溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
貸前系統負責從進件到放款前所有業務流程的實現,其中涉及一些數據量較大、條件多樣且復雜的綜合查詢,引入ElasticSearch主要是為了提高查詢效率,并希望基于ElasticSearch快速實現一個簡易的數據倉庫,提供一些OLAP相關功能。本文將介紹貸前系統ElasticSearch的實踐經驗。
描述:為快速定位數據而設計的某種數據結構。
索引好比是一本書前面的目錄,能加快數據庫的查詢速度。了解索引的構造及使用,對理解ES的工作模式有非常大的幫助。
常用索引:
位圖索引
哈希索引
BTREE索引
位圖索引適用于字段值為可枚舉的有限個數值的情況。
位圖索引使用二進制的數字串(bitMap)標識數據是否存在,1標識當前位置(序號)存在數據,0則表示當前位置沒有數據。
下圖1 為用戶表,存儲了性別和婚姻狀況兩個字段;
圖2中分別為性別和婚姻狀態建立了兩個位圖索引。
例如:性別->男 對應索引為:101110011,表示第1、3、4、5、8、9個用戶為男性。其他屬性以此類推。

使用位圖索引查詢:
男性 并且已婚 的記錄 = 101110011 & 11010010 = 100100010,即第1、4、8個用戶為已婚男性。
顧名思義,是指使用某種哈希函數實現key->value 映射的索引結構。
哈希索引適用于等值檢索,通過一次哈希計算即可定位數據的位置。
下圖3 展示了哈希索引的結構,與JAVA中HashMap的實現類似,是用沖突表的方式解決哈希沖突的。

BTREE索引是關系型數據庫最常用的索引結構,方便了數據的查詢操作。
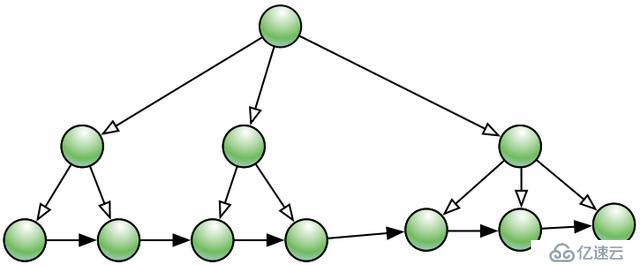
BTREE: 有序平衡N階樹, 每個節點有N個鍵值和N+1個指針, 指向N+1個子節點。
一棵BTREE的簡單結構如下圖4所示,為一棵2層的3叉樹,有7條數據:

以Mysql最常用的InnoDB引擎為例,描述下BTREE索引的應用。
Innodb下的表都是以索引組織表形式存儲的,也就是整個數據表的存儲都是B+tree結構的,如圖5所示。
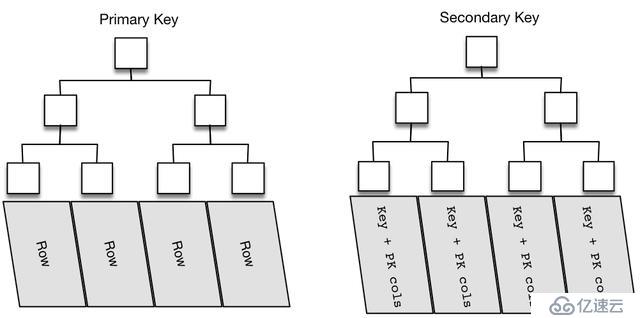
主鍵索引為圖5的左半部分(如果沒有顯式定義自主主鍵,就用不為空的唯一索引來做聚簇索引,如果也沒有唯一索引,則innodb內部會自動生成6字節的隱藏主鍵來做聚簇索引),葉子節點存儲了完整的數據行信息(以主鍵 + row_data形式存儲)。
二級索引也是以B+tree的形式進行存儲,圖5右半部分,與主鍵不同的是二級索引的葉子節點存儲的不是行數據,而是索引鍵值和對應的主鍵值,由此可以推斷出,二級索引查詢多了一步查找數據主鍵的過程。
維護一顆有序平衡N叉樹,比較復雜的就是當插入節點時節點位置的調整,尤其是插入的節點是隨機無序的情況;而插入有序的節點,節點的調整只發生了整個樹的局部,影響范圍較小,效率較高。
可以參考紅黑樹的節點的插入算法:
https://en.wikipedia.org/wiki/Red%E2%80%93black_tree
