溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Pytorch怎么使用Google Colab訓練神經網絡深度”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
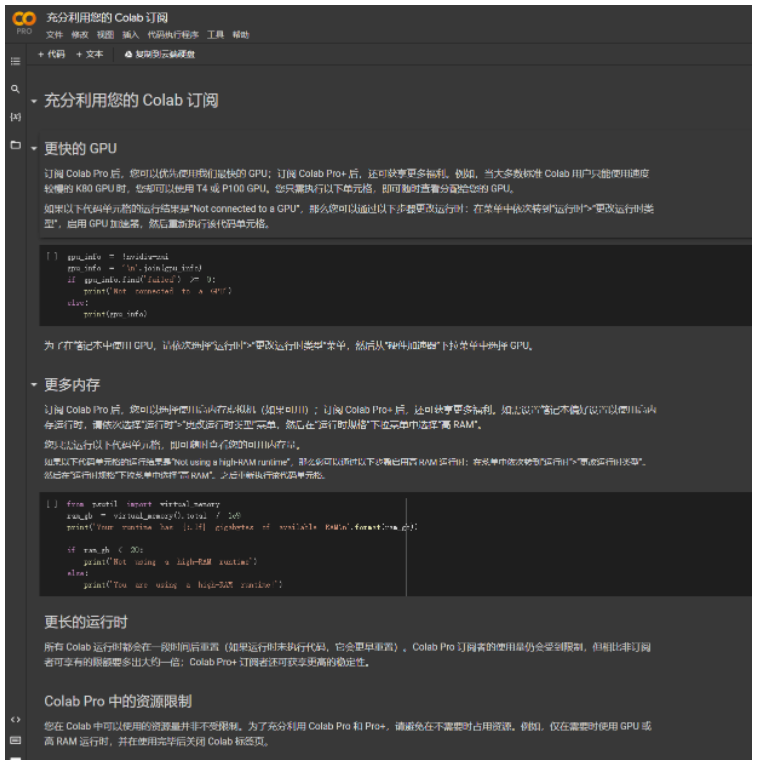
Google Colab是谷歌提供的免費Jupyter 筆記本環境,不需要什么設置與環境配置就可以使用,完全在云端運行。不影響本地的使用。
Google Colab為研究者提供一定免費的GPU,可以編寫和執行代碼,所有這些都可通過瀏覽器免費使用。同學們可以在上面輕松地跑 Tensorflow、Pytorch 等深度學習框架。
盡管Google Colab提供了一定的免費資源,但資源量是受限制的,所有 Colab 運行時都會在一段時間后重置。Colab Pro 訂閱者的使用量仍會受到限制,但相比非訂閱者可享有的限額要多出大約一倍。Colab Pro+ 訂閱者還可獲享更高的穩定性。
本文以YoloV4-Tiny-Pytorch版本的訓練為例,進行Colab的使用演示。
Colab和Google自帶的云盤聯動非常好,因此我們需要首先將數據集上傳云盤,這個上傳的過程其實非常簡單,本地先準備好數據集。
由于我所上傳的庫,均使用的VOC數據集,我們需要按照VOC數據集擺放好
本文直接以VOC07+12數據集為例進行演示。

JPEGImages里面存放的為圖片文件,Annotations里面存放的標簽文件,ImageSets里面存放的是區分驗證集、訓練集、測試集的txt文件。
