溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
從storm到spark streaming,再到flink,流式計算得到長足發展, 依托于spark平臺的spark streaming走出了一條自己的路,其借鑒了spark批處理架構,通過批處理方式實現了實時處理框架。為進一步了解spark streaming的相關內容,飛馬網于3月20日晚邀請到歷任百度大數據的高級工程師—王富平,在線上直播中,王老師針對spark streaming高級特性以及ndcg計算實踐進行了分享。

以下是本次直播的主要內容:
一.Spark Streaming簡介
1.spark是什么?
spark就是一個批處理框架,它具有高性能、生態豐富的優勢。
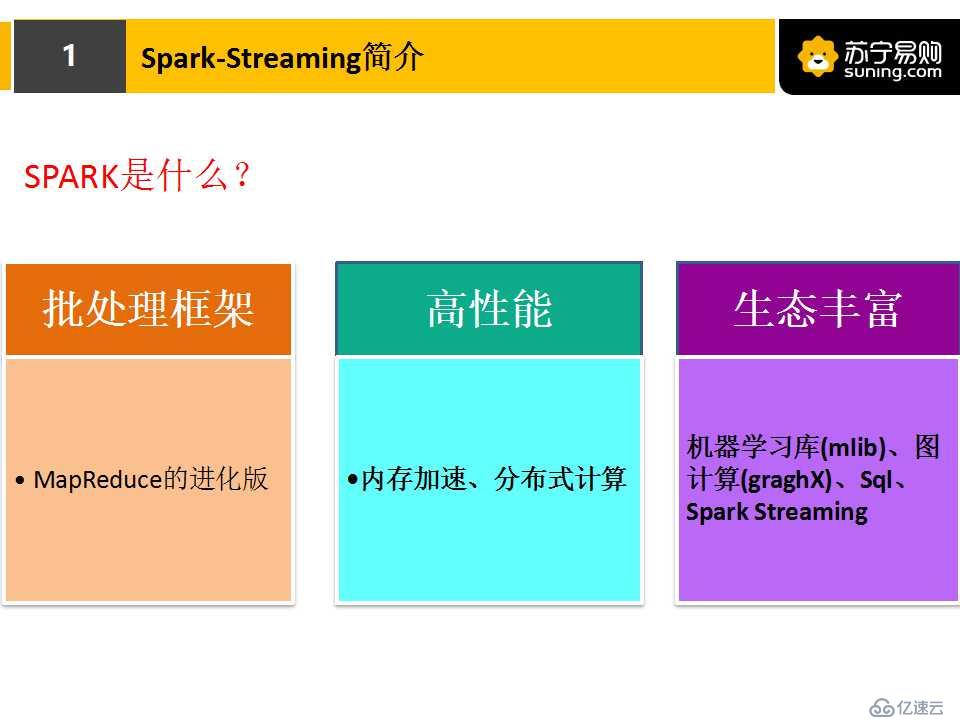
在沒有spark之前,我們是怎么做大數據分析的呢?其實在沒有spark之前,我們用的是基于Hadoop的MapReduce框架來做數據分析。時至今日,傳統的MapReduce任務并沒有完全退出市場,在一些數據量非常大的場景下,MapReduce表現地還是相當穩定的。
2.spark streaming是什么?