因此如果innodb表有自增主鍵,則數據寫入是有序寫入的,效率會很高;如果innodb表沒有自增的主鍵,插入隨機的主鍵值,將導致B+tree的大量的變動操作,效率較低。這也是為什么會建議innodb表要有無業務意義的自增主鍵,可以大大提高數據插入效率。
注:
Mysql Innodb使用自增主鍵的插入效率高。
倒排索引也叫反向索引,可以相對于正向索引進行比較理解。
正向索引反映了一篇文檔與文檔中關鍵詞之間的對應關系;給定文檔標識,可以獲取當前文檔的關鍵詞、詞頻以及該詞在文檔中出現的位置信息,如圖6 所示,左側是文檔,右側是索引。

反向索引則是指某關鍵詞和該詞所在的文檔之間的對應關系;給定了關鍵詞標識,可以獲取關鍵詞所在的所有文檔列表,同時包含詞頻、位置等信息,如圖7所示。

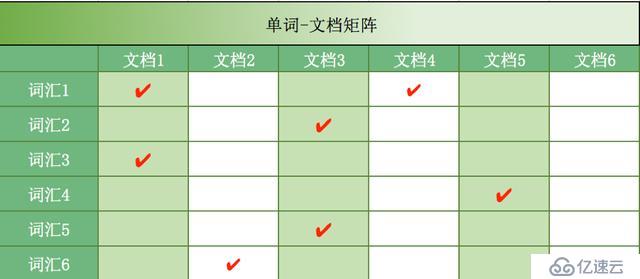
反向索引(倒排索引)的單詞的集合和文檔的集合就組成了如圖8所示的”單詞-文檔矩陣“,打鉤的單元格表示存在該單詞和文檔的映射關系。
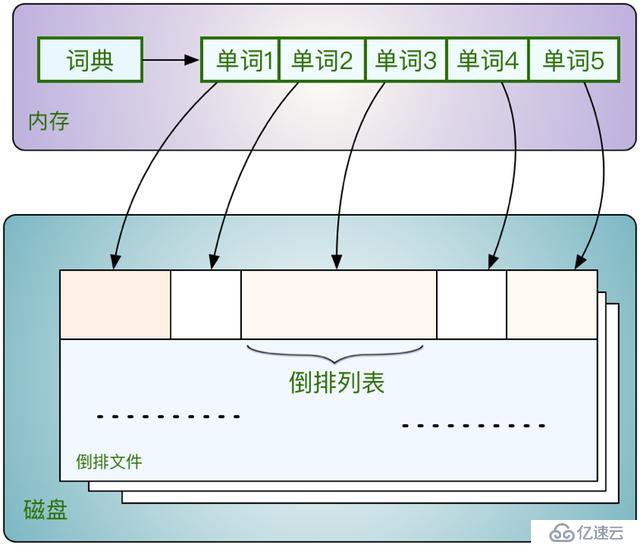
倒排索引的存儲結構可以參考圖9。其中詞典是存放的內存里的,詞典就是整個文檔集合中解析出的所有單詞的列表集合;每個單詞又指向了其對應的倒排列表,倒排列表的集合組成了倒排文件,倒排文件存放在磁盤上,其中的倒排列表內記錄了對應單詞在文檔中信息,即前面提到的詞頻、位置等信息。
下面以一個具體的例子來描述下,如何從一個文檔集合中生成倒排索引。
如圖10,共存在5個文檔,第一列為文檔編號,第二列為文檔的文本內容。

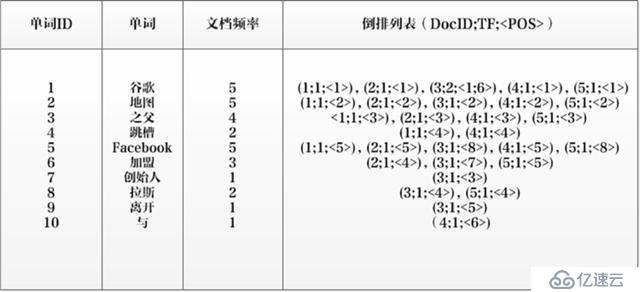
將上述文檔集合進行分詞解析,其中發現的10個單詞為:[谷歌,地圖,之父,跳槽,Facebook,×××,創始人,拉斯,離開,與],以第一個單詞”谷歌“為例:首先為其賦予一個唯一標識 ”單詞ID“, 值為1,統計出文檔頻率為5,即5個文檔都有出現,除了在第3個文檔中出現2次外,其余文檔都出現一次,于是就有了圖11所示的倒排索引。
對于一個規模很大的文檔集合來說,可能包含幾十萬甚至上百萬的不同單詞,能否快速定位某個單詞,這直接影響搜索時的響應速度,其中的優化方案就是為單詞詞典建立索引,有以下幾種方案可供參考:
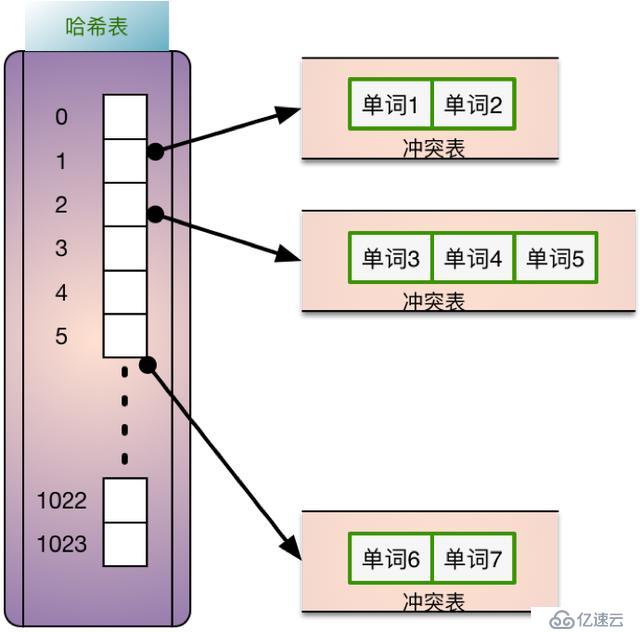
Hash索引簡單直接,查詢某個單詞,通過計算哈希函數,如果哈希表命中則表示存在該數據,否則直接返回空就可以;適合于完全匹配,等值查詢。如圖12,相同hash值的單詞會放在一個沖突表中。
類似于Innodb的二級索引,將單詞按照一定的規則排序,生成一個BTree索引,數據節點為指向倒排索引的指針。
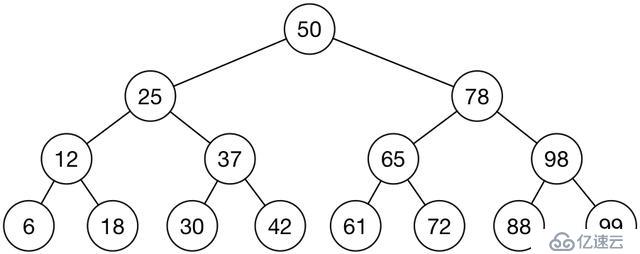
同樣將單詞按照一定的規則排序,建立一個有序單詞數組,在查找時使用二分查找法;二分查找法可以映射為一個有序平衡二叉樹,如圖14這樣的結構。
FST為一種有限狀態轉移機,FST有兩個優點:1)空間占用小。通過對詞典中單詞前綴和后綴的重復利用,壓縮了存儲空間;2)查詢速度快。O(len(str))的查詢時間復雜度。
以插入“cat”、 “deep”、 “do”、 “dog” 、“dogs”這5個單詞為例構建FST(注:必須已排序)。
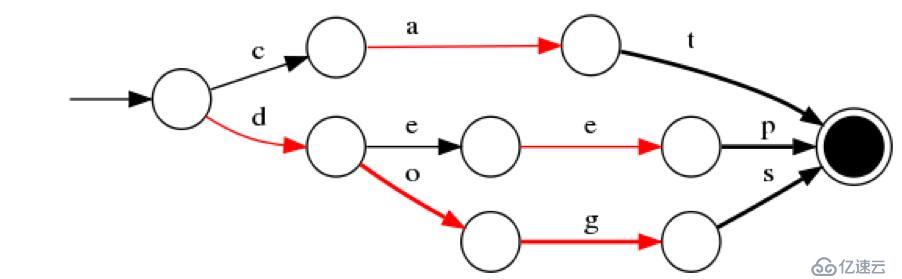
