溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一. 概述
首先需要先介紹一下無監督學習,所謂無監督學習,就是訓練樣本中的標記信息是位置的,目標是通過對無標記訓練樣本的學習來揭示數據的內在性質以及規律。通俗得說,就是根據數據的一些內在性質,找出其內在的規律。而這一類算法,應用最為廣泛的就是“聚類”。
聚類算法可以對數據進行數據歸約,即在盡可能保證數據完整的前提下,減少數據的量級,以便后續處理。也可以對聚類數據結果直接應用或分析。
而Kmeans 算法可以說是聚類算法里面較為基礎的一種算法。
二. 從樣例開始
我們現在在二維平面上有這樣一些點
x y 1.658985 4.285136 -3.453687 3.424321 4.838138 -1.151539 -5.379713 -3.362104 0.972564 2.924086 -3.567919 1.531611 0.450614 -3.302219 -3.487105 -1.724432 2.668759 1.594842 -3.156485 3.191137 3.165506 -3.999838 -2.786837 -3.099354 4.208187 2.984927 -2.123337 2.943366 0.704199 -0.479481 -0.392370 -3.963704 2.831667 1.574018 -0.790153 3.343144 2.943496 -3.357075 ...
它在二維平面上的分布大概是這樣的:

好,這些點看起來隱約分成4個“簇”,那么我們可以假定它就是要分成4個“簇”。(雖然我們可以“看”出來是要分成4個“簇”,但實際上也可以分成其他個,比如說5個。)這里分成“4個簇“是我們看出來的。而在實際應用中其實應該由機器算得,下面也會有介紹的。
找出4個”簇”之后,就要找出每個“簇”的中心了,我們可以“看出”大概的中心點,但機器不知道啊。那么機器是如何知道的呢?答案是通過向量距離,也叫向量相似性。這個相似性計算有多種方法,比如歐式距離,曼哈頓距離,切比雪夫距離等等。
我們這里使用的是歐式距離,歐式距離其實就是反應空間中兩點的直線距離。
知道這些后,我們就可以開始讓機器計算出4個“簇”了。
主要做法是這樣,先隨機生成4個點,假設這4個點就是4個“簇”的中心。計算平面中每個點到4個中心點的距離,平面中每個點選取距離最近的那個中心作為自己的中心。
此時我們就完成第一步,將平面中所有點分成4個”簇“。但是剛剛那幾個中心都是隨機的,這樣分成的4個簇明顯不是我們想要的結果。怎么辦呢?做法如下:
現在有4個簇,根據每個簇中所有點計算出每個簇的新中心點。這個新中心點就會比上一個舊的中心點更優,因為它更加中心。然后使用新中心點重復第一步的步驟。即再對平面中所有點算距離,然后分發到4個新簇中。不斷迭代,直到誤差較小。
這就是 Kmeans 算法的過程了。
三. 知識點淺析
3.1 確定“簇”的個數
上面所說的分成 4 個簇,這個 4 其實就是 Kmeans 中的K。要使用 Kmeans 首先就是要選取一個 K 作為聚類個數。而上面的例子其實是我們主觀”看“出來的,但多數情況下我們是無法直觀”看“出分多少個 K 比較好。那怎么辦呢?