然后將VOCdevkit文件整個進行打包。需要注意的是,不是對上面三個文件夾進行打包,而是對VOCdevkit進行打包,這樣才滿足數據處理的格式。

在獲得打包后的壓縮包后,將壓縮包上傳到谷歌云盤。我在谷歌云盤上新建了一個VOC_datasets文件夾存放壓縮包。
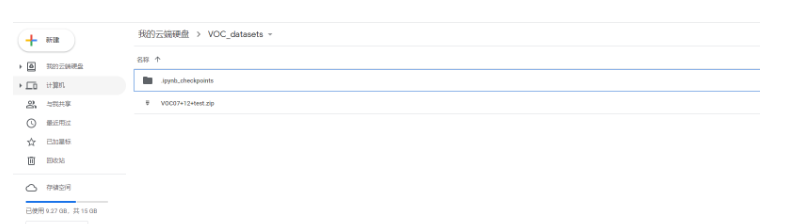
此時數據集的上傳已經完成。
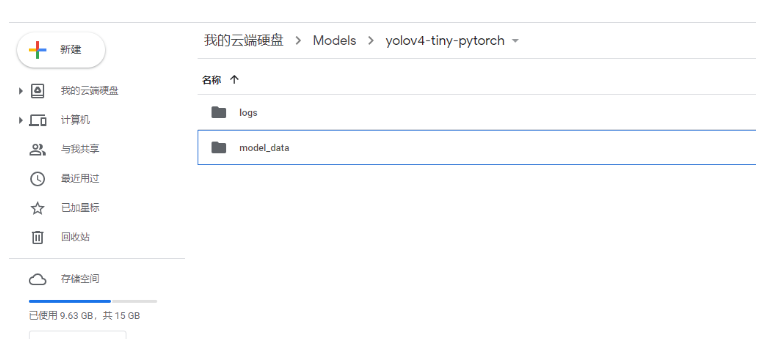
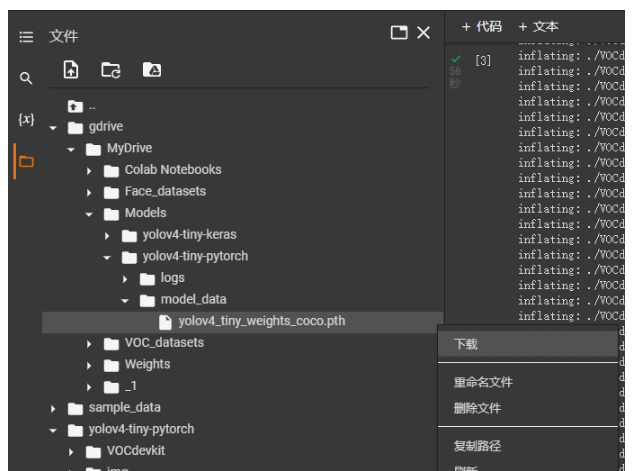
在谷歌云盤上進行文件夾的創建,首先創建Models,然后在Models里面創建yolov4-tiny-pytorch,然后在yolov4-tiny-pytorch里面創建logs和model_data。
model_data放置的是預訓練文件。
logs放置的是網絡訓練過程中產生的權值。
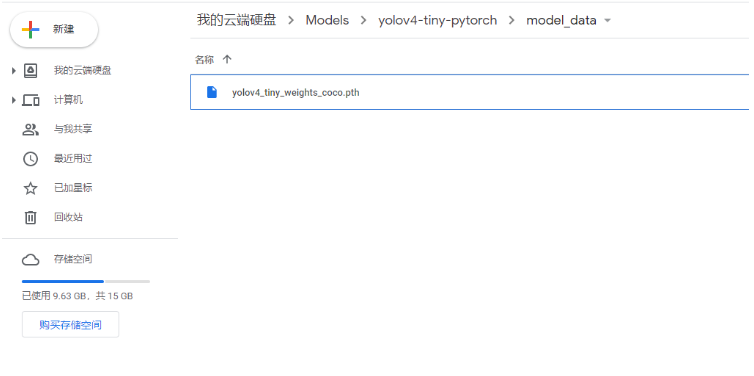
由于我們這次使用的是YoloV4-Tiny-Pytorch的庫,我們將它的預訓練權重上傳到model_data文件夾。
在該步中,我們首先打開Colab的官網。

然后點擊文件,創建筆記本,此時會創建一個jupyter筆記本。
創建完成后給文件改個名,好看一些。

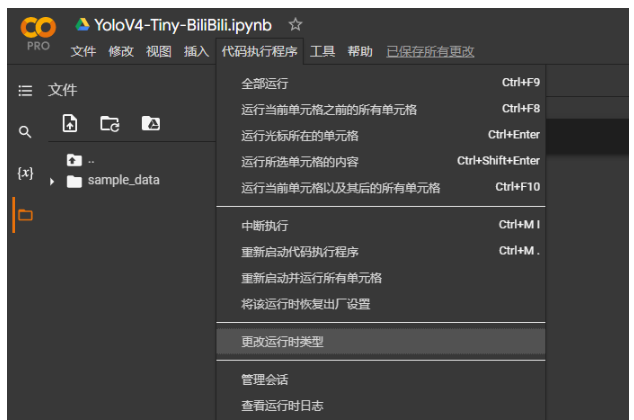
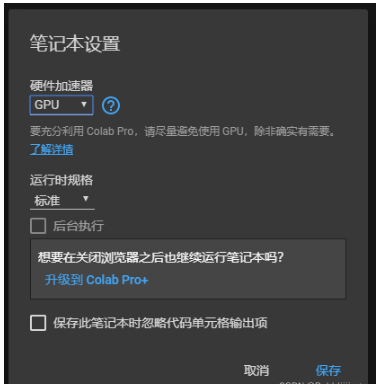
之后點擊代碼執行程序,然后點擊更改運行時類型,在其中硬件加速器部分選擇GPU,Colab便會配置一個帶有GPU的機器,此時筆記本就創建完成了。