如圖15 最終我們得到了如上一個有向無環圖。利用該結構可以很方便的進行查詢,如給定一個詞 “dog”,我們可以通過上述結構很方便的查詢存不存在,甚至我們在構建過程中可以將單詞與某一數字、單詞進行關聯,從而實現key-value的映射。
當然還有其他的優化方式,如使用Skip List、Trie、Double Array Trie等結構進行優化,不再一一贅述。
下面結合貸前系統具體的使用案例,介紹ES的一些心得總結。
目前使用的ES版本:5.6
官網地址:https://www.elastic.co/products/elasticsearch
ES一句話介紹:The Heart of the Elastic Stack(摘自官網)
ES的一些關鍵信息:
2010年2月首次發布
Elasticsearch Store, Search, and Analyze
ES的索引,也就是Index,和前面提到的索引并不是一個概念,這里是指所有文檔的集合,可以類比為RDB中的一個數據庫。
即寫入ES的一條記錄,一般是JSON形式的。
文檔數據結構的元數據描述,一般是JSON schema形式,可動態生成或提前預定義。
由于理解和使用上的錯誤,type已不推薦使用,目前我們使用的ES中一個索引只建立了一個默認type。
一個ES的服務實例,稱為一個服務節點。為了實現數據的安全可靠,并且提高數據的查詢性能,ES一般采用集群模式進行部署。
多個ES節點相互通信,共同分擔數據的存儲及查詢,這樣就構成了一個集群。
分片主要是為解決大量數據的存儲,將數據分割為若干部分,分片一般是均勻分布在各ES節點上的。需要注意:分片數量無法修改。
分片數據的一份完全的復制,一般一個分片會有一個副本,副本可以提供數據查詢,集群環境下可以提高查詢性能。
JDK版本: JDK1.8
安裝過程比較簡單,可參考官網:下載安裝包 -> 解壓 -> 運行
ES啟動占用的系統資源比較多,需要調整諸如文件句柄數、線程數、內存等系統參數,可參考下面的文檔。
http://www.cnblogs.com/sloveling/p/elasticsearch.html
下面以一些具體的操作介紹ES的使用:
初始化索引,主要是在ES中新建一個索引并初始化一些參數,包括索引名、文檔映射(Mapping)、索引別名、分片數(默認:5)、副本數(默認:1)等,其中分片數和副本數在數據量不大的情況下直接使用默認值即可,無需配置。
下面舉兩個初始化索引的方式,一個使用基于Dynamic Template(動態模板) 的Dynamic Mapping(動態映射),一個使用顯式預定義映射。
1) 動態模板 (Dynamic Template)
<p ><span >curl -X PUT http://ip:9200/loan_idx -H 'content-type: application/json' <br> -d '{"mappings":{ "order_info":{ "dynamic_date_formats":["yyyy-MM-dd