溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“怎么使用Pytorch進行多卡訓練”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“怎么使用Pytorch進行多卡訓練”文章吧。
當一塊GPU不夠用時,我們就需要使用多卡進行并行訓練。其中多卡并行可分為數據并行和模型并行。具體區別如下圖所示:
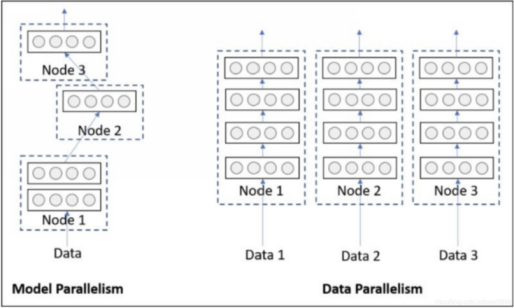
由于模型并行比較少用,這里只對數據并行進行記錄。對于pytorch,有兩種方式可以進行數據并行:數據并行(DataParallel, DP)和分布式數據并行(DistributedDataParallel, DDP)。
在多卡訓練的實現上,DP與DDP的思路是相似的:
1、每張卡都復制一個有相同參數的模型副本。
2、每次迭代,每張卡分別輸入不同批次數據,分別計算梯度。
3、DP與DDP的主要不同在于接下來的多卡通信:
DP的多卡交互實現在一個進程之中,它將一張卡視為主卡,維護單獨模型優化器。所有卡計算完梯度后,主卡匯聚其它卡的梯度進行平均并用優化器更新模型參數,再將模型參數更新至其它卡上。
DDP則分別為每張卡創建一個進程,每個進程相應的卡上都獨立維護模型和優化器。在每次每張卡計算完梯度之后,進程之間以NCLL(NVIDIA GPU通信)為通信后端,使各卡獲取其它卡的梯度。各卡對獲取的梯度進行平均,然后執行后續的參數更新。由于每張卡上的模型與優化器參數在初始化時就保持一致,而每次迭代的平均梯度也保持一致,那么即使沒有進行參數復制,所有卡的模型參數也是保持一致的。
Pytorch官方推薦我們使用DDP。DP經過我的實驗,兩塊GPU甚至比一塊還慢。當然不同模型可能有不同的結果。下面分別對DP和DDP進行記錄。
Pytorch的DP實現多GPU訓練十分簡單,只需在單GPU的基礎上加一行代碼即可。以下是一個DEMO的代碼。
import torch
from torch import nn
from torch.optim import Adam
from torch.nn.parallel import DataParallel
class DEMO_model(nn.Module):
def __init__(self, in_size, out_size):
super().__init__()
self.fc = nn.Linear(in_size, out_size)
def forward(self, inp):
outp = self.fc(inp)
print(inp.shape, outp.device)
return outp
model = DEMO_model(10, 5).to('cuda')
model = DataParallel(model, device_ids=[0, 1]) # 額外加這一行
adam = Adam(model.parameters())
# 進行訓練
for i in range(1):
x = torch.rand([128, 10]) # 獲取訓練數據,無需指定設備
y = model(x) # 自動均勻劃分數據批量并分配至各GPU,輸出結果y會聚集到GPU0中
loss = torch.norm(y)
loss.backward()
adam.step()其中model = DataParallel(model, device_ids=[0, 1])這行將模型復制到0,1號GPU上。輸入數據x無需指定設備,它將會被均勻分配至各塊GPU模型,進行前向傳播。之后各塊GPU的輸出再合并到GPU0中,得到輸出y。輸出y在GPU0中計算損失,并進行反向傳播計算梯度、優化器更新參數。
為了對分布式編程有基本概念,首先使用pytorch內部的方法實現一個多進程程序,再使用DDP模塊實現模型的分布式訓練。
首先使用pytorch內部的方法編寫一個多進程程序作為編寫分布式訓練的基礎。
import os, torch
import torch.multiprocessing as mp
import torch.distributed as dist
def run(rank, size):
tensor = torch.tensor([1,2,3,4], device='cuda:'+str(rank)) # ——1——
