溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“python中如何實現tensorflow實現斑馬線識別功能”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“python中如何實現tensorflow實現斑馬線識別功能”這篇文章吧。
數據集的構成:
| test | train |
|---|---|
| zebra corssing:56 | zebra corssing:168 |
| other:54 | other:164 |
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt import keras
train_dir=r'C:\Users\zx\深度學習\Zebra\train' test_dir=r'C:\Users\zx\深度學習\Zebra\test' train_datagen = ImageDataGenerator(rescale=1/255, rotation_range=10, #旋轉 horizontal_flip=True) train_generator = train_datagen.flow_from_directory(train_dir, (50,50), batch_size=1, class_mode='binary', shuffle=False) test_datagen = ImageDataGenerator(rescale=1/255) test_generator = test_datagen.flow_from_directory(test_dir, (50,50), batch_size=1, class_mode='binary', shuffle=False)
模型的建立仁者見智,可自己調節尋找更好的模型。
model = tf.keras.models.Sequential([ # 第一層卷積,卷積核為,共16個,輸入為150*150*1 tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same',input_shape=(50,50,3)), tf.keras.layers.MaxPooling2D((2,2)), # 第二層卷積,卷積核為3*3,共32個, tf.keras.layers.Conv2D(32,(3,3),activation='relu'), tf.keras.layers.MaxPooling2D((2,2)), # 第三層卷積,卷積核為3*3,共64個, tf.keras.layers.Conv2D(64,(3,3),activation='relu'), tf.keras.layers.MaxPooling2D((2,2)), # 第四層卷積,卷積核為3*3,共128個 # tf.keras.layers.Conv2D(128,(3,3),activation='relu'), # tf.keras.layers.MaxPooling2D((2,2)), # 數據鋪平 tf.keras.layers.Flatten(), tf.keras.layers.Dense(32,activation='relu'), tf.keras.layers.Dense(16,activation='relu'), tf.keras.layers.Dense(2,activation='softmax') ]) print(model.summary()) model.compile(optimize='adam', loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=['acc'])
history = model.fit(train_generator,
epochs=20,
verbose=1)
model.save('./Zebra.h6')模型訓練過程:

可以看到我們的模型在20輪的訓練后acc從0.63上升到了0.96左右。
model.evaluate(test_generator)
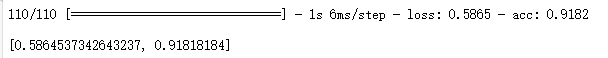
#可視化
plt.plot(history.history['acc'], label='accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.7, 1])
plt.legend(loc='lower right')
plt.title('acc')
plt.show()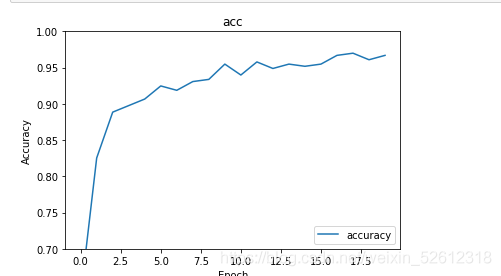
雖然我們的模型在訓練過程中acc一度達到0.96,但測試集才是檢驗模型的唯一標準,在model.evaluate(test_generator)中的評分只有0.91左右,說明我們的模型已經能以很高的正確率來完成”斑馬線“與“非斑馬線”的二分類問題了,但我們還是要查看具體是哪些數據沒有被模型正確得識別。
pred=model.predict(test_generator) #獲取test集的輸出 filenames = test_generator.filenames #獲取test數據的文件名
錯誤輸出過程:
1,循環測試集長度,通過if語句先判斷others還是zebra,再通過one-hot編碼判斷是否預測正確。
2,根據labels可知others': 0, 'zebra crossing': 1,以此來判斷是否預測正確。
3,對 filenames[0]='others\\103.png',進行切片處理。
4,找到others的‘s'或 zebra crossing的‘g',使用find()在基礎上+2為正切片的起點(樣本編號前有'\'符號,故+2才能正確取出編號)。
5,如 :將filenames[i]的值賦給a,a[int(a.find('s')+2):]則表示為 'xx.png'。
6,將取出的樣本編號與路徑拼接,讀取后作圖。
7,break跳出循環。
for i in range(len(filenames)):
if filenames[i][:6]=='others':
if np.argmax(pred[i]) != 0:
a=filenames[i]
plt.figure()
print('預測錯誤的圖片:'+a[int(a.find('s')+2):])
print('錯誤識別為"zebra crossing",正確類型是"others"')
print('預測標簽為:'+str(np.argmax(pred[i]))+',真實標簽為:0')
img = plt.imread('Zebra/test/others/'+a[int(a.find('s')+2):])
plt.imshow(img)
plt.title(a[int(a.find('s')+2):])
plt.grid(False)
break
if filenames[i][:6]=='zebra ':
if np.argmax(pred[i]) != 1:
b= filenames[i]
plt.figure()
print('預測錯誤的圖片:'+b[int(b.find('g')+2):])
print('錯誤識別為"others",正確類型是"zebra crossing"')
print('預測標簽為:'+str(np.argmax(pred[i]))+',真實標簽為:1')
img = plt.imread('Zebra/test/zebra crossing/'+b[int(b.find('g')+2):])
plt.imshow(img)
plt.title(b[int(b.find('g')+2):])
plt.grid(False)
break
看到這個錯誤樣本,我猜想可能是因為斑馬線的部分只占了圖像的一半左右,所以預測錯誤了。
這里是我做預測判斷的思路,本可以不這么復雜的可以用test_generator.labels來獲取數據的標簽,再做判斷。
test_generator.labels
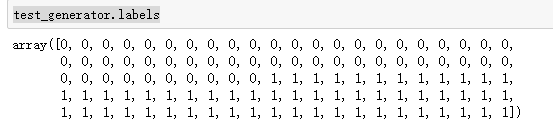
上面只輸出了第一個錯誤的樣本,所以接下來我們要看所有錯誤預測的樣本
sum=0
for i in range(len(filenames)):
if filenames[i][:6]=='others':
if np.argmax(pred[i]) != 0:
a=filenames[i]
print('預測錯誤的圖片:'+a[int(a.find('s')+2):]+',錯誤識別為"zebra crossing",正確類型是"others"')
sum=sum+1
if filenames[i][:6]=='zebra ':
if np.argmax(pred[i]) != 1:
b= filenames[i]
print('預測錯誤的圖片:'+b[int(b.find('g')+2):]+',錯誤識別為"others",正確類型是"zebra crossing"')
sum=sum+1
print('錯誤率:'+str(sum/100)+'%')
print('正確率:'+str((10000-sum)/100)+'%')
在構建模型時我嘗試在最后一層只用一個神經元,用sigmoid激活函數,其他參數不變,在同樣epochs=20的條件,也能很快收斂,達到很高的acc,測試集的評分也能在0.9左右,但是在最后輸出全部錯誤樣本的時候發現錯誤的樣本遠超過softmax,可能其中有些參數我沒有根據sigmoid來調整,所以會有如此高的錯誤率。
以上是“python中如何實現tensorflow實現斑馬線識別功能”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





