溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了機算法原理及Python實現實例分析的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇機算法原理及Python實現實例分析文章都會有所收獲,下面我們一起來看看吧。
機器學習強基計劃聚焦深度和廣度,加深對機器學習模型的理解與應用。“深”在詳細推導算法模型背后的數學原理;“廣”在分析多個機器學習模型:決策樹、支持向量機、貝葉斯與馬爾科夫決策、強化學習等。
本期目標:實現這樣一個效果
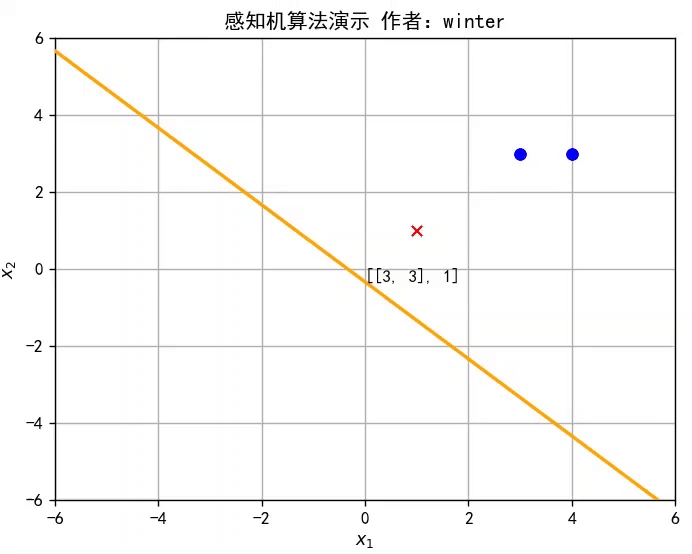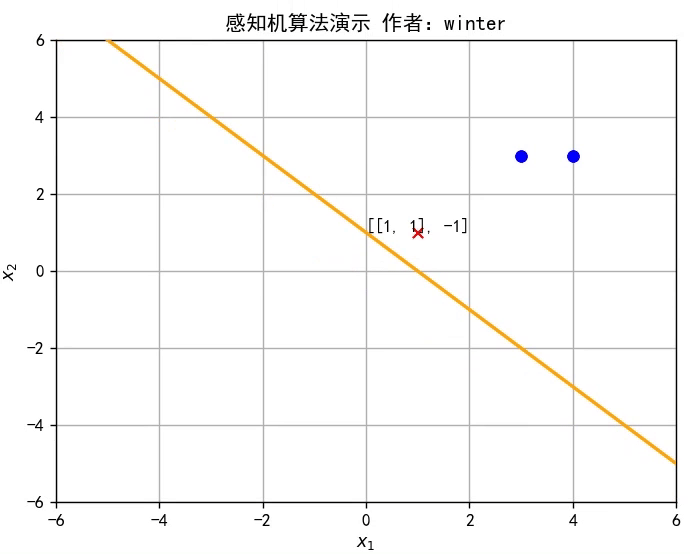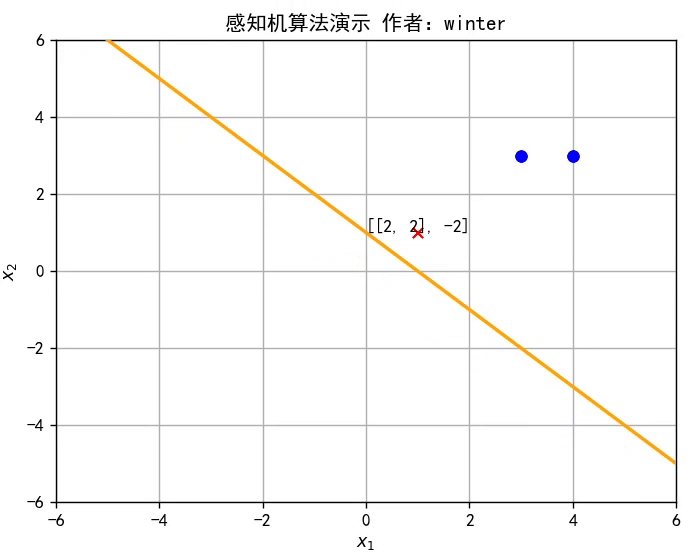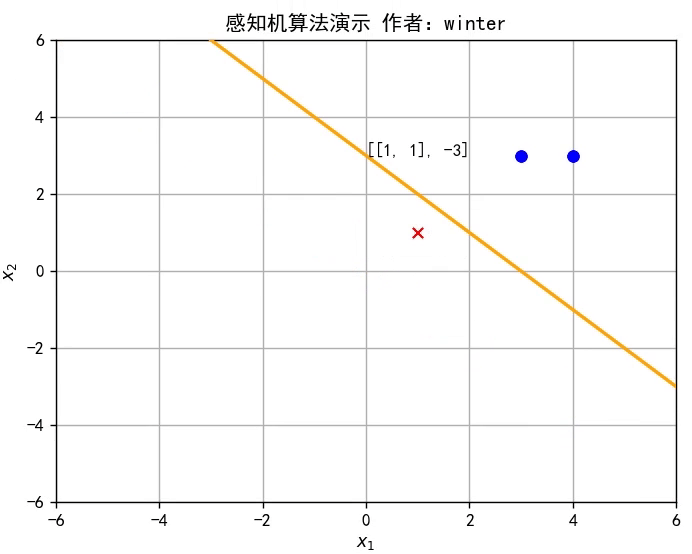
線性模型的假設形式是屬性權重、偏置與屬性的線性組合,即

