Receiver監控者,開啟并等待退出
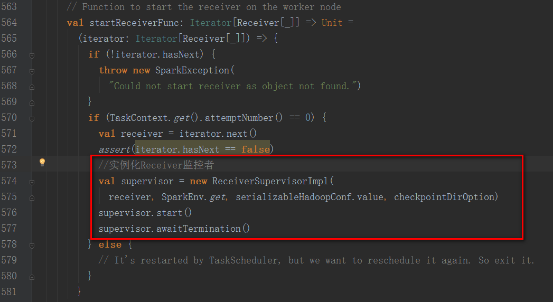
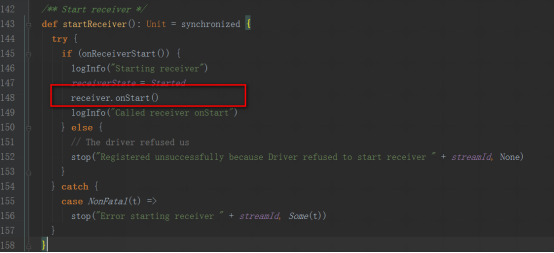
supervisor的start方法中調用startReceiver方法

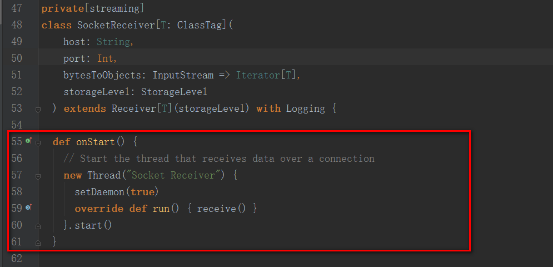
我們以socketTextStream為例,其啟動的是SocketReceiver,內部開啟一個線程,來接收數據。
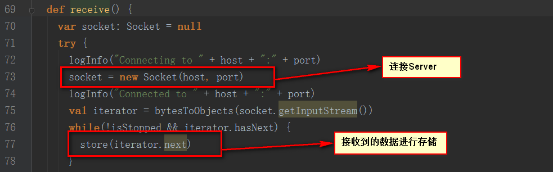
內部調用supervisor的pushSingle方法,將數據聚集后存放在內存中
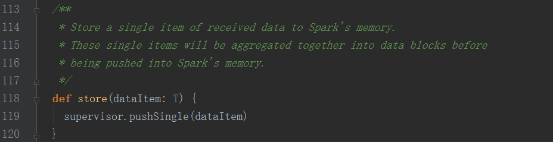
supervisor的pushSingle方法如下,將數據放入到defaultBlockGenerator中,defaultBlockGenerator為BlockGenerator,保存Socket接收到的數據

