溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者 | 姚捷(嘍哥)阿里云容器平臺集群管理高級技術專家
本文節選自《不一樣的 雙11 技術:阿里巴巴經濟體云原生實踐》一書,點擊即可完成下載。
cdn.com/2d3f2c0a733aa3bc75c82319f10a13c2f82b3771.jpeg">
導讀:值得阿里巴巴技術人驕傲的是 2019 年阿里巴巴 雙11?核心系統 100% 以云原生的方式上云,完美支撐了?54.4w 峰值流量以及?2684 億的成交量。背后承載海量交易的計算力就是來源于容器技術與神龍裸金屬的完美融合。
阿里巴巴 雙11 采用三地五單元架構,除 2 個混部單元外,其他 3 個均是云單元。神龍機型經過 618、99 大促的驗證,性能和穩定性已大幅提升,可以穩定支撐 雙11。今年 雙11 的 3 個交易云單元,已經 100% 基于神龍裸金屬,核心交易電商神龍集群規模已達到數萬臺。
阿里云 ECS 虛擬化技術歷經三代,前二代是 Xen 與 KVM,神龍是阿里巴巴自研的第三代 ECS 虛擬化技術產品,它具備以下四大技術特征:
簡而言之,神龍將網絡/存儲的虛擬化開銷 offload 到一張叫 MOC 卡的 FPGA 硬件加速卡上,降低了原 ECS 約 8% 的計算虛擬化的開銷,同時通過大規模 MOC 卡的制造成本優勢,攤平了神龍整體的成本開銷。神龍類物理機特性,可進行二次虛擬化,使得對于新技術的演進發展留足了空間,對于采用一些多樣的虛擬化的技術,像 Kata、Firecracker 等成為了可能。
在阿里巴巴 雙11 大規模遷移到神龍架構前,通過在 618/99 大促的驗證,我們發現集團電商的容器運行在云上神龍反而比非云物理機的性能要好 10%~15%,這令我們非常詫異。經過分析,我們發現主要是因為虛擬化開銷已經 offload 到 MOC?卡上,神龍的 CPU/Mem 是無虛擬化開銷的,而上云后運行在神龍上的每個容器都獨享 ENI 彈性網卡,性能優勢明顯。同時每個容器獨享一塊 ESSD 塊存儲云盤,單盤 IOPS 高達 100 萬,比 SSD 云盤快 50 倍,性能超過了非云的 SATA 和 SSD 本地盤。這也讓我們堅定了大規模采用神龍來支撐 雙11 的決心。
在 All in Cloud 的時代企業 IT 架構正在被重塑,而云原生已經成為釋放云計算價值的最短路徑。2019 年阿里巴巴 雙11 核心系統 100% 以云原生的方式上云,基于神龍服務器、輕量級云原生容器以及兼容 Kubernetes?的調度的新的 ASI(alibaba serverless infra.)調度平臺。其中 Kubernetes Pod 容器運行時與神龍裸金屬完美融合,Pod 容器作為業務的交付切面,運行在神龍實例上。