colab已經集成了pytorch環境,無需專門配置pytorch,不過使用的torch版本較新。
由于我們的數據集在谷歌云盤上,所以我們還要掛載云盤。
from google.colab import drive
drive.mount('/content/gdrive')我們將上述代碼輸入到筆記本中執行。將云盤掛載到服務器上。然后點擊運行即可。

此時點擊左邊欄中,類似于文件夾的東西,就可以打開文件夾了,看看文件部署情況。gdrive就是我們配置的谷歌云盤。沒有的話就去左側刷新一下。
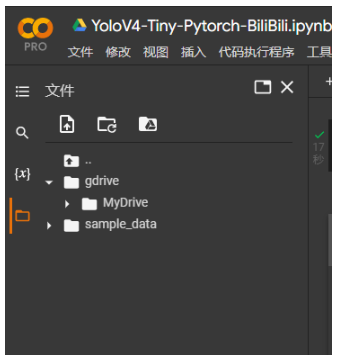
打開gdrive,其中有我們的數據集。

這一步,我們需要完成深度學習倉庫的下載,我們使用git clone指令進行下載。執行如下指令后,左邊的文件中多出了yolov4-tiny-pytorch文件夾。沒有的話就去左側刷新一下。
然后我們通過了cd指令將根目錄轉移到了yolov4-tiny-pytorch文件夾。
!git clone https://github.com/bubbliiiing/yolov4-tiny-pytorch.git %cd yolov4-tiny-pytorch/
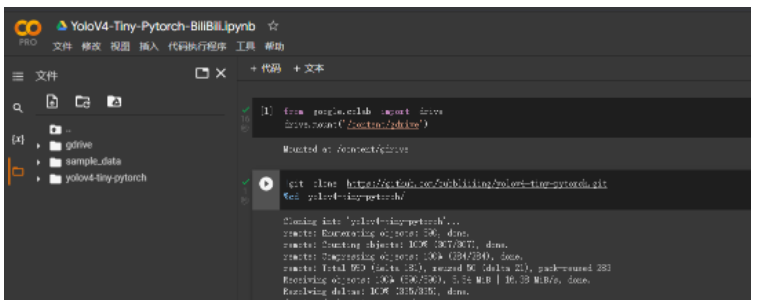
直接將數據集布置在谷歌云盤會導致大量的云盤數據傳輸,速度遠不及本地文件,因此我們需要將數據集復制到本地里進行處理。
我們輸入下述代碼進行文件的復制與解壓。首先執行的是刪除指令,將原來的空VOCdevkit文件夾進行刪除。然后進行解壓。