spark streaming是按時間對數據進行分批處理的框架,.spark平臺帶來的優勢,使得spark streaming開發簡單、廣泛使用。

spark streaming的實現方式是基于spark的批處理理念,因此它可以直接使用spark平臺提供的工具組件。
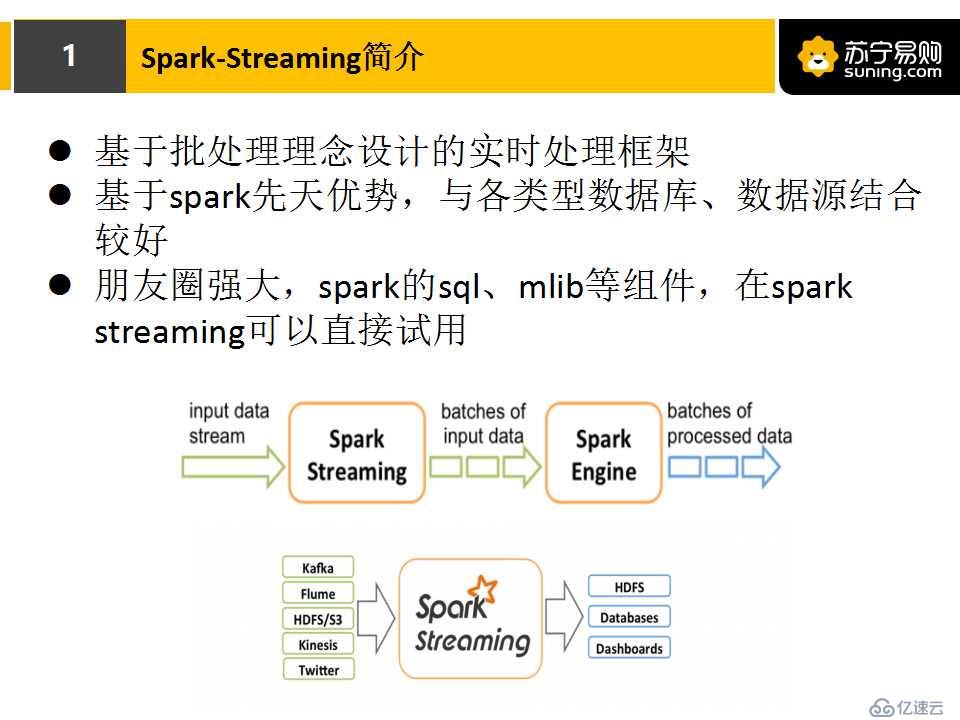
通過上面這張圖,我們可以把spark streaming的輸入當成一個數據流,通過時間將數據進行分批處理,分批時間根據我們自己的業務情況而定。
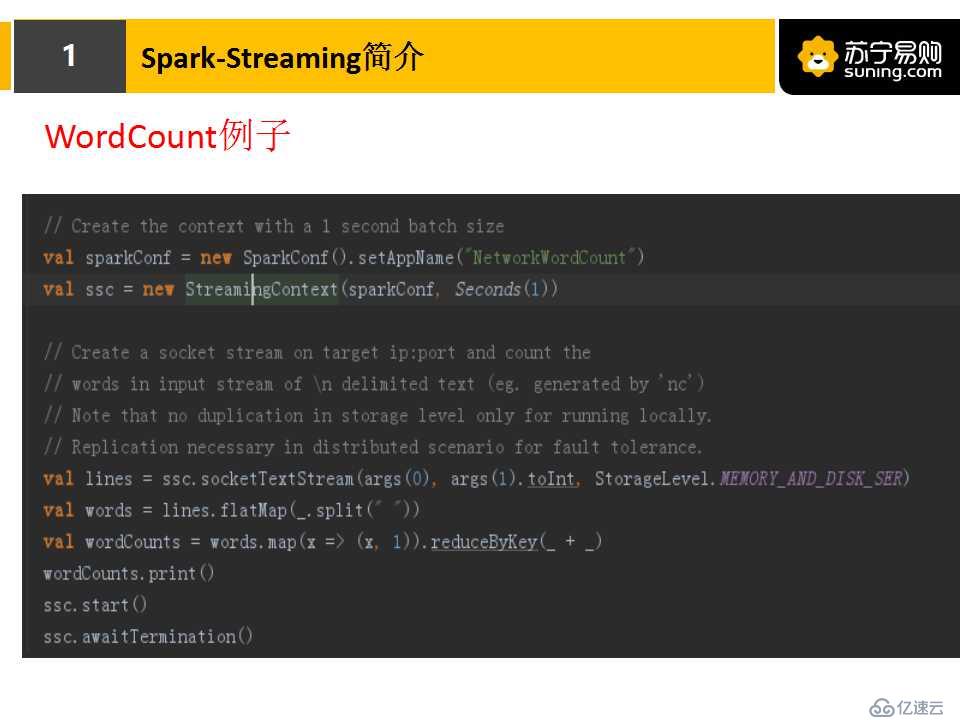
3.WordCount的例子:
下面舉一個WordCount的例子,我們可以看到,短短幾行代碼,就實現了一個WordCount。由于spark平臺與Hadoop是直接打通的,我們可以很方便地把數據保存到HDFS或數據庫里,只需要運維一套spark平臺,我們就可以既做實時任務,又做離線分析任務,比較方便。
二.Spark Streaming的高級特性
1.Window特性:

基于上面簡單的WordCount例子,我們升級一下,假設我們需要每十秒鐘統計一次單詞在前一分鐘內出現次數,這個需求不是簡單的WordCount能夠實現的,這時候,我們就要使用到spark streaming提供的Window機制。
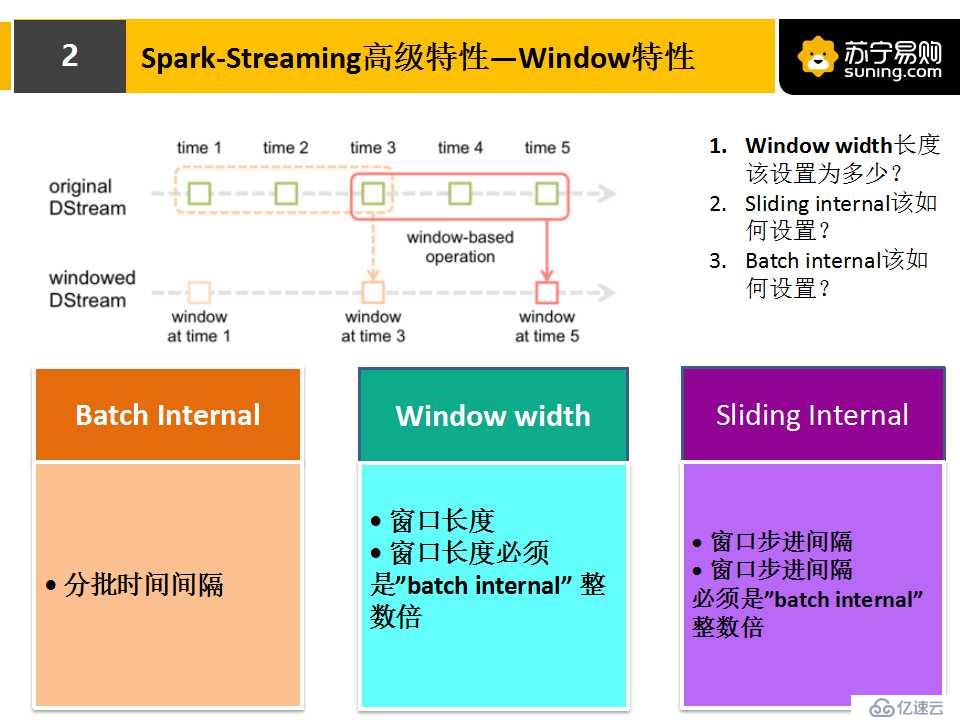
關于spark streaming的Window特性,有三個參數需要注意:Batch Internal(分批時間間隔)、Window width(窗口長度)、Sliding Internal(窗口滑動間隔)。根據剛才的需求,窗口長度是60s,窗口滑動間隔是10s,分批時間間隔是1s,這里需要注意,分批時間間隔必須能被窗口長度和窗口滑動間隔整除。
通過講述,或許你感覺Window特性有些復雜,但實際上,創建一個窗口的流是非常簡單的,下面的兩張圖,是關于創建Window數據流和Window相關計算函數的,可以簡單了解下。

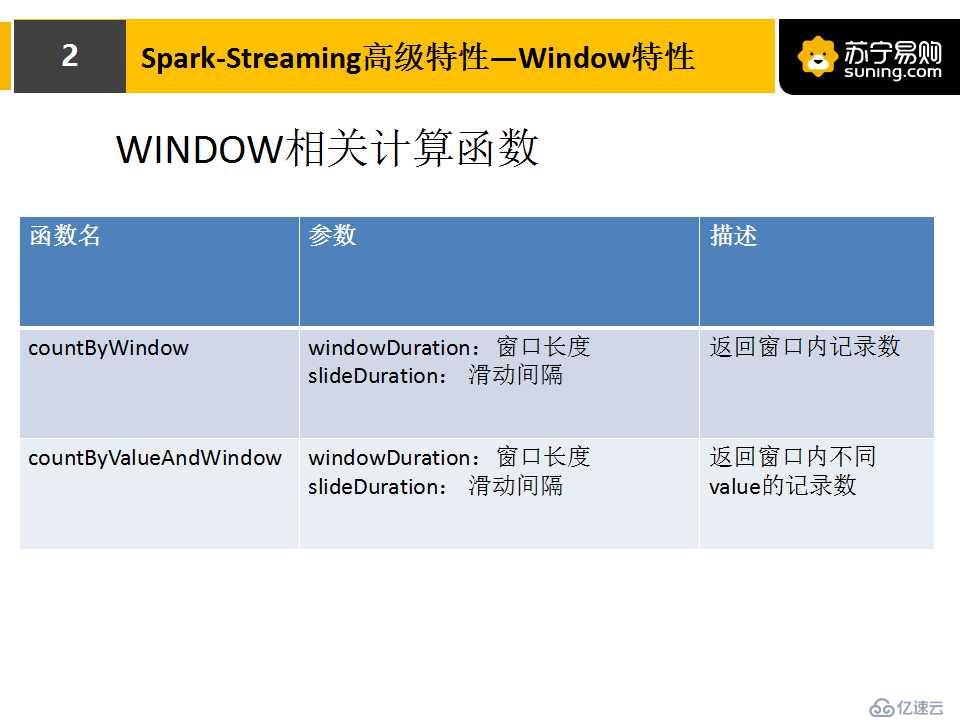
下面這張圖片是計算30s窗口期內的請求失敗率。我們看一下它的參數,窗口時間設置為30s,滑動間隔是2s。整個代碼非常簡單,只需要多加一行代碼,就能實現窗口流,之后這個流就能做一些正常計算。