下面是 Pod 運行在神龍上的形態:
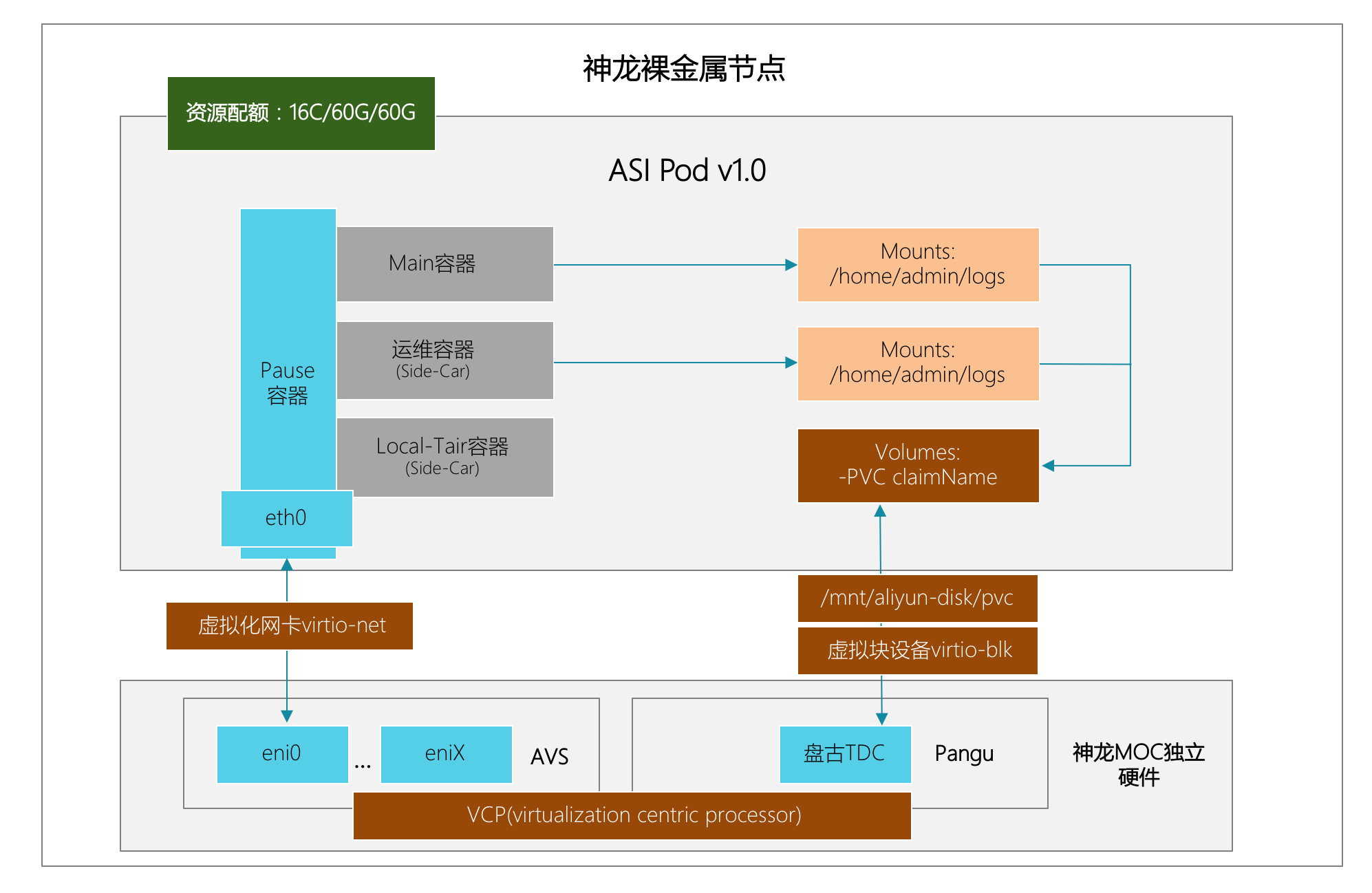
2019 年 雙11 云上核心交易的神龍集群規模已達到數萬臺,管理和運維如此大規模神龍集群極具挑戰,這其中包括云上各類業務實例規格的選擇、大規模集群彈性擴縮容、節點資源劃分與管控、核心指標統計分析、基礎環境監控、宕機分析、節點標簽管理、節點重啟/鎖定/釋放、節點自愈、故障機輪轉、內核補丁升級、大規模巡檢等能力建設。
下面就幾個領域細化展開:
首先需要針對不同類型業務規劃不同的實例規格,包括入口層、核心業務系統、中間件、數據庫、緩存服務這些不同特性的基礎設施和業務,有些需要高性能的計算、有些需要高網絡收發包能力,有些需要高性能的磁盤讀寫能力。在前期需要系統性整體規劃,避免實例規格選擇不當影響業務性能和穩定性。實例規格的核心配置參數包括 vcpu、內存、彈性網卡數,云盤數、系統盤大小、數據盤大小、網絡收發包能力 (PPS)。
電商核心系統應用的主力機型為 96C/527G,每個 Kubernetes Pod 容器占用一塊彈性網卡和一塊 EBS 云盤,所以彈性網卡和云盤的限制數非常關鍵,此次電商上云,神龍將彈性網卡和 EBS 云盤的限制數提高到?64 與 40,有效避免了 CPU 與內存的資源浪費。另外對于不同類型的業務,核心配置也會略有差異,例如入口層 aserver 神龍實例由于需要承擔大量的入口流量,對 MOC 的網絡收發包能力的要求極高,為避免 AVS 網絡軟交換 CPU 打滿,對于神龍 MOC 卡里的網絡和存儲的 CPU 分配參數的需求不同,常規計算型神龍實例的 MOC 卡網絡/存儲的 CPU 分配是 4+8,而 aserver 神龍實例需要配置為 6:6;例如對于云上混部機型,需要為離線任務提供獨立的 nvme 本盤實例。為不同類型業務合理規劃機型和規格,會極大程度的降低成本,保證性能和穩定性。
雙11 需要海量的計算資源來扛住洪峰流量,但這部分資源不可能常態化持有,所以需要合理劃分日常集群與大促集群,并在 雙11 前幾周,通過大規模節點彈性擴容能力,從阿里云彈性申請大批量神龍,部署在獨立的大促集群分組里,并大規模擴容 Kubernetes Pod 交付業務計算資源。在 雙11 過后,立即將大促集群中的 Pod 容器批量縮容下線,大促集群神龍實例整體銷毀下線,日常只持有常態化神龍實例,通過大規模集群彈性擴縮容能力,可大幅節約大促成本。另外從神龍交付周期而言,今年上云后從申請到創建機器,從小時/天級別縮短到了分鐘級,上千臺神龍可在 5 分鐘內完成申請,包括計算、網絡、存儲資源;在 10 分鐘內完成創建并導入 Kubernetes 集群,集群創建效率大幅度提高,為未來常態化彈性資源池奠定基礎。
