溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
背景
一般大公司的機器學習團隊,才會嘗試構建大規模機器學習模型,如果去看百度、頭條、阿里等分享,都有提到過這類模型。當然,大家現在都在說深度學習,但在推薦、搜索的場景,據我所知,ROI并沒有很高,大家還是參考wide&deep的套路做,其中的deep并不是很deep。而大規模模型,是非常通用的一套框架,這套模型的優點是一種非常容易加特征,所以本質是拼特征的質和量,比如百度、頭條號稱特征到千億規模。可能有些朋友不太了解大規模特征是怎么來的,舉個簡單的例子,假設你有百萬的商品,然后你有幾百個用戶側的profile,二者做個交叉特征,很容易規模就過10億。特征規模大了之后,需要PS才能訓練,這塊非常感謝騰訊開源了Angel,拯救了我們這種沒有足夠資源的小公司,我們的實踐效果非常好。
網上有非常多介紹大規模機器學習的資料,大部分的內容都集中在為何要做大規模機器學習模型以及Parameter Server相關的資料,但我們在實際實踐中,發現大規模的特征預處理也有很多問題需要解決。有一次和明風(以前在阿里,后來去了騰訊做了開源的PS:angel)交流過這部分的工作為何沒有人開源,結論大致是這部分的工作和業務相關性大,且講明白了技術亮點不多,屬于苦力活,所以沒有開源的動力。
本文總結了蘑菇街搜索推薦在實踐大規模機器學習模型中的特征處理系統的困難點。我們的技術選型是spark,雖然spark的機器學習部分不能支持大規模(我們的經驗是LR模型的特征大概能到3000w的規模),但是它非常適合做特征處理。非常感謝組里的小伙伴@玄德 貢獻此文。
整體流程圖
這套方法論的特點是,雖然特征規模很大,但是非常稀疏。我們對特征集合進行onehot編碼,每條樣本的存儲需求很小。由于規模太大,編碼就變成一個比較嚴峻的問題。
連續統計類特征:電商領域里面,統計的ctr、gmv是非常重要的特征。
特征構建遇到的問題
1. 特征值替換成對應的數值索引過慢
組合后的訓練樣例中的特征值需要替換成對應的數值索引,生成onehot的特征格式。
特征索引映射表1的格式如下:
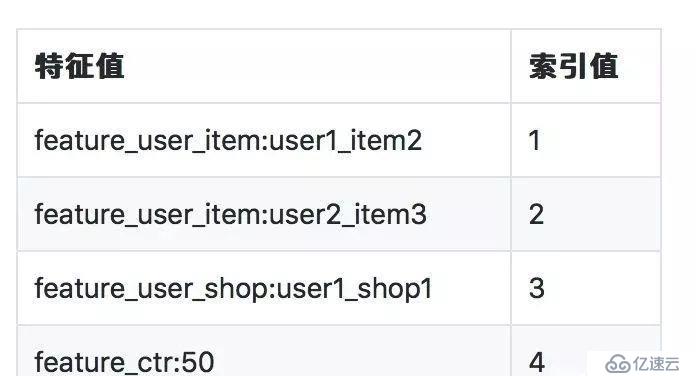
為了實現這種計算,我們需要對所有的特征做unique編碼,然后將這個索引表join回原始的日志表,替換原始特征,后續流程使用編碼的值做onehot,但這部分容易OOM,且性能有問題。于是我們著手優化這個過程.
首先我們想到的點是將索引表廣播出去, 這樣就不用走merge join, 不用對樣例表進行shuffle操作,索引表在比較小的時候,大概是4KW的規模, 廣播出去是沒有問題的,實際內部實現走的是map-side join, 所以速度也是非常快的, 時間減少到一個小時內.
當索引表規模達到5KW的時候,直接整表廣播, driver端gc就非常嚴重了, executor也非常不穩定, 當時比較費解, 單獨把這部分數據加載到內存里面, 占用量只有大約executor內存的20%左右,為啥gc會這么嚴重呢?后面去看了下saprk的原理,解決了心中的疑惑. 因為spark2.x已經移除HTTPBroadcast, 僅有的一種實現是TorrentBroadcast.實現原理類似于大家常用的 BT下載技術。基本思想就是將數據分塊成 data blocks,如果executor 取到了一些 data blocks,那么這個 executor 就可以被當作 data server 了,隨著取到數據的 executor 越來越多,有更多的 data server 加入,數據就很快能傳播到全部的 executor 那里去了.
在廣播的過程中會將數據冗余一份到blockManager,供其他executor進行讀取. 其原理如圖所示:
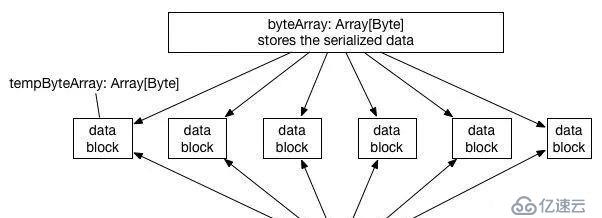
在廣播的過程中, driver端和executor端都會有短暫的時間達到2倍的內存占用。
dirver端
driver端先把數據序列成byteArray, 切割成小塊的data block再廣播出去, 切割的過程,內存會不斷接近2倍byteArray的大小, 直到切割完之后,將byteArray釋放掉.
executor端
executor裝載廣播的數據是driver的反過程, 每次拿到一個data block之后, 就將其存放到blockManager, 同時通知driver的blockManagerMaster說這個block多了一個存儲的地方,供其他executor下載.等executor把所有的block都從其他地方拿全之后,先申請一個Array[Byte],將block的數據進行反序列化之后得到原始數據.這個過程中和driver端應用,內存會不斷接近2倍數據的大小, 直到反序列化完成.