由于這里使用的是zip文件所以使用的是unzip指令,如果是其它形式的壓縮包,需要根據壓縮包的格式進行指令的修改(請同學們百度)。執行下述指令后,可以發現,左邊的文件中已經解壓好了VOC數據集。沒有的話就去左側刷新一下。
!rm -rf ./VOCdevkit !cp /content/gdrive/MyDrive/VOC_datasets/VOC07+12+test.zip ./ !unzip ./VOC07+12+test.zip -d ./
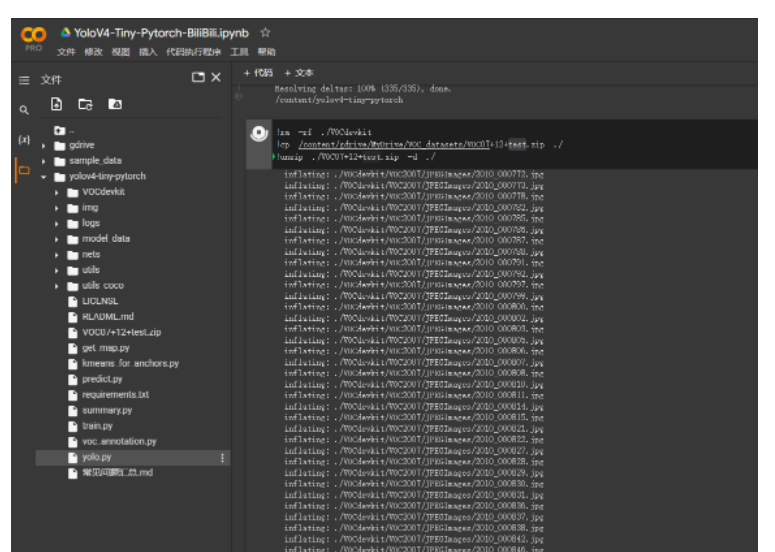
本文提供的代碼默認的保存路徑為logs文件夾,但Colab存在不穩定的問題,運行一段時間后會發生斷線。
如果將權值保存在原始根目錄下的logs文件夾,發生斷線網絡就白訓練了,浪費大量的時間。
可以將google云盤軟連接到根目錄下,那么即使斷線,權值也保留在云盤中。
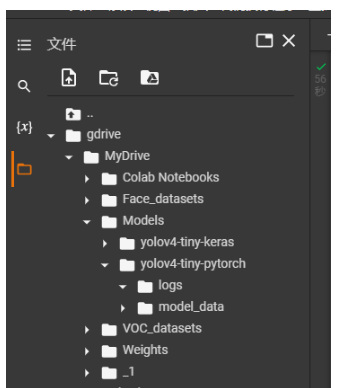
本文之前在云盤中創建了logs文件夾。將該文件夾鏈接過來。
!rm -rf logs !ln -s /content/gdrive/MyDrive/Models/yolov4-tiny-pytorch/logs logs
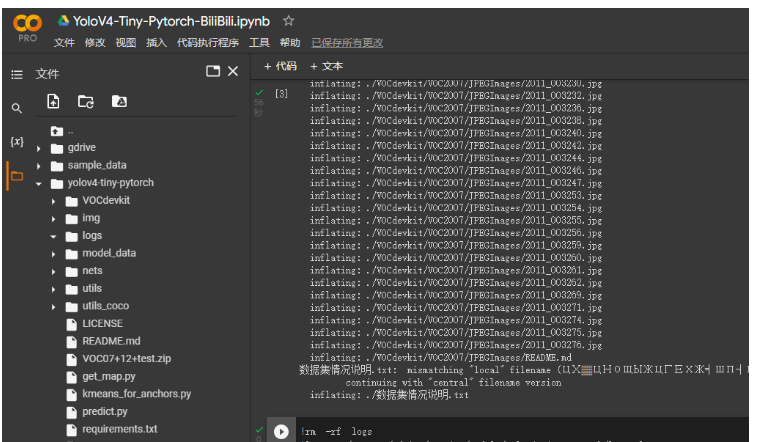
打開voc_annotation.py文件,由于我們現在使用的直接就是VOC數據集,我們已經劃分好了訓練集驗證集和測試集,所以我們將annotation_mode設置為2。
然后輸入指令完成標簽的處理,生成2007_train.txt和2007_val.txt。
!python voc_annotation.py
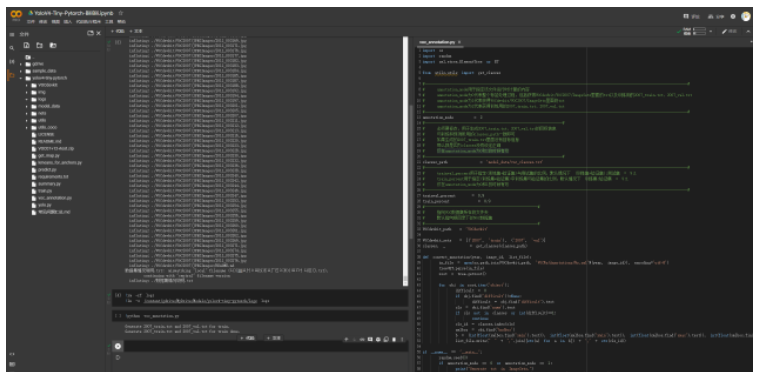