group = dist.new_group(range(size)) # ——2——
dist.all_reduce(tensor=tensor, group=group, op=dist.ReduceOp.SUM) # ——3——
print(str(rank)+ ': ' + str(tensor) + '\n')
def ini_process(rank, size, fn, backend = 'nccl'):
os.environ['MASTER_ADDR'] = '127.0.0.1' # ——4——
os.environ['MASTER_PORT'] = '1234'
dist.init_process_group(backend, rank=rank, world_size=size) # ——5——
fn(rank, size) # ——6——
if __name__ == '__main__': # ——7——
mp.set_start_method('spawn') # ——8——
size = 2 # ——9——
ps = []
for rank in range(size):
p = mp.Process(target=ini_process, args=(rank, size, run)) # ——10——
p.start()
ps.append(p)
for p in ps: # ——11——
p.join()以上代碼主進程創建了兩個子進程,子進程之間使用NCCL后端進行通信。每個子進程各占用一個GPU資源,實現了所有GPU張量求和的功能。細節注釋如下:
1、為每個子進程定義相同名稱的張量,并分別分配至不同的GPU,從而能進行后續的GPU間通信。
2、定義一個通信組,用于后面的all_reduce通信操作。
3、all_reduce操作以及其它通信方式請看下圖:
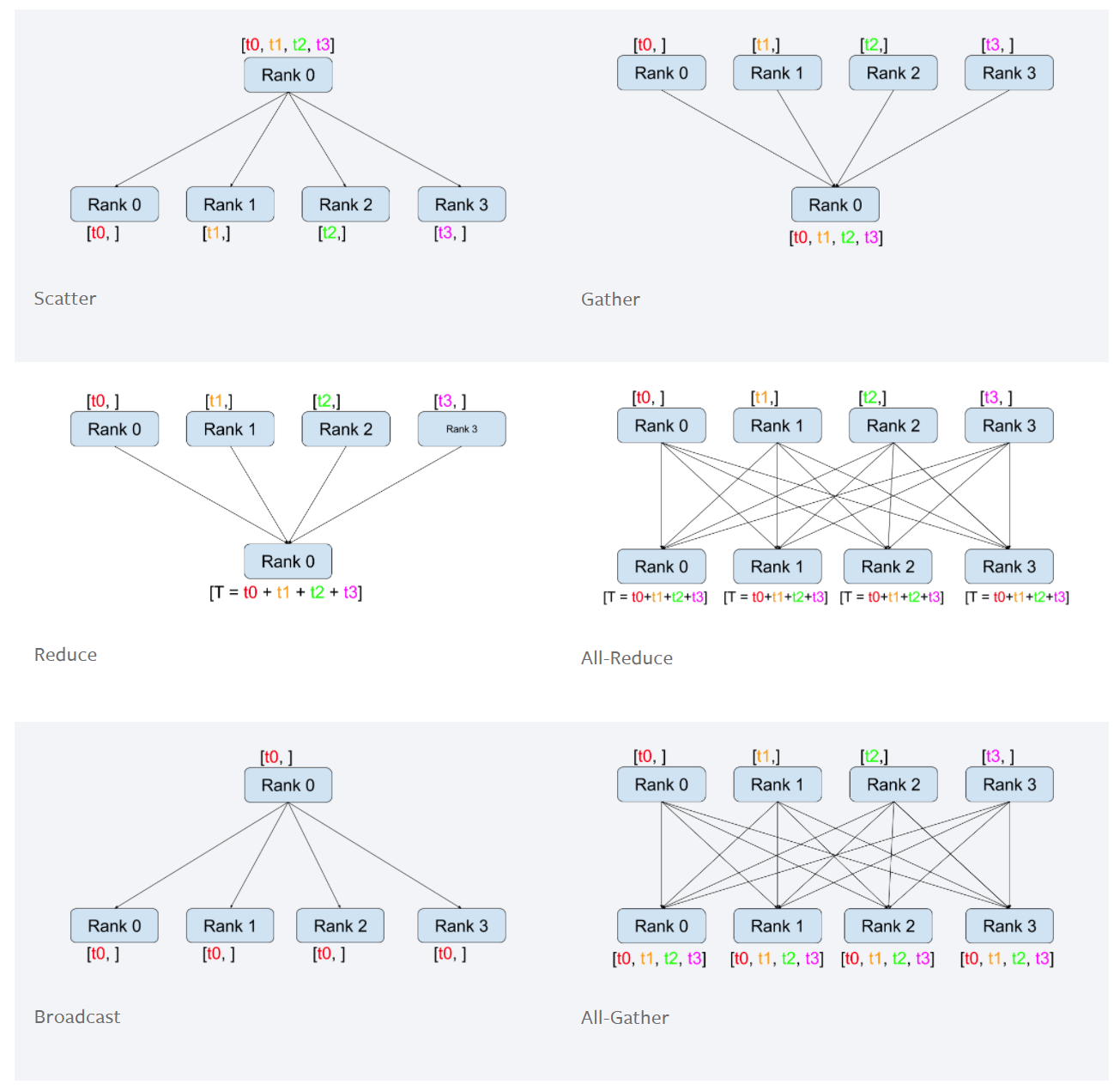
4、定義編號(rank)為0的ip和端口地址,讓每個子進程都知道。ip和端口地址可以隨意定義,不沖突即可。如果不設置,子進程在涉及進程通信時會出錯。
5、初始化子進程組,定義進程間的通信后端(還有GLOO、MPI,只有NCCL支持GPU間通信)、子進程rank、子進程數量。只有當該函數在size個進程中被調用時,各進程才會繼續從這里執行下去。這個函數統一了各子進程后續代碼的開始時間。
6、執行子進程代碼。
7、由于創建子進程會執行本程序,因此主進程的執行需要放在__main__里,防止子進程執行。
8、開始創建子進程的方式:spawn、fork。windows默認spawn,linux默認fork。具體區別請百度。
9、由于是以NCCL為通信后端的分布式訓練,如果不同進程中相同名稱的張量在同一GPU上,當這個張量進行進程間通信時就會出錯。為了防止出錯,限制每張卡獨占一個進程,每個進程獨占一張卡。這里有兩張卡,所以最多只能創建兩個進程。
10、創建子進程,傳入子進程的初始化方法,及子進程調用該方法的參數。
11、等待子進程全部運行完畢后再退出主進程。
輸出結果如下:

正是各進程保存在不同GPU上的張量的廣播求和(all_reduce)的結果。
我們實際上可以根據上面的分布式基礎寫一個分布式訓練,但由于不知道pytorch如何實現GPU間模型梯度的求和,即官方教程中所謂的ring_reduce(沒找到相關API),時間原因,就不再去搜索相關方法了。這里僅記錄pytorh內部的分布式模型訓練,即利用DDP模塊實現。Pytorch版本1.12.1。
import torch,os
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
from torch import nn
def example(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size) # ——1——
model = nn.Linear(2, 1, False).to(rank)
if rank == 0: # ——2——
model.load_state_dict(torch.load('model_weight'))
# model_stat = torch.load('model_weight', {'cuda:0':'cuda:%d'%rank}) #這樣讀取保險一點
# model.load_state_dict(model_stat)
opt = optim.Adam(model.parameters(), lr=0.0001) # ——3——