我們可以從較低的 K 值開始。使用較簡單的 Kmeans 算法的結果(即較少的迭代次數,不求最佳結果,但求最快)。計算每個點到其歸屬的“簇”的中心點的距離,然后求和,求和結果就是誤差值。
然后再增加 K 值,再計算誤差值。比如上面的例子,我們可以從 K=2 開始,計算 K 值從 2 到 7 的 Kmeans 算法的誤差值。
這樣會得到類似這樣一張圖:

里面的 Error 可以理解未 Kmeans 的誤差,而當分成越多“簇”的適合,誤差肯定是越來越小。
但是不是“簇”越多越好呢?答案是否定的,有時候“簇”過多的話是不利于我們得到想要的結果或是做下一步操作的。
所以我們通常會選擇誤差減小速度比較平緩的那個臨界點,比如上圖中的 4。
可以發現,在分成 4 個簇之后,再增加簇的數量,誤差也不會有很大的減少。而取 4 個簇也和我們所看到的相符。
3.2 歐式距離
歐氏距離是一個通常采用的距離定義,指在m維空間中兩個點之間的真實距離,計算公式如下:
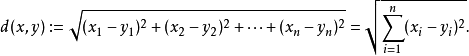
而本例種的是在二維空間種,故而本例的計算公式如下:
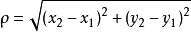
四. 代碼和結果
加載數據的代碼,使用了 numpy ,先是將代碼加載成 matrix 類型。
import numpy as np
def loadDataSet(fileName):
'''
加載數據集
:param fileName:
:return:
'''
# 初始化一個空列表
dataSet = []
# 讀取文件
fr = open(fileName)
# 循環遍歷文件所有行
for line in fr.readlines():
# 切割每一行的數據
curLine = line.strip().split('\t')
# 將數據轉換為浮點類型,便于后面的計算
# fltLine = [float(x) for x in curLine]
# 將數據追加到dataMat
fltLine = list(map(float,curLine)) # 映射所有的元素為 float(浮點數)類型
dataSet.append(fltLine)
# 返回dataMat
return np.matrix(dataSet)
接下來需要生成 K 個初始的質點,即中心點。這里采用隨機生成的方法生成 k 個“簇”。
def randCent(dataMat, k):
'''
為給定數據集構建一個包含K個隨機質心的集合,
隨機質心必須要在整個數據集的邊界之內,這可以通過找到數據集每一維的最小和最大值來完成
然后生成0到1.0之間的隨機數并通過取值范圍和最小值,以便確保隨機點在數據的邊界之內
:param dataMat:
:param k:
:return:
'''
# 獲取樣本數與特征值
m, n = np.shape(dataMat)
# 初始化質心,創建(k,n)個以零填充的矩陣
centroids = np.mat(np.zeros((k, n)))
# 循環遍歷特征值
for j in range(n):
# 計算每一列的最小值
minJ = min(dataMat[:, j])
# 計算每一列的范圍值
rangeJ = float(max(dataMat[:, j]) - minJ)
# 計算每一列的質心,并將值賦給centroids
centroids[:, j] = np.mat(minJ + rangeJ * np.random.rand(k, 1))
# 返回質心
return centroids
歐式距離計算