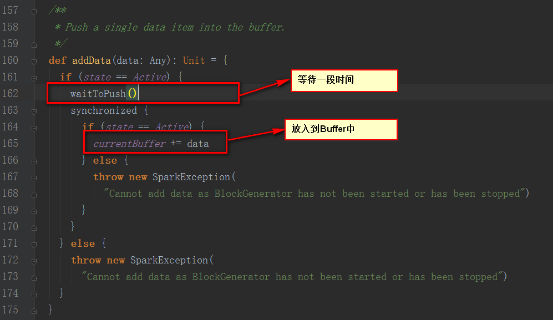
BlockGenerator對象中有一個定時器,來更新當前的Buffer


BlockGenerator對象中有一個線程,來從阻塞隊列中取出數據

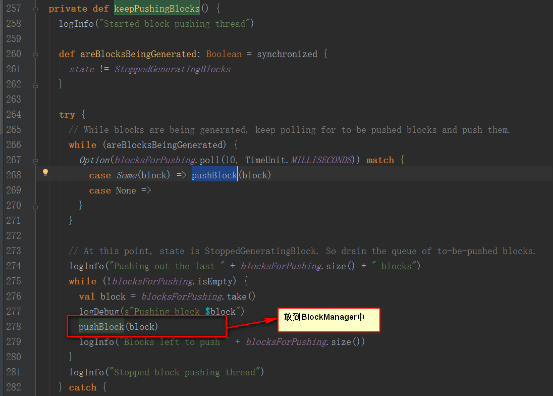

調用ReceiverSupervisorImpl類中的繼承BlockGeneratorListener的匿名類中的onPushBlock方法。
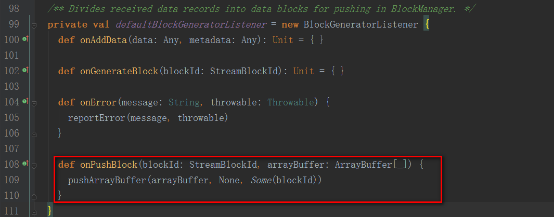
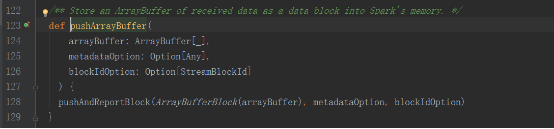
receivedBlockHandler對象如下
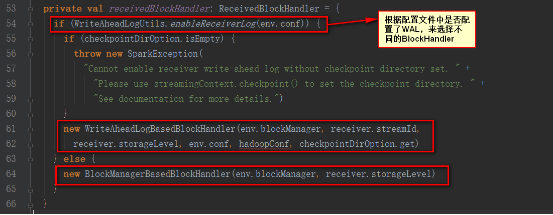
這里我們講解BlockManagerBasedBlockHandler的方式
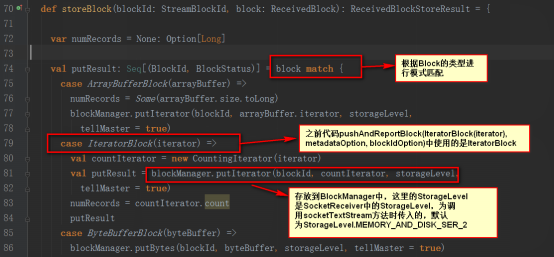
trackerEndpoint如下

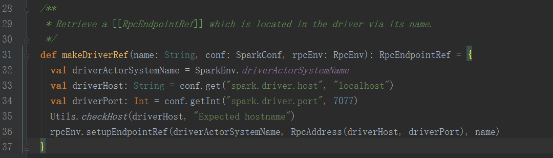
其實是發送給ReceiverTrackerEndpoint類,
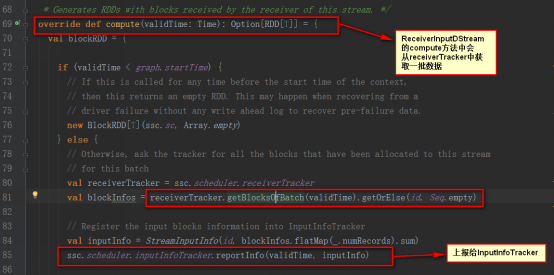
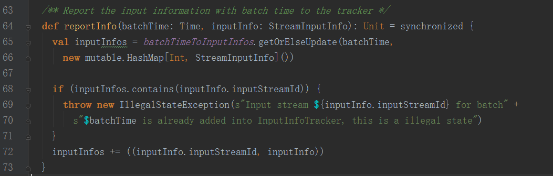
InputInfoTracker類的reportInfo方法只是對數據進行記錄統計
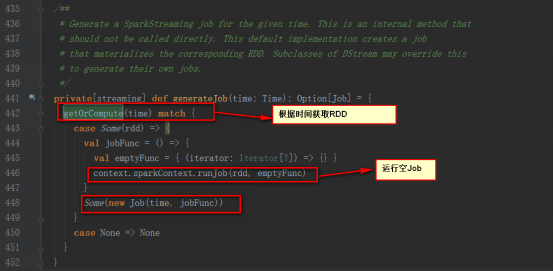
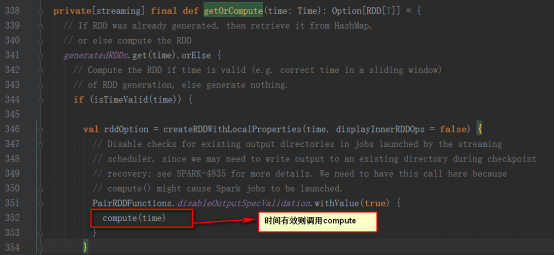
其generateJob方法是被DStreamGraph調用
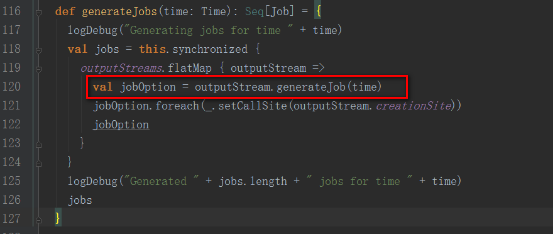
DStreamGraph的generateJobs方法是被JobGenerator類的generateJobs方法調用。
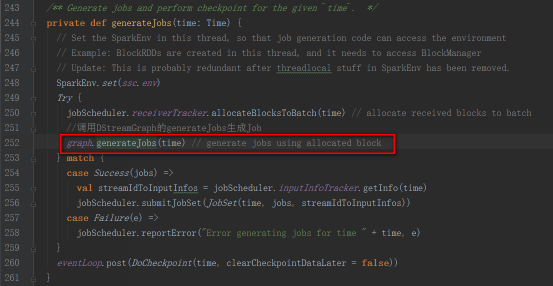
JobGenerator類中有一個定時器,batchInterval發送GenerateJobs消息

