溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“TensorFlow2.X如何利用OpenCV 實現手勢識別功能”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
使用Tensorflow 構建卷積神經網絡,訓練手勢識別模型,使用opencv DNN 模塊加載模型實時手勢識別
效果如下:
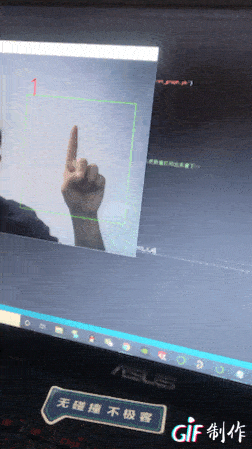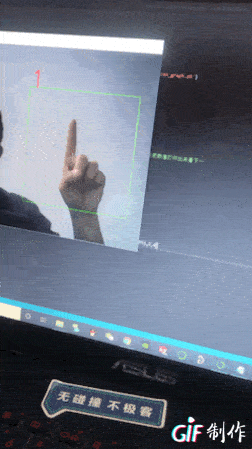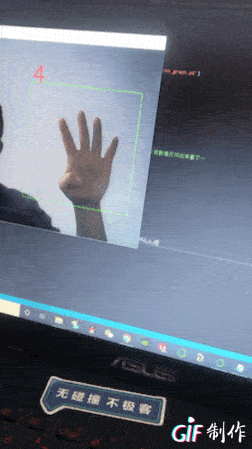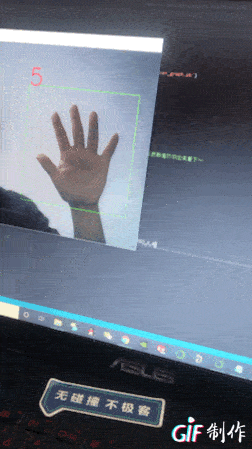
先顯示下部分數據集圖片(0到9的表示,感覺很怪)

構建模型進行訓練
數據集地址
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets,layers,optimizers,Sequential,metrics
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
import os
import pathlib
import random
import matplotlib.pyplot as plt
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def read_data(path):
path_root = pathlib.Path(path)
# print(path_root)
# for item in path_root.iterdir():
# print(item)
image_paths = list(path_root.glob('*/*'))
image_paths = [str(path) for path in image_paths]
random.shuffle(image_paths)
image_count = len(image_paths)
# print(image_count)
# print(image_paths[:10])
label_names = sorted(item.name for item in path_root.glob('*/') if item.is_dir())
# print(label_names)
label_name_index = dict((name, index) for index, name in enumerate(label_names))
# print(label_name_index)
image_labels = [label_name_index[pathlib.Path(path).parent.name] for path in image_paths]
# print("First 10 labels indices: ", image_labels[:10])
return image_paths,image_labels,image_count
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [100, 100])
image /= 255.0 # normalize to [0,1] range
# image = tf.reshape(image,[100*100*3])
return image
def load_and_preprocess_image(path,label):
image = tf.io.read_file(path)
return preprocess_image(image),label
def creat_dataset(image_paths,image_labels,bitch_size):
db = tf.data.Dataset.from_tensor_slices((image_paths, image_labels))
dataset = db.map(load_and_preprocess_image).batch(bitch_size)
return dataset
def train_model(train_data,test_data):
#構建模型
network = keras.Sequential([
keras.layers.Conv2D(32,kernel_size=[5,5],padding="same",activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
keras.layers.Conv2D(64,kernel_size=[3,3],padding="same",activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
keras.layers.Conv2D(64,kernel_size=[3,3],padding="same",activation=tf.nn.relu),
keras.layers.Flatten(),
keras.layers.Dense(512,activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(128,activation='relu'),
keras.layers.Dense(10)])
network.build(input_shape=(None,100,100,3))
network.summary()
network.compile(optimizer=optimizers.SGD(lr=0.001),
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
#模型訓練
network.fit(train_data, epochs = 100,validation_data=test_data,validation_freq=2)
network.evaluate(test_data)
tf.saved_model.save(network,'D:\\code\\PYTHON\\gesture_recognition\\model\\')
print("保存模型成功")
# Convert Keras model to ConcreteFunction
full_model = tf.function(lambda x: network(x))
full_model = full_model.get_concrete_function(
tf.TensorSpec(network.inputs[0].shape, network.inputs[0].dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
layers = [op.name for op in frozen_func.graph.get_operations()]
print("-" * 50)
print("Frozen model layers: ")
for layer in layers:
print(layer)
print("-" * 50)
print("Frozen model inputs: ")
print(frozen_func.inputs)
print("Frozen model outputs: ")
print(frozen_func.outputs)
# Save frozen graph from frozen ConcreteFunction to hard drive
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="D:\\code\\PYTHON\\gesture_recognition\\model\\frozen_model\\",
name="frozen_graph.pb",
as_text=False)
print("模型轉換完成,訓練結束")
if __name__ == "__main__":
print(tf.__version__)
train_path = 'D:\\code\\PYTHON\\gesture_recognition\\Dataset'
test_path = 'D:\\code\\PYTHON\\gesture_recognition\\testdata'
image_paths,image_labels,_ = read_data(train_path)
train_data = creat_dataset(image_paths,image_labels,16)
image_paths,image_labels,_ = read_data(test_path)
test_data = creat_dataset(image_paths,image_labels,16)
train_model(train_data,test_data)OpenCV加載模型,實時檢測
這里為了簡化檢測使用了ROI。
import cv2
from cv2 import dnn
import numpy as np
print(cv2.__version__)
class_name = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
net = dnn.readNetFromTensorflow('D:\\code\\PYTHON\\gesture_recognition\\model\\frozen_model\\frozen_graph.pb')
cap = cv2.VideoCapture(0)
i = 0
while True:
_,frame= cap.read()
src_image = frame
cv2.rectangle(src_image, (300, 100),(600, 400), (0, 255, 0), 1, 4)
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
pic = frame[100:400,300:600]
cv2.imshow("pic1", pic)
# print(pic.shape)
pic = cv2.resize(pic,(100,100))
blob = cv2.dnn.blobFromImage(pic,
scalefactor=1.0/225.,
size=(100, 100),
mean=(0, 0, 0),
swapRB=False,
crop=False)
# blob = np.transpose(blob, (0,2,3,1))
net.setInput(blob)
out = net.forward()
out = out.flatten()
classId = np.argmax(out)
# print("classId",classId)
print("預測結果為:",class_name[classId])
src_image = cv2.putText(src_image,str(classId),(300,100), cv2.FONT_HERSHEY_SIMPLEX, 2,(0,0,255),2,4)
# cv.putText(img, text, org, fontFace, fontScale, fontcolor, thickness, lineType)
cv2.imshow("pic",src_image)
if cv2.waitKey(10) == ord('0'):
break小結
這里本質上還是一個圖像分類任務。而且,樣本數量較少。優化的時候需要做數據增強,還需要防止過擬合。
“TensorFlow2.X如何利用OpenCV 實現手勢識別功能”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