def distEclud(vecA, vecB): ''' 歐氏距離計算函數 :param vecA: :param vecB: :return: ''' return np.sqrt(sum(np.power(vecA - vecB, 2)))
cost 方法將執行一個簡化的 kMeans ,即較少次數的迭代,計算出其中的誤差(即當前點到簇質心的距離,后面會使用該誤差來評價聚類的效果)
def cost(dataMat, k, distMeas=distEclud, createCent=randCent,iterNum=300):
'''
計算誤差的多少,通過這個方法來確定 k 為多少比較合適,這個其實就是一個簡化版的 kMeans
:param dataMat: 數據集
:param k: 簇的數目
:param distMeans: 計算距離
:param createCent: 創建初始質心
:param iterNum:默認迭代次數
:return:
'''
# 獲取樣本數和特征數
m, n = np.shape(dataMat)
# 初始化一個矩陣來存儲每個點的簇分配結果
# clusterAssment包含兩個列:一列記錄簇索引值,第二列存儲誤差(誤差是指當前點到簇質心的距離,后面會使用該誤差來評價聚類的效果)
clusterAssment = np.mat(np.zeros((m, 2)))
# 創建質心,隨機K個質心
centroids = createCent(dataMat, k)
clusterChanged = True
while iterNum > 0:
clusterChanged = False
# 遍歷所有數據找到距離每個點最近的質心,
# 可以通過對每個點遍歷所有質心并計算點到每個質心的距離來完成
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
# 計算數據點到質心的距離
# 計算距離是使用distMeas參數給出的距離公式,默認距離函數是distEclud
distJI = distMeas(centroids[j, :], dataMat[i, :])
# print(distJI)
# 如果距離比minDist(最小距離)還小,更新minDist(最小距離)和最小質心的index(索引)
if distJI < minDist:
minDist = distJI
minIndex = j
# 更新簇分配結果為最小質心的index(索引),minDist(最小距離)的平方
clusterAssment[i, :] = minIndex, minDist ** 2
iterNum -= 1;
# print(centroids)
# 遍歷所有質心并更新它們的取值
for cent in range(k):
# 通過數據過濾來獲得給定簇的所有點
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 計算所有點的均值,axis=0表示沿矩陣的列方向進行均值計算
centroids[cent, :] = np.mean(ptsInClust, axis=0)
# 返回給定迭代次數后誤差的值
return np.mat(clusterAssment[:,1].sum(0))[0,0]
最后可以調用 Kmeans 算法來進行計算。
def kMeans(dataMat, k, distMeas=distEclud, createCent=randCent):
'''
創建K個質心,然后將每個店分配到最近的質心,再重新計算質心。