通過了解了spark廣播的實現, 可以解釋廣播5kw維特征的gc嚴重的問題.
隨著實驗特征的迭代,表2的列數會不斷的增多,處理時間會隨著列數的增多而線性增加, 特征索引的規模增多,會導致廣播的過程中gc問題越來越嚴重, 直到OOM頻繁出現.
這個階段需要解決2個問題
1.需要高效得將表1的數據廣播到各個executor
2.不能使用join列的方式來實現替換索引值
綜合這兩個問題, 我們想出了一個解決方案, 將表1先按照特征值排好序, 然后再重新編碼, 用一個長度為max(索引值)長度的數組去存儲, 索引值作為下標,對應的元素為特征值,將其廣播到executor之后, 遍歷日志的每一行的每一列, 實際上就是對應的特征值, 去上面的數組中二分查找出對應的索引值并替換掉.
使用下標數據存儲表1, 特征值按照平均長度64個字符計算, 每個字符占用1個字節, 5千萬維特征需要3.2G內存,廣播的實際表現ok,1億維特征的話需要占用6.4G內存, 按照廣播的時候會有雙倍內存占用的情況,gc會比較嚴重. 我們又想了一個辦法, 將字符串hash成long,long僅占用8字節,比起存儲字符串來說大大節省了空間, hash的有個問題是可能會沖突, 由于8字節的hash映射空間有 -2^63 到 2^63-1, 我們使用的是BKDRHash, 實際測下來沖突率很少,在業務可接受的范圍, 這個方法可以大大節省占用的內存,1億特征僅占用800M的內存, 廣播起來毫無壓力,對應的在遍歷表2的時候, 需要先將特征值用同樣的算法hash之后再進行查找. 經過這一輪優化之后, 相同資源的情況下,處理10億行, 5KW維特征的時候, 耗時已經降低到半個小時了, 且內存情況相對穩定.
這種情況跑了一段時間之后, 特征規模上到億了, 發現這一步的耗時已經上升到45分鐘了,分析了下特征的分布,發現連續特征離散化的特征在日志出現的頻率很高,由于是連續統計值,本身非常稠密,基本每一條數據都有其出現,但是這類特征在表1的分布不多, 這完全可以利用緩存把這類特征對應的索引值保存下來, 而沒必要走hash之后再二分搜索,完全可以用少量的空間節省大量的時間. 實際實現的時候,判斷需要查找的特征值是否符合以上的這種情況, 如果符合的話, 直接用guava緩存表2的特征值->表1的索引值,實際統計的緩存命中率是99.98888%, 實際耗時下降得也很明顯, 從之前的45分鐘降到17分鐘.當然緩存并不是銀彈,在算hash的時候誤用了緩存, 導致這一步的計算反而變得慢了, 因為hash的組合實在是太多了, 緩存命中率只有10%左右, 而且hash計算復雜度并不高.在實際使用緩存的時候, 有必要去統計一下緩存的命中率.
2. Spark的一些經驗
1.利用好spark UI的SQL預覽, 做類似特征處理的ETL任務多關注下SQL, 做這類特征處理的工作的時候, 這個功能絕對是一把利器, 前期實現時間比較趕, 測試用例比較少, 在查實際運行邏輯錯誤的問題時, 可以利用前期對數據的分析結論結合SQL選項的流程圖來定位數據出錯的位置.
2.利用spark UI找出傾斜的任務,找到耗時比較長的Stages, 點進去看Aggregated Metrics by Executor
3.對單個task可以不用太關注, 如果某些Executor的耗時比起其他明顯多了,一般都是數據清洗導致的(不排除某些慢節點)
4.利用UI確認是否需要緩存, 如果一個任務重復步驟非常頻繁的,且任務的數據本地性都是RACK_LOCAL的 則要考慮將其上游結果緩存下來. 比如我們這里會統計單列特征的頻次的時候
5.會將上游數據緩存下來, 但是數據量相對比較大, 我們選擇將其緩存到磁盤,spark實現的自動分配內存和磁盤的方法有點問題,不知道是我們的姿勢問題還是他的實現有bug。
生產版本小結
億級別特征維度,幾十億樣本(對全樣本做了采樣,效果損失不明顯),二十分鐘左右跑完。不過這個時間數據參考意義不大,和跑的資源和機器性能有關,而大廠在這塊優勢太大了。而本文核心解決的點是特征處理過程中,特征編碼的索引達到億級別時,數據處理性能差或者spark OOM的問題。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