稱為廣義線性模型(generalized linear model),其中g(⋅)稱為聯系函數(link function)。
廣義線性模型本質上仍是線性的,但通過g(⋅)進行非線性映射,使之具有更強的擬合能力,類似神經元的激活函數。例如對數線性回歸(log-linear regression)是g(⋅)=ln(⋅)時的情形,此時模型擁有了指數逼近的性質。
線性模型的優點是形式簡單、易于建模、可解釋性強,是更復雜非線性模型的基礎。
感知機(Perceptron)是最簡單的二分類線性模型,也是神經網絡的起源算法,如圖所示。
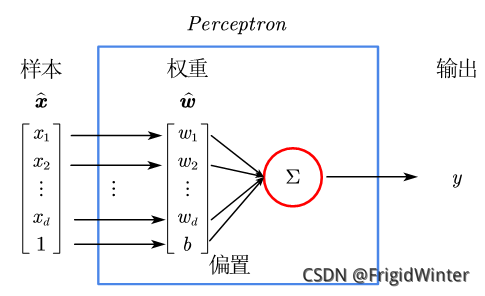
y=w^Tx^是 Rd空間的一條直線,因此感知機實質上是通過訓練參數w^改變直線位置,直至將訓練集分類完全,如圖所示,或者參考文章開頭的動圖。
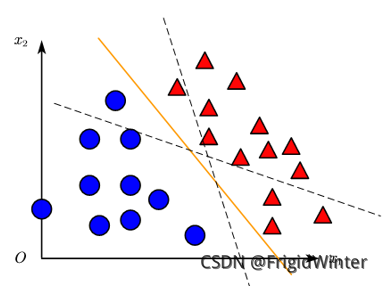
機器學習強基計劃的初衷就是搞清楚每個算法、每個模型的數學原理,讓我們開始吧!