對于大規模神龍集群運維,有三個非常核心的指標可以來衡量集群整體健康度,分別是宕機率、可調度率、在線率。
云上神龍宕機原因通常分為硬件問題和內核問題。通過對日宕機率趨勢統計和宕機根因分析,可量化集群的穩定性,避免出現潛在的大規模宕機風險出現。可調度率是衡量集群健康度的關鍵指標,集群機器會因為各種軟硬件原因出現容器無法調度到這些異常機器上,例如 Load 大于 1000、磁盤出現壓力、docker 進程不存在,kubelet 進程不存在等,在 Kubernetes?集群中,這批機器的狀態會是 notReady。2019 年 雙11,我們通過神龍宕機重啟與冷遷移特性,極大提升了故障機輪轉效率,使神龍集群的可調度率始終維持在 98% 以上,大促資源備容從容。而 雙11 神龍的宕機率維持在?0.2‰ 以下,表現相當穩定。
隨著集群規模的增加,管理難度也隨之變大。例如如何能篩選出 "cn-shanghai"Region 下生產環境,且實例規格為 "ecs.ebmc6-inc.26xlarge" 的所有機器。我們通過定義大量的預置標簽來實現批量資源管理。在 Kubernetes 架構下,通過定義 Label 來管理機器。Label 是一個 Key-Value 健值對,可在神龍節點上使用標準 Kubernetes 的接口打 Label。例如機器實例規格的 Label 可定義 "sigma.ali/machine-model":"ecs.ebmc6-inc.26xlarge", 機器所在的 Region 可定義為?"sigma.ali/ecs-region-id":"cn-shanghai"。通過完善的標簽管理系統,可從幾萬臺神龍節點中快速篩選機器,執行諸如灰度分批次服務發布、批量重啟、批量釋放等常規運維操作。
對于超大規模集群,日常宕機是非常普遍的事情,對宕機的統計與分析非常關鍵,可以甄別出是否存在系統性風險。宕機的情況分為很多種,硬件故障會導致宕機,內核的 bug 等也會導致宕機,一旦宕機以后,業務就會中斷,有些有狀態應用就會受到影響。我們通過 ssh 與端口 ping 巡檢對資源池的宕機情況進行了監控,統計宕機歷史趨勢,一旦有突增的宕機情況就會報警;同時對宕機的機器進行關聯分析,如根據機房、環境、單元、分組 進行歸類,看是否跟某個特定的機房有關;對機型、CPU 進行分類統計,看是否跟特定的硬件有關系;同時 OS 版本、內核版本進行歸類,看是否都發生在某些特定的內核上。
對宕機的根因,也進行了綜合的分析,看是硬件故障,還是有主動運維事件。內核的 kdump 機制會在發生 crash 的時候生成 vmcore,我們也對 vmcore 里面提取的信息進行歸類,看某一類特定的 vmcore 關聯的宕機數有多少。內核日志有些出錯的信息,如 mce 日志、soft lockup 的出錯信息等,也能發現系統在宕機前后是否有異常。