HH:mm:ss||yyyy-MM-dd],<br> "dynamic_templates":[<br> {"orderId2":{<br> "match_mapping_type":"string",<br> "match_pattern":"regex",<br> "match":"^orderId$",<br> "mapping":{<br> "type":"long"<br> }<br> }<br> },<br> {"strings_as_keywords":{<br> "match_mapping_type":"string",<br> "mapping":{<br> "type":"keyword",<br> "norms":false<br> }<br> }<br> }<br> ]<br> }<br>},<br>"aliases":{<br> "loan_alias":{}<br>}}'<br></span></p>上面的JSON串就是我們用到的動態模板,其中定義了日期格式:dynamic_date_formats 字段;定義了規則orderId2:凡是遇到orderId這個字段,則將其轉換為long型;定義了規則strings_as_keywords:凡是遇到string類型的字段都映射為keyword類型,norms屬性為false;關于keyword類型和norms關鍵字,將在下面的數據類型小節介紹。
2)預定義映射
預定義映射和上面的區別就是預先把所有已知的字段類型描述寫到mapping里,下圖截取了一部分作為示例:
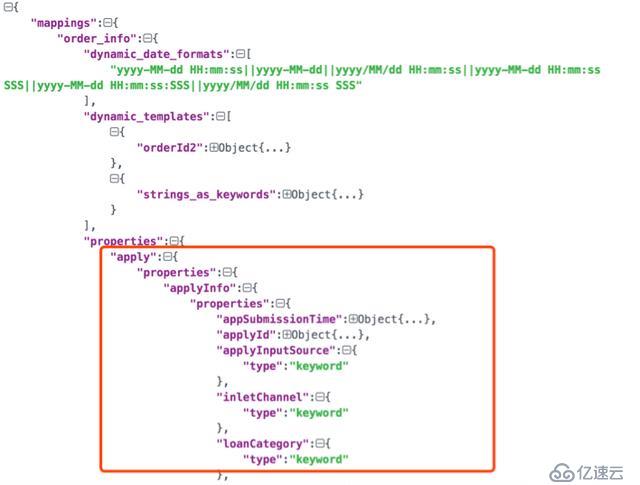
圖16中JSON結構的上半部分與動態模板相同,紅框中內容內容為預先定義的屬性:apply.applyInfo.appSubmissionTime, apply.applyInfo.applyId, apply.applyInfo.applyInputSource等字段,type表明了該字段的類型,映射定義完成后,再插入的數據必須符合字段定義,否則ES將返回異常。
常用的數據類型有text, keyword, date, long, double, boolean, ip
實際使用中,將字符串類型定義為keyword而不是text,主要原因是text類型的數據會被當做文本進行語法分析,做一些分詞、過濾等操作,而keyword類型則是當做一個完整數據存儲起來,省去了多余的操作,提高索引性能。
配合keyword使用的還有一個關鍵詞norm,置為false表示當前字段不參與評分;所謂評分是指根據單詞的TF/IDF或其他一些規則,對查詢出的結果賦予一個分值,供展示搜索結果時進行排序, 而一般的業務場景并不需要這樣的排序操作(都有明確的排序字段),從而進一步優化查詢效率。
初始化一個索引,都要在URL中明確指定一個索引名,一旦指定則無法修改,所以一般建立索引都要指定一個默認的別名(alias):
<p ><span >"aliases":{ "loan_alias":{ }<br> }<br></span></p>別名和索引名是多對多的關系,也就是一個索引可以有多個別名,一個別名也可以映射多個索引;在一對一這種模式下,所有用到索引名的地方都可以用別名進行替換;別名的好處就是可以隨時的變動,非常靈活。
如果一個字段已經初始化完畢(動態映射通過插入數據,預定義通過設置字段類型),那就確定了該字段的類型,插入不兼容的數據則會報錯,比如定義了一個long類型字段,如果寫入一個非數字類型的數據,ES則會返回數據類型錯誤的提示。