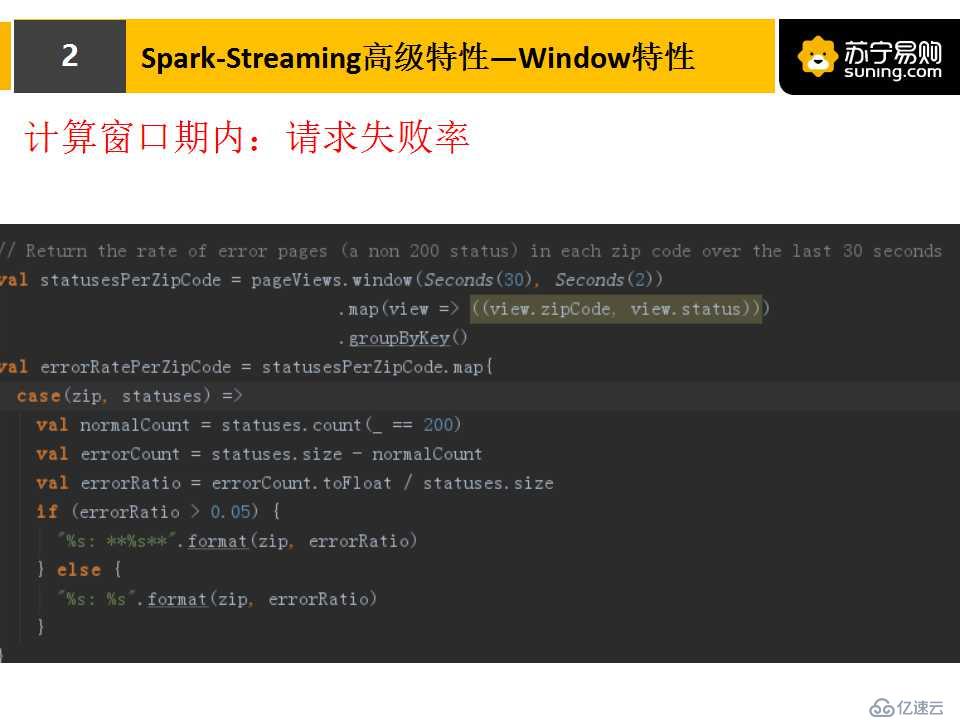
我們簡單讀一下這個函數,首先創建一個窗口流,之后在任務里面計算失敗的條數,用它來除以總條數,就得到請求失敗率。
2.Sql特性:
spark streaming的第二個特性就是Sql特性,spark streaming把數據封裝成DataFrame之后,天然就可以使用spark sql特性。

想完整使用寫sql的方式,我們首先要注冊臨時表。我們注冊的臨時表還可以與我們建的多張臨時表做join關聯,比較實用。
使用sql,自定義函數會給我們帶來很多擴展性,定義UDF有兩種方式:加載jar包UDF和動態定義UDF。

4.CheckPoint機制:
Spark通過使用CheckPoint保存處理狀態甚至當前處理數據,一旦任務失敗后,可以利用CheckPoint對數據進行恢復。我們做數據處理,數據可靠性是很重要的,必須保證數據不丟失,Spark的CheckPoint機制就是幫助我們保障數據安全的。
CheckPoint機制主要有兩種:

那么怎么去實現CheckPoint機制呢?