通過這一系列的宕機分析工作,把相應的問題提交給內核團隊,內核專家就會分析 vmcore,屬于內核的缺陷會給出 hotfix 解決這些導致宕機的問題。
運維大規模神龍集群不可避免地會遇到軟硬件故障,而在云上技術棧更厚,出現問題會更為復雜。如果出問題單純依靠人工來處理是不現實的,必須依賴自動化能力來解決。1-5-10 節點自愈可提供 1 分鐘異常問題發現,5 分鐘定位,10 分鐘修復的能力。主要的神龍機器異常包括宕機、夯機、主機 load 高、磁盤空間滿、too many openfiles、核心服務(Kubelet、Pouch、Star-Agent)不可用等。主要的修復動作包括宕機重啟、業務容器驅逐、異常軟件重啟、磁盤自動清理,其中 80% 以上的問題可通過重啟宕機機器與將業務容器驅逐到其他節點完成節點自愈。另外我們通過監聽神龍?Reboot 重啟與 Redepoly 實例遷移兩個系統事件來實現 NC 側系統或硬件故障的自動化修復。
2020 年 雙11,阿里巴巴經濟體基礎設施將會 100% 基于 Kubernetes,基于 runV 安全容器的下一代混部架構將會大規模落地,輕量化容器架構會演進到下一階段。
在此大背景下,一方面 Kubernetes 節點管理將會朝向阿里巴巴經濟體并池管理方向發展,打通云庫存管理,提升節點彈性能力,根據業務特性錯峰資源利用,進一步降低機器持有時間從而大幅降低成本。
在技術目標上,我們會采用基于?Kubernetes Machine-Operator 的核心引擎,提供高度靈活的節點運維編排能力,支持節點運維狀態的終態維持。另一方面,基于完整的全域數據采集和分析能力,提供極致的全鏈路監控/分析/內核診斷能力,全面提升容器基礎環境的穩定性,為輕量化容器/不可變基礎設施架構演進提供極致性能觀測與診斷的技術保障。<br />

雙11 的 2684 億成交額背后是對一個個技術問題的反復嘗試與實踐。
這一次,我們對云原生技術在 雙11 的實踐細節進行深挖,篩選了其中 22 篇有代表性的文章進行重新編排,整理成《不一樣的 雙11 技術:阿里巴巴經濟體云原生實踐》一書。
將為你帶來不一樣的 雙11 云原生技術亮點:
“阿里巴巴云原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦云原生流行技術趨勢、云原生大規模的落地實踐,做最懂云原生開發者的技術公眾號。”
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