這個過程重復數次,直到數據點的簇分配結果不再改變為止
:param dataMat: 數據集
:param k: 簇的數目
:param distMeans: 計算距離
:param createCent: 創建初始質心
:return:
'''
# 獲取樣本數和特征數
m, n = np.shape(dataMat)
# 初始化一個矩陣來存儲每個點的簇分配結果
# clusterAssment包含兩個列:一列記錄簇索引值,第二列存儲誤差(誤差是指當前點到簇質心的距離,后面會使用該誤差來評價聚類的效果)
clusterAssment = np.mat(np.zeros((m, 2)))
# 創建質心,隨機K個質心
centroids = createCent(dataMat, k)
# 初始化標志變量,用于判斷迭代是否繼續,如果True,則繼續迭代
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 遍歷所有數據找到距離每個點最近的質心,
# 可以通過對每個點遍歷所有質心并計算點到每個質心的距離來完成
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
# 計算數據點到質心的距離
# 計算距離是使用distMeas參數給出的距離公式,默認距離函數是distEclud
distJI = distMeas(centroids[j, :], dataMat[i, :])
# 如果距離比minDist(最小距離)還小,更新minDist(最小距離)和最小質心的index(索引)
if distJI < minDist:
minDist = distJI
minIndex = j
# 如果任一點的簇分配結果發生改變,則更新clusterChanged標志
if clusterAssment[i, 0] != minIndex: clusterChanged = True
# 更新簇分配結果為最小質心的index(索引),minDist(最小距離)的平方
clusterAssment[i, :] = minIndex, minDist ** 2
# print(centroids)
# 遍歷所有質心并更新它們的取值
for cent in range(k):
# 通過數據過濾來獲得給定簇的所有點
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 計算所有點的均值,axis=0表示沿矩陣的列方向進行均值計算
centroids[cent, :] = np.mean(ptsInClust, axis=0)
# 返回所有的類質心與點分配結果
return centroids, clusterAssment
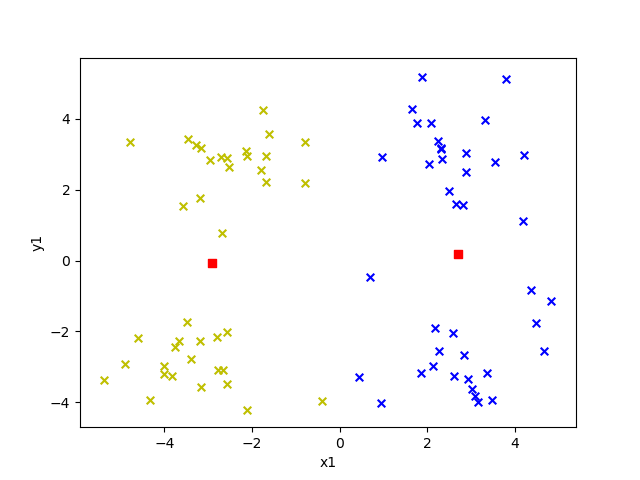
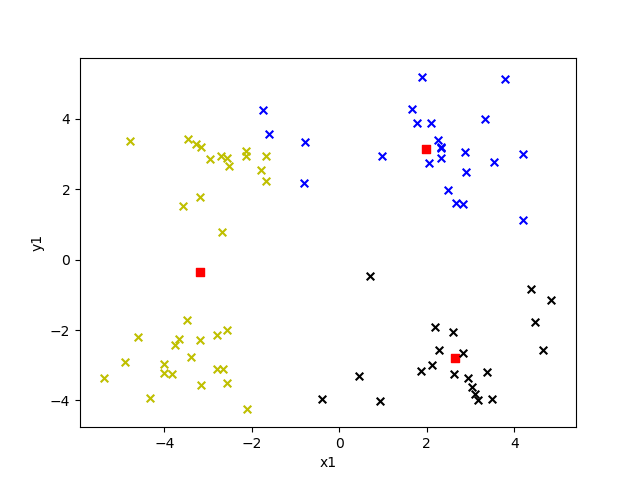
選取不同的 k 值對結果影響有多大呢?我們來看看就知道了,下面給出的是 k 值為 2 到 6 的效果。
圖中紅色方塊即為“簇”的中心點,每個“簇”所屬的點用不同的顏色表示。
K = 2
K = 3
K = 4
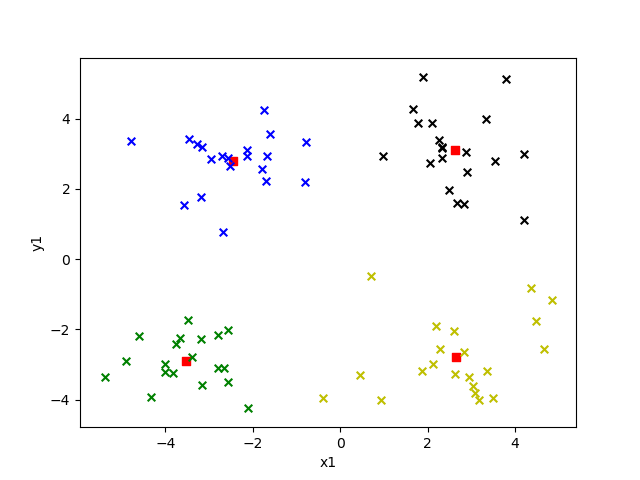
K = 5
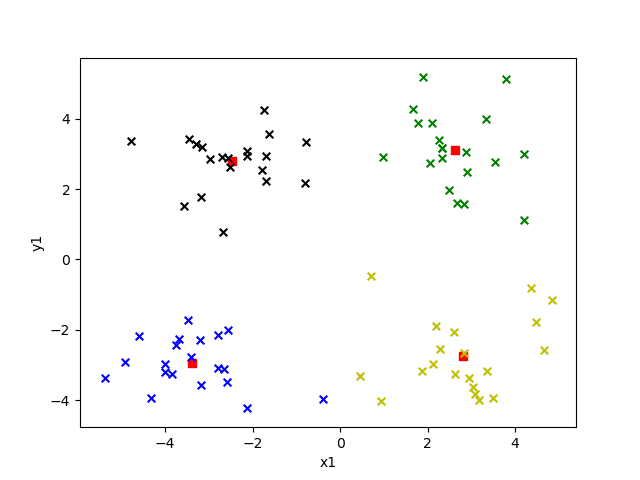
K = 6
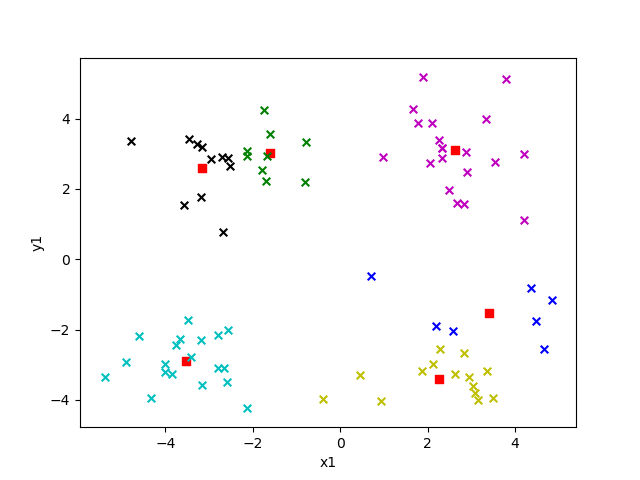
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





