溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何分析KEGG Brite數據庫,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
KEGG被稱為京都基因組百科全書,是一個綜合性的數據庫。對于如此龐大的數據庫,肯定需要對數據進行分門別類的整理。除了將各種數據拆分到不同的子數據庫中之外,KEGG還對所有的數據進行了更加細致的功能分類,這些功能分類的信息就存儲在brite 數據庫中。
birte 主要包含以下五大類別的分類信息:
genes and protein
compounds and reactions
drugs
diseases
organisms and cells
在brite數據庫中,以文件的形式存儲分類信息。包含兩種格式的文件:
table 格式,比如對藥物的分類
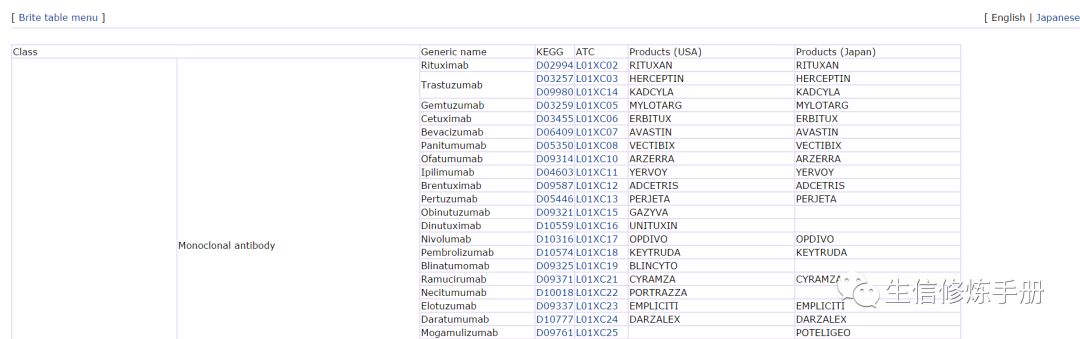
htext 文件,比如kegg orthology 的分類
http://www.kegg.jp/kegg-bin/get_htext?ko00000.keg
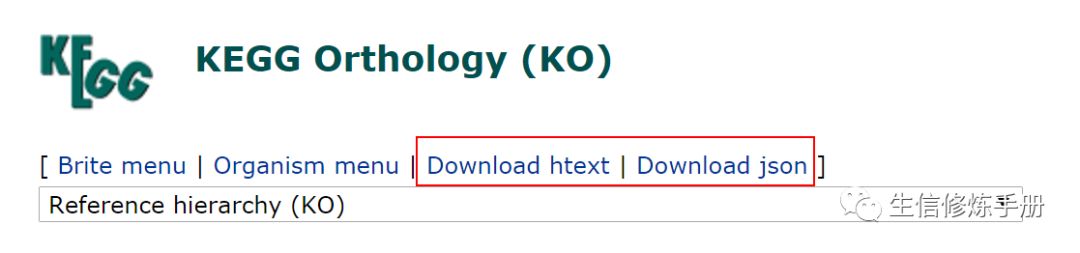
提供了兩種格式的文件用于下載,htext 對應的后綴為 keg, json 對應json。
json 格式是網絡數據傳說的新標準,主要用于程序解析;`keg 文件是純文本文件,可以用文本編輯器打開。
以所有ko的分類文件 ko00000.keg 文件為例:
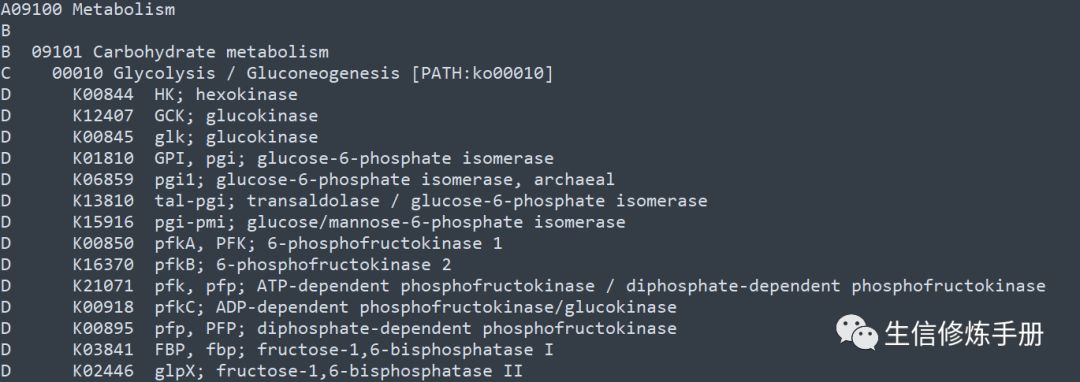
分類層級按照字母順序排列,示例文件中A 為第一級分類,B, C, D 依次為第二級。
我們可以直觀的看到 K00844 屬于Glycolysis / Gluconeogenesis 這個分類,對應的更上一級的分類為Carbohydrate metabolism,再上一級為 Metabolism。