有以下三個條件:
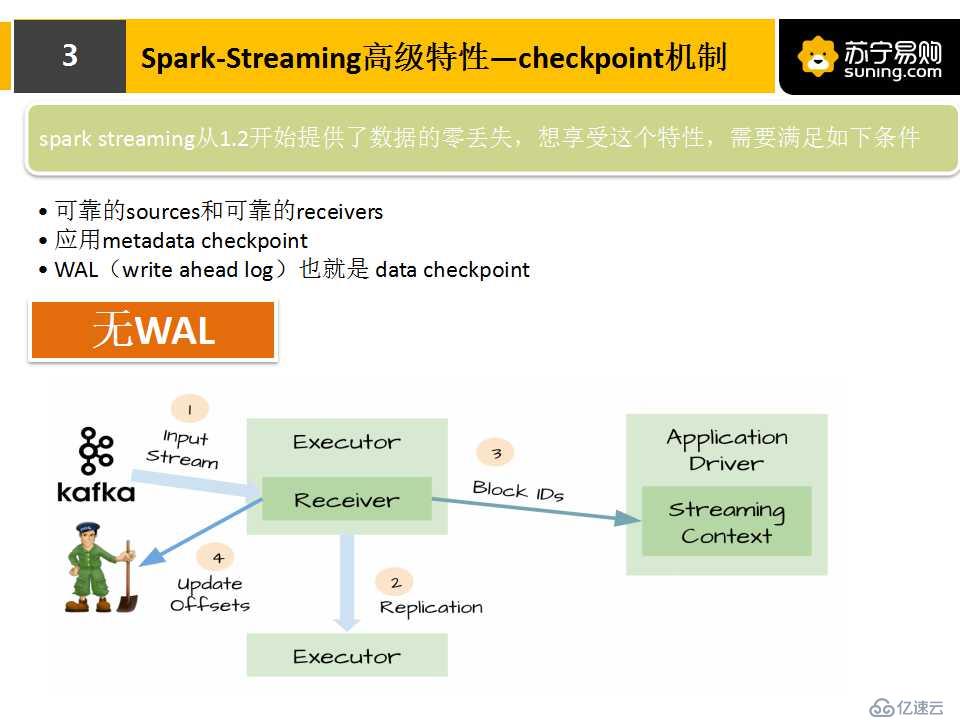
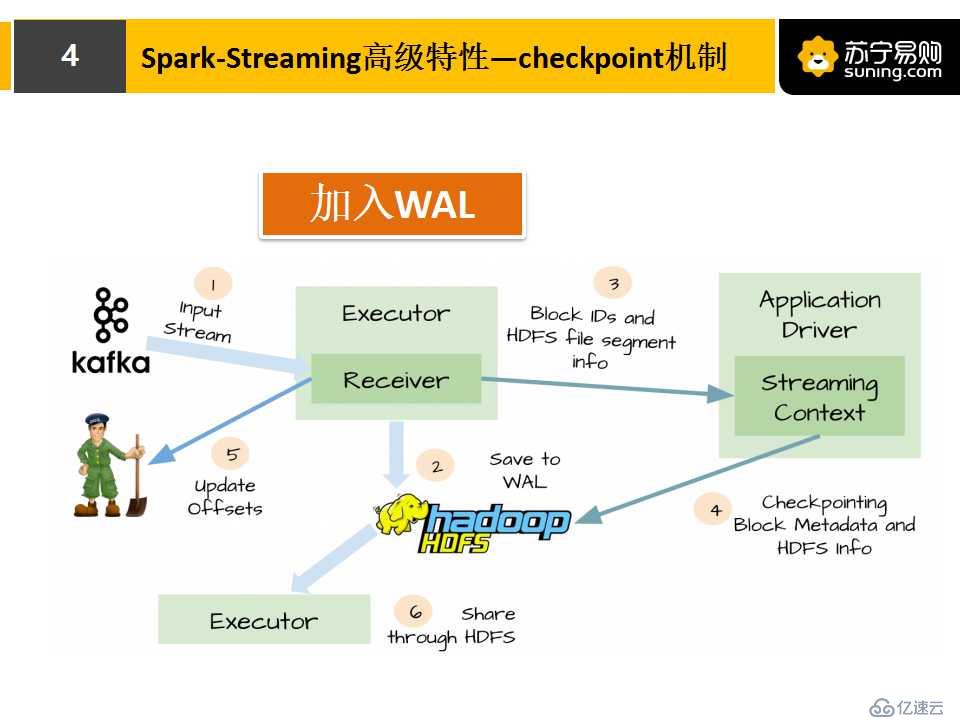
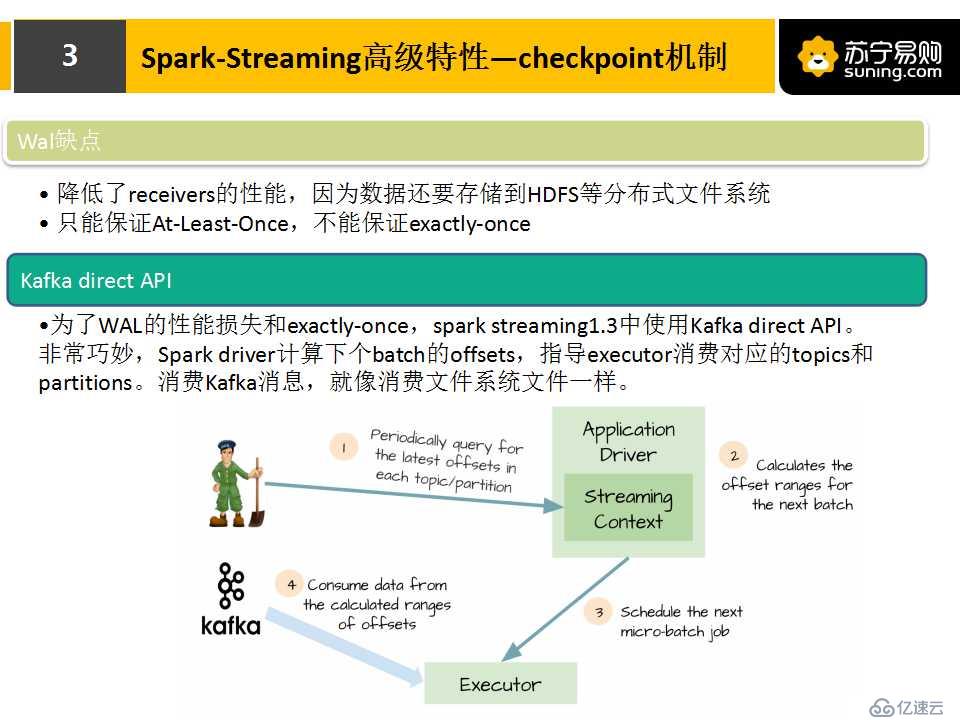
我們來對比一下有WAL和無WAL的兩張圖。實際上有WAL,它首先會把數據先存到HDFS,然后對任務邏輯進行備份,再去執行處理,任務失敗時,它會根據CheckPoint的數據,去讀HDFS保存的數據,進行任務恢復。