溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python中怎么實現文字識別功能,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
Ubuntu版本:
1.tesseract-ocr安裝
sudo apt-get install tesseract-ocr
2.pytesseract安裝
sudo pip install pytesseract
3.Pillow 安裝
sudo pip install pillow
開始寫代碼:
from PIL import Image
from pytesseract import pytesseract
image = Image.open('test.png')
code = pytesseract.image_to_string(image,lang='chi_sim')
print(code)報錯了:

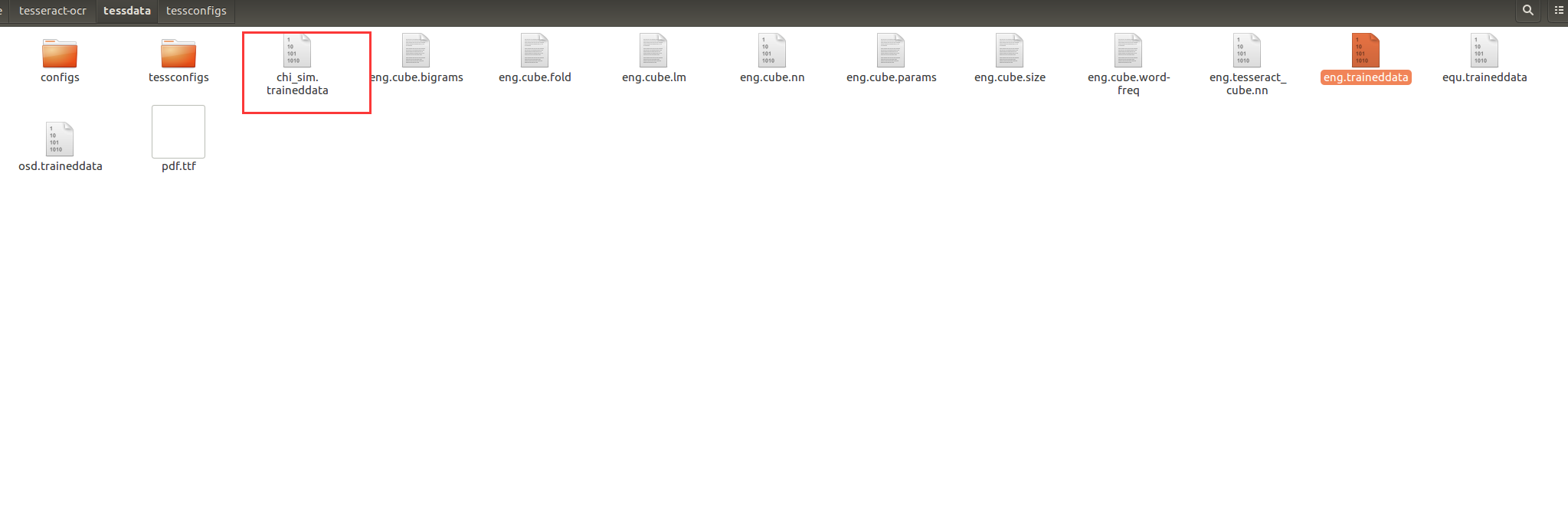
找到路徑,發現沒有chi_sim.traineddata這個訓練包
# 安裝訓練數據(equ為數學公式包) sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim tesseract-ocr-equ
安裝之后就會有訓練包了,可以正常運行。
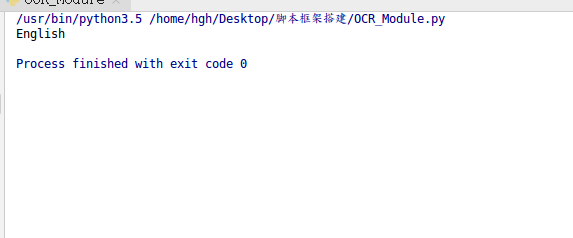
英文識別正確率較高,中文就比較雞肋了。
關于python中怎么實現文字識別功能就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