感知機的損失函數定義為全體誤分類點到感知機切割超平面的距離之和:
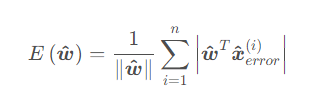
對于二分類問題y∈{−1,1},則誤分類點的判斷方法為
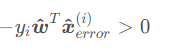

這在二分類問題中是個很常用的技巧,后面還會遇到這種等效形式。
從而損失函數也可簡化為下面的形式以便于求導:
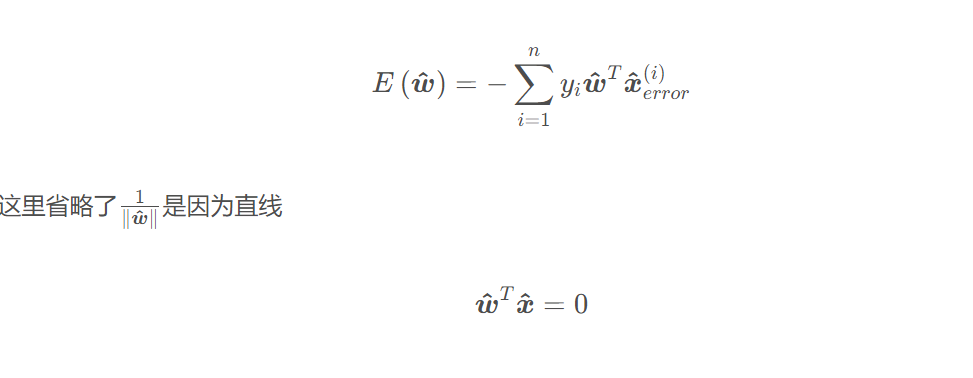
方程兩邊同時乘以系數都成立,所以直線系數 w^可以隨意縮放,這里可令|w^|=1
若采用梯度下降法進行優化(梯度法可參考圖文詳解梯度下降算法的原理及Python實現),則算法流程為:

class Perceptron: def __init__(self): self.w = np.mat([0,0]) # 初始化權重 self.b = 0 # 初始化偏置 self.delta = 1 # 設置學習率為1 self.train_set = [[np.mat([3, 3]), 1], [np.mat([4, 3]), 1], [np.mat([1, 1]), -1]] # 設置訓練集 self.history = [] # 訓練歷史
def update(self,error_point): self.w += self.delta*error_point[1]*error_point[0] self.b += self.delta*error_point[1] self.history.append([self.w.tolist()[0],self.b])
def judge(self,point): return point[1]*(self.w*point[0].T+self.b)
def train(self): flag = True while(flag): count = 0 for point in self.train_set: if(self.judge(point)<=0): self.update(point) else: count += 1 if(count == len(self.train_set)): flag = False
def show():
print("參數w,b更新過程:",perceptron.history)
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(perceptron.history),
interval=1000, repeat=False,blit=True)
plt.show()
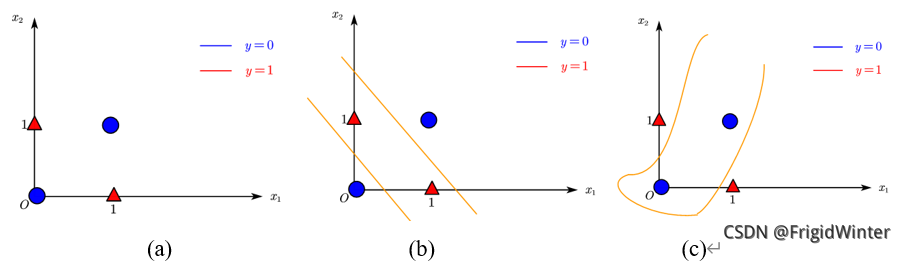
感知機最大的缺陷在于其線性,單個感知機只能表達一條直線,即使是如圖(a)所示簡單的異或門樣本,都無法進行分類。對此有兩種解決方式:
通過多條直線,即多層感知機(Multi-Layer Perceptron, MLP)進行分類,如圖(b)所示;在線性加權的基礎上引入非線性變換,如圖(c)所示。
關于“機算法原理及Python實現實例分析”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“機算法原理及Python實現實例分析”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