opt_stat = torch.load('opt_weight', {'cuda:0':'cuda:%d'%rank}) # ——4——
opt.load_state_dict(opt_stat) # ——5——
ddp_model = DDP(model, device_ids=[rank])# ——6
inp = torch.tensor([[1.,2]]).to(rank) # ——7——
labels = torch.tensor([[5.]]).to(rank)
outp = ddp_model(inp)
loss = torch.mean((outp - labels)**2)
opt.zero_grad()
loss.backward() # ——8——
opt.step() # ——9
if rank == 0:# ——10——
torch.save(model.state_dict(), 'model_weight')
torch.save(opt.state_dict(), 'opt_weight')
if __name__=="__main__":
os.environ["MASTER_ADDR"] = "localhost"# ——11——
os.environ["MASTER_PORT"] = "29500"
world_size = 2
mp.spawn(example, args=(world_size,), nprocs=world_size, join=True) # ——12——以上代碼包含模型在多GPU上讀取權重、進行分布式訓練、保存權重等過程。細節注釋如下:
1、初始化進程組,由于使用GPU通信,后端應該寫為NCCL。不過經過實驗,即使錯寫為gloo,DDP內部也會自動使用NCCL作為通信模塊。
2、由于后面使用DDP包裹模型進行訓練,其內部會自動將所有rank的模型權重同步為rank 0的權重,因此我們只需在rank 0上讀取模型權重即可。這是基于Pytorch版本1.12.1,低級版本似乎沒有這個特性,需要在不同rank分別導入權重,則load需要傳入map_location,如下面注釋的兩行代碼所示。
3、這里創建model的優化器,而不是創建用ddp包裹后的ddp_model的優化器,是為了兼容單GPU訓練,讀取優化器權重更方便。
4、將優化器權重讀取至該進程占用的GPU。如果沒有map_location參數,load會將權重讀取到原本保存它時的設備。
5、優化器獲取權重。經過實驗,即使權重不在優化器所在的GPU,權重也會遷移過去而不會報錯。當然load直接讀取到相應GPU會減少數據傳輸。
6、DDP包裹模型,為模型復制一個副本到相應GPU中。所有rank的模型副本會與rank 0保持一致。注意,DDP并不復制模型優化器的副本,因此各進程的優化器需要我們在初始化時保持一致。權重要么不讀取,要么都讀取。
7、這里開始模型的訓練。數據需轉移到相應的GPU設備。
8、在backward中,所有進程的模型計算梯度后,會進行平均(不是相加)。也就是說,DDP在backward函數添加了hook,所有進程的模型梯度的ring_reduce將在這里執行。這個可以通過給各進程模型分別輸入不同的數據進行驗證,backward后這些模型有相同的梯度,且驗算的確是所有進程梯度的平均。此外,還可以驗證backward函數會阻斷(block)各進程使用梯度,只有當所有進程都完成backward之后,各進程才能讀取和使用梯度。這保證了所有進程在梯度上的一致性。
9、各進程優化器使用梯度更新其模型副本權重。由于初始化時各進程模型、優化器權重一致,每次反向傳播梯度也保持一致,則所有進程的模型在整個訓練過程中都能保持一致。
10、由于所有進程權重保持一致,我們只需通過一個進程保存即可。
11、定義rank 0的IP和端口,使用mp.spawn,只需在主進程中定義即可,無需分別在子進程中定義。
12、創建子進程,傳入:子進程調用的函數(該函數第一個參數必須是rank)、子進程函數的參數(除了rank參數外)、子進程數、是否等待所有子進程創建完畢再開始執行。
以上就是關于“怎么使用Pytorch進行多卡訓練”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