這種情況下可能就需要重建索引,上面講到的別名就派上了用場;一般分3步完成:
上述步驟適合于離線遷移,如果要實現不停機實時遷移步驟會稍微復雜些。
基本的操作就是增刪改查,可以參考ES的官方文檔:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
一些比較復雜的操作需要用到ES Script,一般使用類Groovy的painless script,這種腳本支持一些常用的JAVA API(ES安裝使用的是JDK8,所以支持一些JDK8的API),還支持Joda time等。
舉個比較復雜的更新的例子,說明painless script如何使用:
需求描述
appSubmissionTime表示進件時間,lenssonStartDate表示開課時間,expectLoanDate表示放款時間。要求2018年9月10日的進件,如果進件時間 與 開課時間的日期差小于2天,則將放款時間設置為進件時間。
Painless Script如下:
<p ><span >POST loan_idx/_update_by_query<br> { "script":{ "source":"long getDayDiff(def dateStr1, def dateStr2){ <br> LocalDateTime date1= toLocalDate(dateStr1); LocalDateTime date2= toLocalDate(dateStr2); ChronoUnit.DAYS.between(date1, date2);<br> }<br> LocalDateTime toLocalDate(def dateStr)<br> { <br> DateTimeFormatter formatter = DateTimeFormatter.ofPattern(\"yyyy-MM-dd HH:mm:ss\"); LocalDateTime.parse(dateStr, formatter);<br> }<br> if(getDayDiff(ctx._source.appSubmissionTime, ctx._source.lenssonStartDate) < 2)<br> { <br> ctx._source.expectLoanDate=ctx._source.appSubmissionTime<br> }", "lang":"painless"<br> }<br> , "query":<br> { "bool":{ "filter":[<br> { "bool":{ "must":[<br> { "range":{ <br> "appSubmissionTime":<br> {<br> "from":"2018-09-10 00:00:00", "to":"2018-09-10 23:59:59", "include_lower":true, "include_upper":true<br> }<br> }<br> }<br> ]<br> }<br> }<br> ]<br> }<br> }<br>}<br></span></p>解釋:整個文本分兩部分,下半部分query關鍵字表示一個按范圍時間查詢(2018年9月10號),上半部分script表示對匹配到的記錄進行的操作,是一段類Groovy代碼(有Java基礎很容易讀懂),格式化后如下, 其中定義了兩個方法getDayDiff()和toLocalDate(),if語句里包含了具體的操作:
<p ><span >long getDayDiff(def dateStr1, def dateStr2){<br> LocalDateTime date1= toLocalDate(dateStr1);<br> LocalDateTime date2= toLocalDate(dateStr2);<br> ChronoUnit.DAYS.between(date1, date2);<br>}<br>LocalDateTime toLocalDate(def dateStr){<br> DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");<br> LocalDateTime.parse(dateStr, formatter);<br>}if(getDayDiff(ctx._source.appSubmissionTime, ctx._source.lenssonStartDate) < 2){<br> ctx._source.expectLoanDate=ctx._source.appSubmissionTime<br>}<br></span></p>然后提交該POST請求,完成數據修改。
這里重點推薦一個ES的插件ES-SQL:
https://github.com/NLPchina/elasticsearch-sql/wiki/Basic-Queries-And-Conditions
這個插件提供了比較豐富的SQL查詢語法,讓我們可以使用熟悉的SQL語句進行數據查詢。其中,有幾個需要注意的點:
ES-SQL使用Http GET方式發送情況,所以SQL的長度是受限制的(4kb),可以通過以下參數進行修改:http.max_initial_line_length: "8k"
計算總和、平均值這些數字操作,如果字段被設置為非數值類型,直接使用ESQL會報錯,可改用painless腳本。
使用Select as語法查詢出的結果和一般的查詢結果,數據的位置結構是不同的,需要單獨處理。
向ES中插入一條記錄,然后再查詢出來,一般都能查出最新的記錄,ES給人的感覺就是一個實時的搜索引擎,這也是我們所期望的,然而實際情況卻并非總是如此,這跟ES的寫入機制有關,做個簡單介紹:
寫入ES的數據,首先是寫入到Lucene索引段中的,然后才寫入ES的索引中,在寫入ES索引前查到的都是舊數據。
索引段中的數據會以原子寫的方式寫入到ES索引中,所以提交到ES的一條記錄,能夠保證完全寫入成功,而不用擔心只寫入了一部分,而另一部分寫入失敗。
索引段提交后還有最后一個步驟:refresh,這步完成后才能保證新索引的數據能被搜索到。
出于性能考慮,Lucene推遲了耗時的刷新,因此它不會在每次新增一個文檔的時候刷新,默認每秒刷新一次。這種刷新已經非常頻繁了,然而有很多應用卻需要更快的刷新頻率。如果碰到這種狀況,要么使用其他技術,要么審視需求是否合理。