但實際上,這樣會有缺點,一方面是降低了receivers的性能,另一方面它只能保證At-Least-Once,不能保證exactly-once。
針對WAL的缺點,spark streaming對kafka進行優化,提供了Kafka direct API,性能大大提升。
三.NDCG指標計算
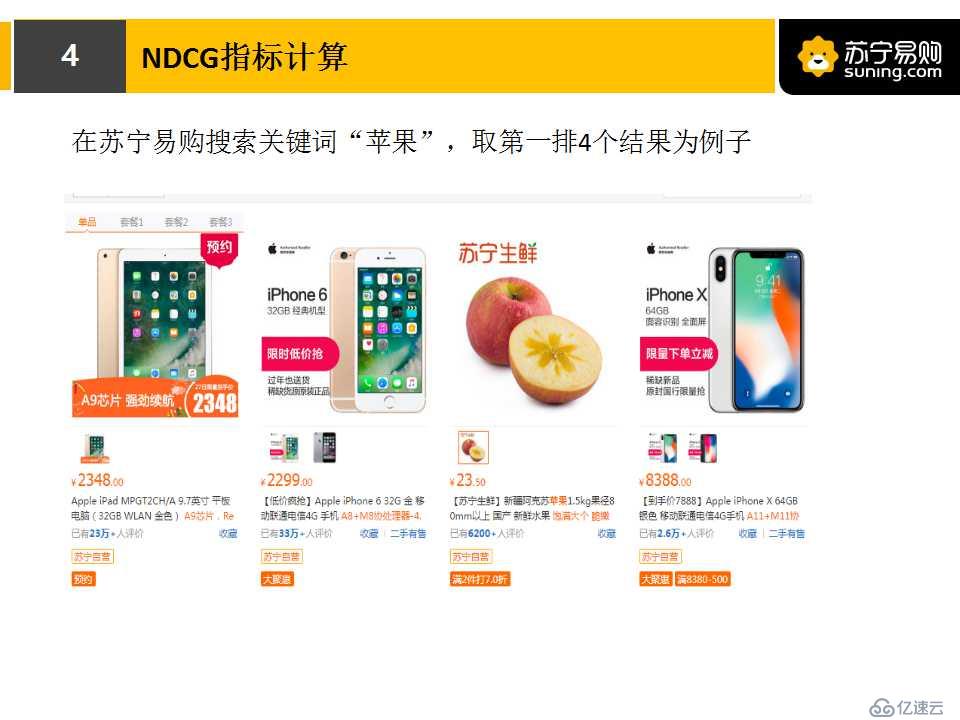
1.NDCG是什么?