keg 文件格式還是非常容易理解的,但是使用起來不夠直觀,當我們想要查詢某個KO的具體分類時,如果和這個KO處于同一分類的節點太多時,需要往上翻閱很多行,才能找到對應的分類;有時一不小心就翻過了,就會搞錯。
當然可以通過程序格式化這個文件,比如將這個文件變成如下的格式:
| KO | Name | C | B | A |
|---|---|---|---|---|
| K00844 | HK… | Glycolysis… | Carbo..bolism | Metabolism |
這樣方便查看條目的詳細分類信息;
對于沒有編程基礎的人來說,kegg 提供了keggHier 程序,專門用于查看brite中的分類信息。軟件是用java 開發的,提供了圖形界面,簡單易用;
下載地址 :
http://www.kegg.jp/kegg/download/kegtools.html
使用方法
雙加批處理文件啟動
從菜單欄點擊File按鈕,選擇導入kegg網站上的數據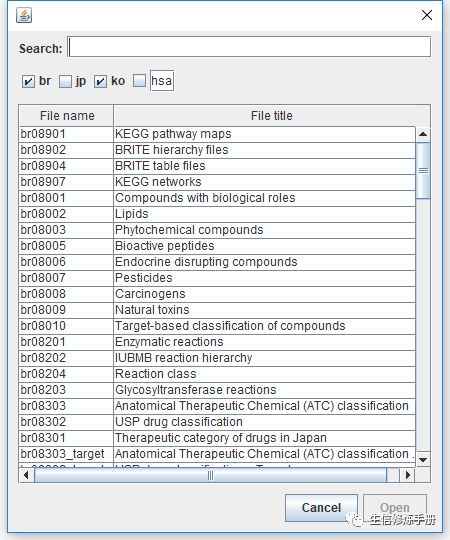
這里選擇第一個kegg pathway map 的分類結構,進行查看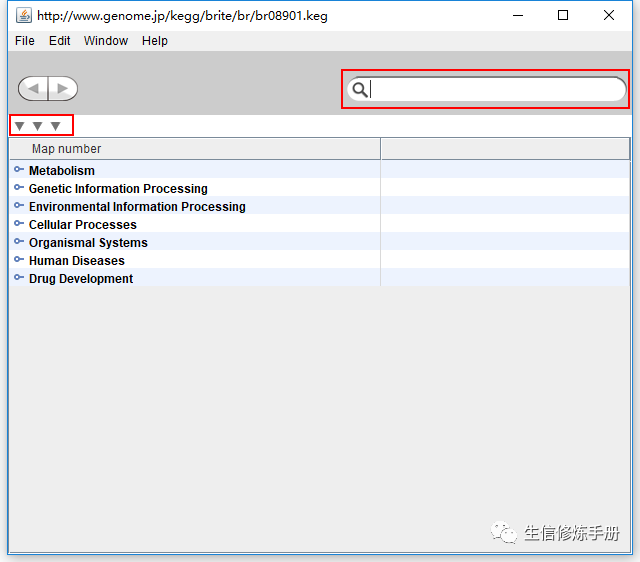
向下的三角形表示展開的意思,這里有3個,說明pathway 共有3層分類,鼠標可以點擊任意一條記錄,可以展開詳細信息;
右上角的搜索框可以搜索,通過搜索框可以快速查找你感興趣的記錄
brite 是存儲分類信息的數據庫,提供了包含pathway, ko, module, drug, disease,organism 等所有記錄的分類;
分類信息通過文件進行距離,有keg 和table兩種格式;
通過KEGGHier工具,可以方便的瀏覽 KEGG 分類系統;
看完上述內容,你們掌握如何分析KEGG Brite數據庫的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