處理訓練文件主要包含三個部分:
1、預訓練文件的使用。
2、保存周期的設置,這個設置是因為云盤的存儲空間有限,每代都保存會導致存儲空間滿出。
a、預訓練文件的使用
首先修改model_path,指向我們上傳到谷歌云盤的權值文件。在左側文件欄中,找到models/yolov4-tiny-pytorch/model_data,復制權值路徑。
替換右側的model_path。
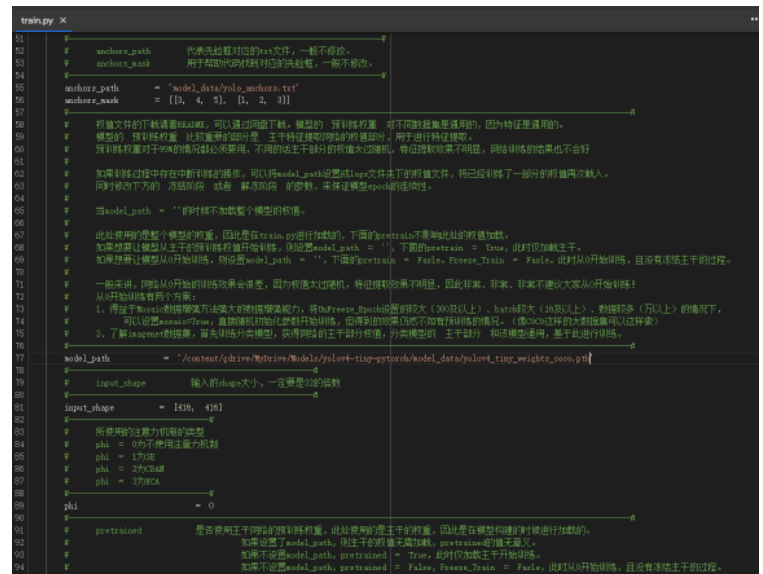
b、保存周期的設置
有一些倉庫已經完成了更新,添加了每隔多少世代的保存參數,直接修改save_period既可,在本文中,我們將save_period設置成4,也就是每隔4代保存一次。
還沒有更新的倉庫只能每一代都保存了,記得偶爾去google云盤刪一下。

此時在筆記本里面輸入:
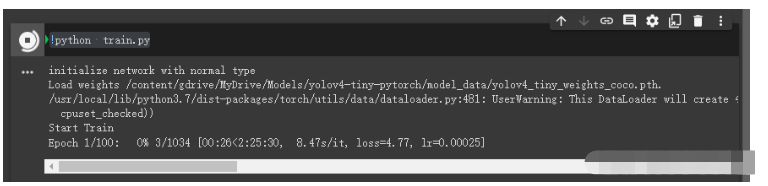
!python train.py
即可開始訓練。
聽說可以通過自動點擊來減少掉線頻率。
在Google colab的按F12,點擊網頁的控制臺,粘貼如下代碼:
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);沒什么辦法,便宜的東西必然有它的壞處。
按照步驟重新來一次,然后將預訓練權重設置成logs文件夾里面訓練好的權值文件即可。
除此之外,Init_epoch等參數也需要調整。
“Pytorch怎么使用Google Colab訓練神經網絡深度”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