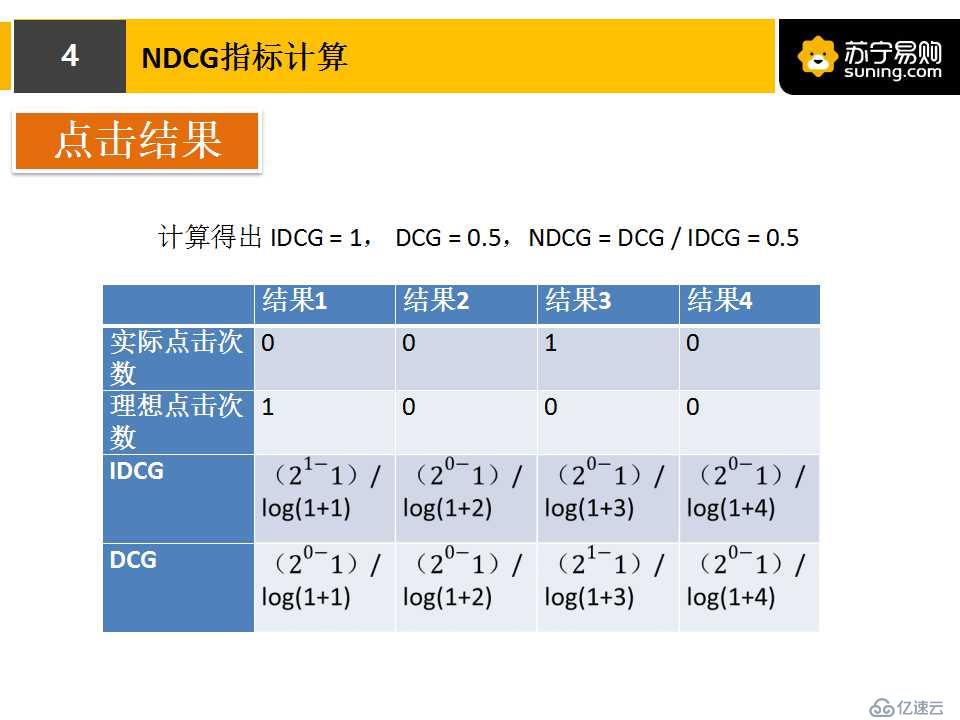
下面兩張圖片,是NDCG計算的具體例子。
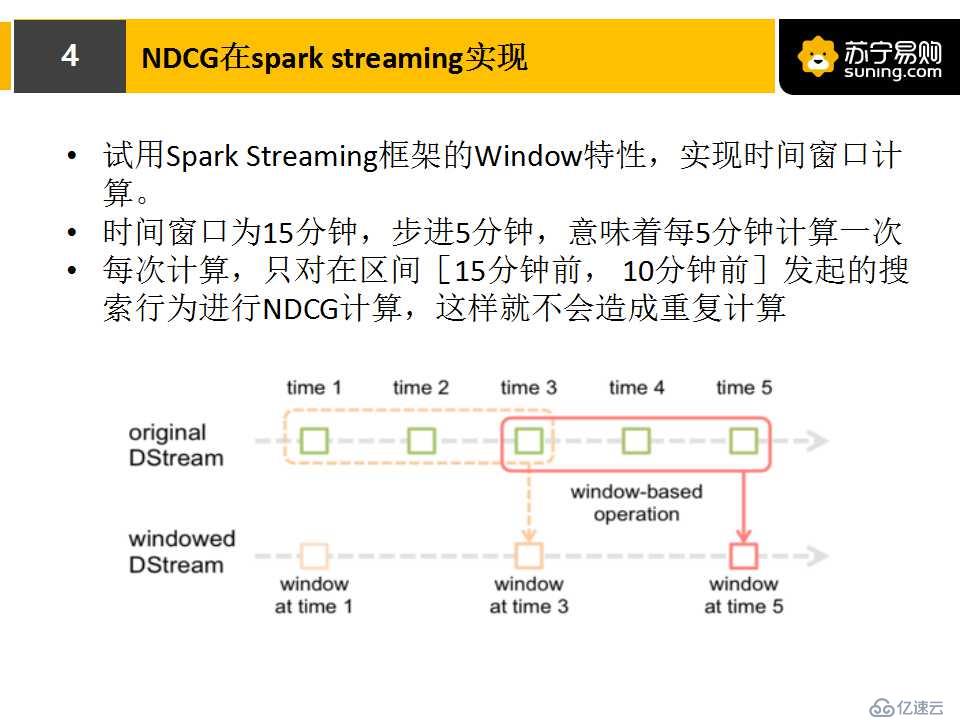
2.NDCG在spark streaming實現:
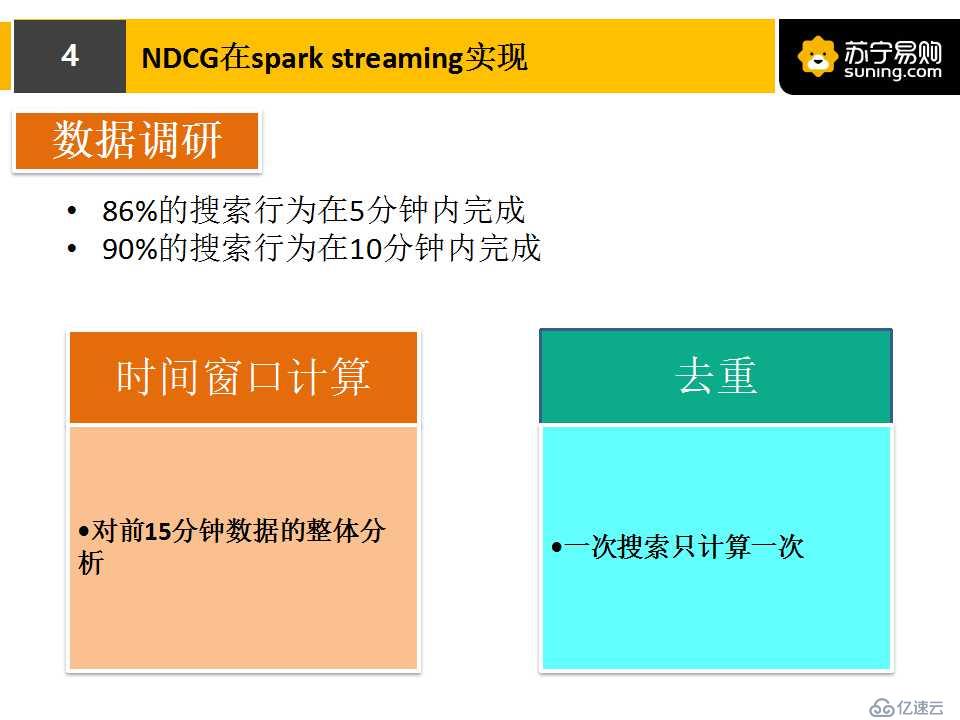
我們如何用spark streaming實現NDCG計算呢?首先我們做了一個數據調研。
開始進行NDCG計算。
3.NDCG性能保障:
我們開發一個數據任務,不是靜態工作,要保障數據的穩定性,根據數據的情況,做一個容量預估,以保證數據的性能。容量預估是一個必不可少的步驟。

我們最常見的容量調節。

在NDCG指標計算過程中,我們還會遇到一些問題,就是NDCG支持四個維度的組合計算,維度組合較多、較復雜。

這時候,多維分析就要借助于我們的OLAP引擎,目前我們使用的是Druid。

以上三大部分,就是這次線上直播分享的主要內容,在最后,王老師還針對大家提出的問題進行了一一解答,都有些什么問題呢?我們一起來看一下。
1.每間隔5s讀一批數據,需要遍歷每天數據進行各種計算分析,計算的結果還需要緩存作為下一次計算的參考,怎么實現?
王老師:這是一個實時任務,需要存儲狀態數據的話,有幾種實現方式,第一個是spark streaming有保存狀態數據的機制,第二種方式是,你可以把狀態數據保存在一些KV數據庫里,比如說spark等,也可以通過這種方式自己實現,不管哪條路,關鍵在于怎么實現。
2.學spark有推薦的上船方式么?
王老師:大家不要把spark看得那么神奇,java8里面提供的stream處理方式相關知識,和寫spark沒有多大區別,原理都是一樣的,你理解了java8怎么寫、stream處理的各種方法和計算邏輯,那么你就能理解spark streaming里的各種計算邏輯,spark streaming唯一高大上的就是它做的分布式。
3. spark streaming 將來最有可能被什么技術取代?
王老師:每個平臺都有各自的優缺點,目前來看,雖然Flink比較火,但是Storm依然存在,Spark也有自己所適合的場景,Flink也有它本身先進的機制,所以說,各有優勢。
最后,王老師向大家推薦了關于scala最經典的一本書—《programming in scala》,本次針對 spark streaming的直播內容簡明且有針對性,相信你一定收獲頗多。想了解更多更詳細內容的小伙伴們,可以關注服務號:FMI飛馬網,點擊菜單欄飛馬直播,即可進行學習。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





