溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python中tensorflow如何實現解貓狗識別功能,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
| train | cats:1000 ,dogs:1000 |
|---|---|
| test | cats: 500,dogs:500 |
| validation | cats:500,dogs:500 |
train_dir = 'Data/train' test_dir = 'Data/test' validation_dir = 'Data/validation' train_datagen = ImageDataGenerator(rescale=1/255, rotation_range=10, width_shift_range=0.2, #圖片水平偏移的角度 height_shift_range=0.2, #圖片數值偏移的角度 shear_range=0.2, #剪切強度 zoom_range=0.2, #隨機縮放的幅度 horizontal_flip=True, #是否進行隨機水平翻轉 # fill_mode='nearest' ) train_generator = train_datagen.flow_from_directory(train_dir, (224,224),batch_size=1,class_mode='binary',shuffle=False) test_datagen = ImageDataGenerator(rescale=1/255) test_generator = test_datagen.flow_from_directory(test_dir, (224,224),batch_size=1,class_mode='binary',shuffle=True) validation_datagen = ImageDataGenerator(rescale=1/255) validation_generator = validation_datagen.flow_from_directory( validation_dir,(224,224),batch_size=1,class_mode='binary') print(train_datagen) print(test_datagen) print(train_datagen)
我這里是將ImageDataGenerator類里的數據提取出來,將數據與標簽分別存放在兩個列表,后面在轉為np.array,也可以使用model.fit_generator,我將數據放在內存為了后續調參數時模型訓練能更快讀取到數據,不用每次訓練一整輪都去讀一次數據(應該是這樣的…我是這樣理解…)
注意我這里的數據集構建后,三種數據都是存放在內存中的,我電腦內存是16g的可以存放下。
train_data=[] train_labels=[] a=0 for data_train, labels_train in train_generator: train_data.append(data_train) train_labels.append(labels_train) a=a+1 if a>1999: break x_train=np.array(train_data) y_train=np.array(train_labels) x_train=x_train.reshape(2000,224,224,3)
test_data=[] test_labels=[] a=0 for data_test, labels_test in test_generator: test_data.append(data_test) test_labels.append(labels_test) a=a+1 if a>999: break x_test=np.array(test_data) y_test=np.array(test_labels) x_test=x_test.reshape(1000,224,224,3)
validation_data=[] validation_labels=[] a=0 for data_validation, labels_validation in validation_generator: validation_data.append(data_validation) validation_labels.append(labels_validation) a=a+1 if a>999: break x_validation=np.array(validation_data) y_validation=np.array(validation_labels) x_validation=x_validation.reshape(1000,224,224,3)
model1 = tf.keras.models.Sequential([ # 第一層卷積,卷積核為,共16個,輸入為150*150*1 tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same',input_shape=(224,224,3)), tf.keras.layers.MaxPooling2D((2,2)), # 第二層卷積,卷積核為3*3,共32個, tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same'), tf.keras.layers.MaxPooling2D((2,2)), # 第三層卷積,卷積核為3*3,共64個, tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same'), tf.keras.layers.MaxPooling2D((2,2)), # 數據鋪平 tf.keras.layers.Flatten(), tf.keras.layers.Dense(64,activation='relu'), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(1,activation='sigmoid') ]) print(model1.summary())
模型summary:
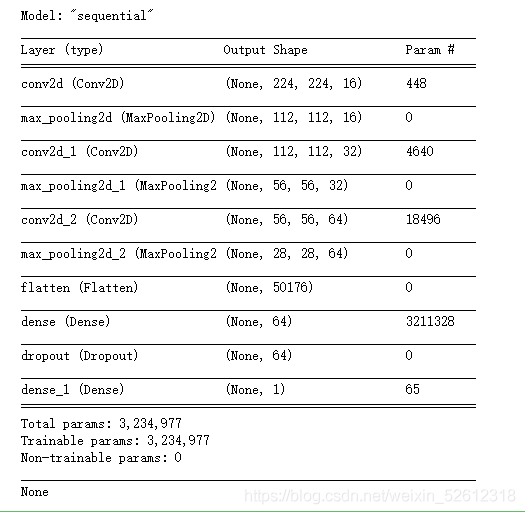
model1.compile(optimize=tf.keras.optimizers.SGD(0.00001),
loss=tf.keras.losses.binary_crossentropy,
metrics=['acc'])
history1=model1.fit(x_train,y_train,
# validation_split=(0~1) 選擇一定的比例用于驗證集,可被validation_data覆蓋
validation_data=(x_validation,y_validation),
batch_size=10,
shuffle=True,
epochs=10)
model1.save('cats_and_dogs_plain1.h6')
print(history1)
plt.plot(history1.epoch,history1.history.get('acc'),label='acc')
plt.plot(history1.epoch,history1.history.get('val_acc'),label='val_acc')
plt.title('正確率')
plt.legend()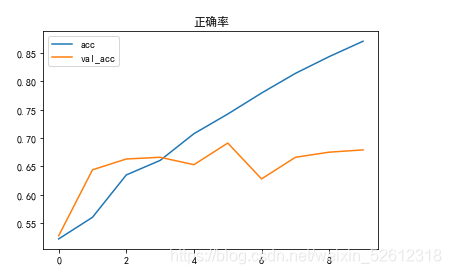
可以看到我們的模型泛化能力還是有點差,測試集的acc能達到0.85以上,驗證集卻在0.65~0.70之前跳動。
model1.evaluate(x_validation,y_validation)
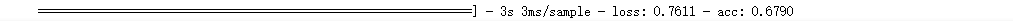
最后我們的模型在測試集上的正確率為0.67,可以說還不夠好,有點過擬合,可能是訓練數據不夠多,后續可以數據增廣或者從驗證集、測試集中調取一部分數據用于訓練模型,可能效果好一些。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“python中tensorflow如何實現解貓狗識別功能”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