總結:
1,當調用StreamingContext的start方法時,啟動了JobScheduler
2,當JobScheduler啟動后會先后啟動ReceiverTracker和JobGenerator
3,ReceiverTracker啟動后會創建ReceiverTrackerEndpoint這個消息循環體,來接收運行在Executor上的Receiver發送過來的消息
4,ReceiverTracker在啟動時會給自己發送StartAllReceivers消息,自己接收到消息后,向Spark提交startReceiverFunc的Job
5,startReceiverFunc方法中在Executor上啟動Receiver,并實例化ReceiverSupervisorImpl對象,來監控Receiver的運行
6,ReceiverSupervisorImpl對象會調用Receiver的onStart方法,我們以SocketReceiver為例,啟動一個線程,連接Server,讀取網絡數據先調用ReceiverSupervisorImpl的pushSingle方法,
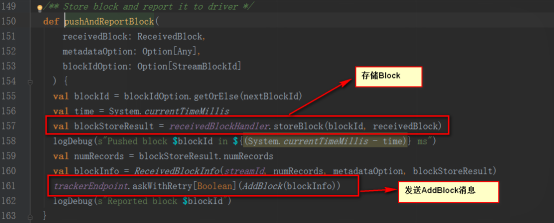
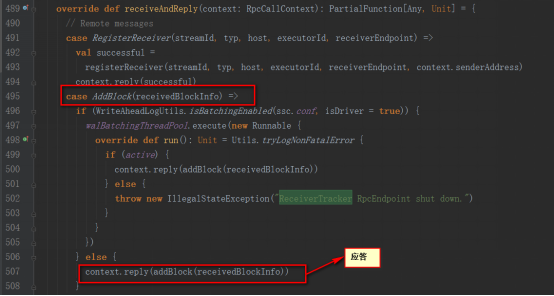
保存在BlockGenerator對象中,該對象內部有個定時器,放到阻塞隊列blocksForPushing,等待內部線程取出數據放到BlockManager中,并發AddBlock消息給ReceiverTrackerEndpoint。
ReceiverTrackerEndpoint為ReceiverTracker的內部類,在接收到addBlock消息后將streamId對應的數據阻塞隊列streamIdToUnallocatedBlockQueues中
7,JobGenerator啟動后會啟動以batchInterval時間間隔發送GenerateJobs消息的定時器
8,接收到GenerateJobs消息會先后觸發ReceiverTracker的allocateBlocksToBatch方法和DStreamGraph的generateJobs方法
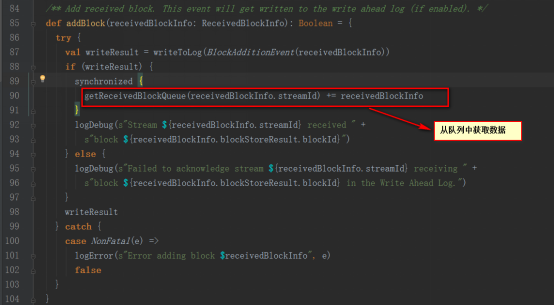
9,ReceiverTracker的allocateBlocksToBatch方法會調用getReceivedBlockQueue方法從阻塞隊列streamIdToUnallocatedBlockQueues中根據streamId獲取數據
10,DStreamGraph的generateJobs方法,繼而調用變量名為outputStreams的DStream集合的generateJob方法
11,繼而調用DStream的getOrCompute來調用具體的DStream的compute方法,我們以ReceiverInputDStream為例,compute方法是從ReceiverTracker中獲取數據
到此,關于“Spark Streaming怎么使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