不過,ES給我們提供了方便的實時查詢接口,使用該接口查詢出的數據總是最新的,調用方式描述如下:
GET http://IP:PORT/index\_name/type\_name/id
上述接口使用了HTTP GET方法,基于數據主鍵(id)進行查詢,這種查詢方式會同時查找ES索引和Lucene索引段中的數據,并進行合并,所以最終結果總是最新的。但有個副作用:每次執行完這個操作,ES就會強制執行refresh操作,導致一次IO,如果使用頻繁,對ES性能也會有影響。
數組的處理比較特殊,拿出來單獨講一下。
1)表示方式就是普通的JSON數組格式,如:
[1, 2, 3]、 [“a”, “b”]、 [ { "first" : "John", "last" : "Smith" },{"first" : "Alice", "last" : "White"} ]
2)需要注意ES中并不存在數組類型,最終會被轉換為object,keyword等類型。
3)普通數組對象查詢的問題。
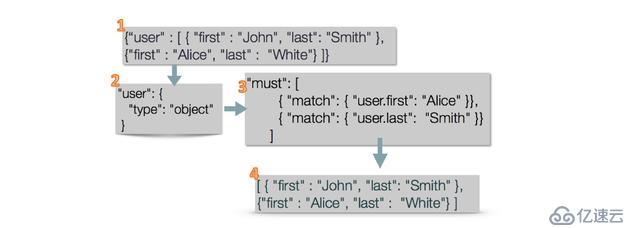
普通數組對象的存儲,會把數據打平后將字段單獨存儲,如:
<p ><span >{ "user":[<br> { "first":"John", "last":"Smith"<br> },<br> { "first":"Alice", "last":"White"<br> }<br> ]<br>}<br></span></p>會轉化為下面的文本
<p ><span >{ "user.first":[ "John", "Alice"<br> ], "user.last":[ "Smith", "White"<br> ]<br>}<br></span></p>將原來文本之間的關聯打破了,圖17展示了這條數據從進入索引到查詢出來的簡略過程:
組裝數據,一個JSONArray結構的文本。
寫入ES后,默認類型置為object。
查詢user.first為Alice并且user.last為Smith的文檔(實際并不存在同時滿足這兩個條件的)。
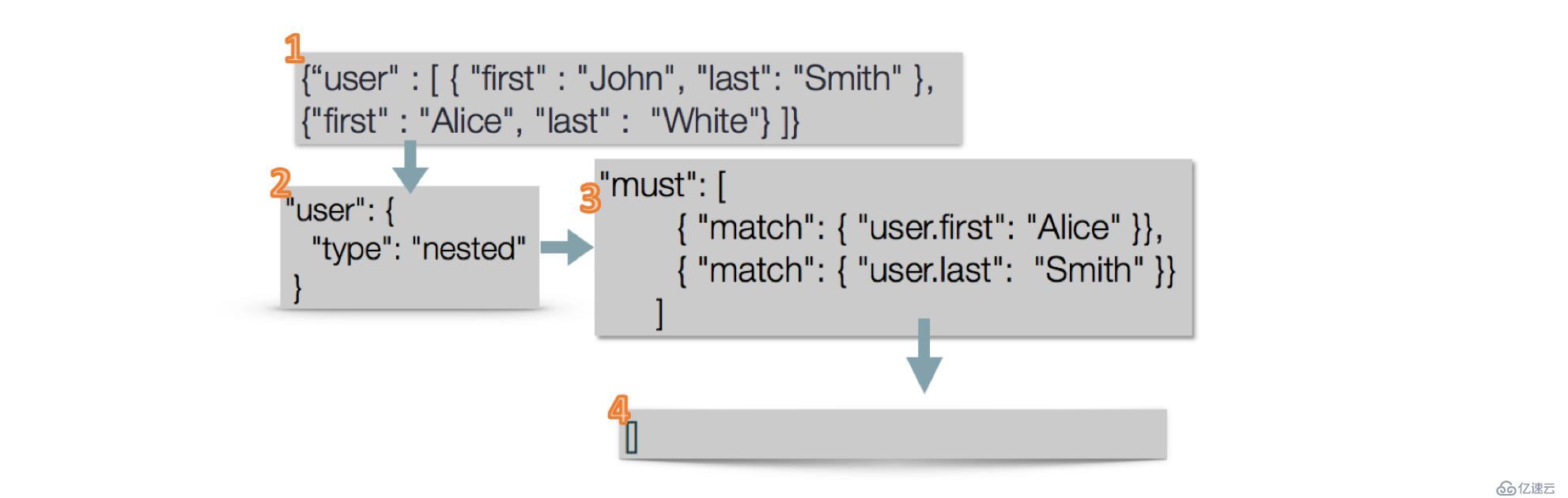
4)嵌套(Nested)數組對象查詢
嵌套數組對象可以解決上面查詢不符的問題,ES的解決方案就是為數組中的每個對象單獨建立一個文檔,獨立于原始文檔。如圖18所示,將數據聲明為nested后,再進行相同的查詢,返回的是空,因為確實不存在user.first為Alice并且user.last為Smith的文檔。
5)一般對數組的修改是全量的,如果需要單獨修改某個字段,需要借助painless script,參考:https://www.elastic.co/guide/en/elasticsearch/reference/5.6/docs-update.html
數據安全是至關重要的環節,主要通過以下三點提供數據的訪問安全控制:
XPACK提供了Security插件,可以提供基于用戶名密碼的訪問控制,可以提供一個月的免費試用期,過后收取一定的費用換取一個license。
是指在ES服務器開啟防火墻,配置只有內網中若干服務器可以直接連接本服務。
一般不允許業務系統直連ES服務進行查詢,需要對ES接口做一層包裝,這個工作就需要代理去完成;并且代理服務器可以做一些安全認證工作,即使不適用XPACK也可以實現安全控制。
ElasticSearch服務器默認需要開通9200、9300 這兩個端口。
下面主要介紹一個和網絡相關的錯誤,如果大家遇到類似的錯誤,可以做個借鑒。
引出異常前,先介紹一個網絡相關的關鍵詞,keepalive :
HTTP1.1中默認啟用"Connection: Keep-Alive",表示這個HTTP連接可以復用,下次的HTTP請求就可以直接使用當前連接,從而提高性能,一般HTTP連接池實現都用到keep-alive;
TCP的keepalive的作用和HTTP中的不同,TPC中主要用來實現連接保活,相關配置主要是net.ipv4.tcp_keepalive_time這個參數,表示如果經過多長時間(默認2小時)一個TCP連接沒有交換數據,就發送一個心跳包,探測下當前鏈接是否有效,正常情況下會收到對方的ack包,表示這個連接可用。
下面介紹具體異常信息,描述如下:
兩臺業務服務器,用restClient(基于HTTPClient,實現了長連接)連接的ES集群(集群有三臺機器),與ES服務器分別部署在不同的網段,有個異常會有規律的出現:
每天9點左右會發生異常Connection reset by peer. 而且是連續有三個Connection reset by peer
<p ><span >Caused by: java.io.IOException: Connection reset by peer <br> at sun.nio.ch.FileDispatcherImpl.read0(Native Method) <br> at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39) <br> at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) <br> at sun.nio.ch.IOUtil.read(IOUtil.java:197)<br></span></p>為了解決這個問題,我們嘗試了多種方案,查官方文檔、比對代碼、抓包。。。經過若干天的努力,最終發現這個異常是和上面提到keepalive關鍵詞相關(多虧運維組的同事幫忙)。
實際線上環境,業務服務器和ES集群之間有一道防火墻,而防火墻策略定義空閑連接超時時間為例如為1小時,與上面提到的linux服務器默認的例如為2小時不一致。由于我們當前系統晚上訪問量較少,導致某些連接超過2小時沒有使用,在其中1小時后防火墻自動就終止了當前連接,到了2小時后服務器嘗試發送心跳保活連接,直接被防火墻攔截,若干次嘗試后服務端發送RST中斷了鏈接,而此時的客戶端并不知情;當第二天早上使用這個失效的鏈接請求時,服務端直接返回RST,客戶端報錯Connection reset by peer,嘗試了集群中的三臺服務器都返回同樣錯誤,所以連續報了3個相同的異常。解決方案也比較簡單,修改服務端keepalive超時配置,小于防火墻的1小時即可。
作者:綜合信貸雷鵬
來源:宜信技術學院
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





