溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關mysql中執行查詢語句的流程分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
比如,在我們從student表中查詢一個id=2的信息
select * from student where id=2;
在解釋這條語句執行流程之前,我們看看mysql的基礎架構。
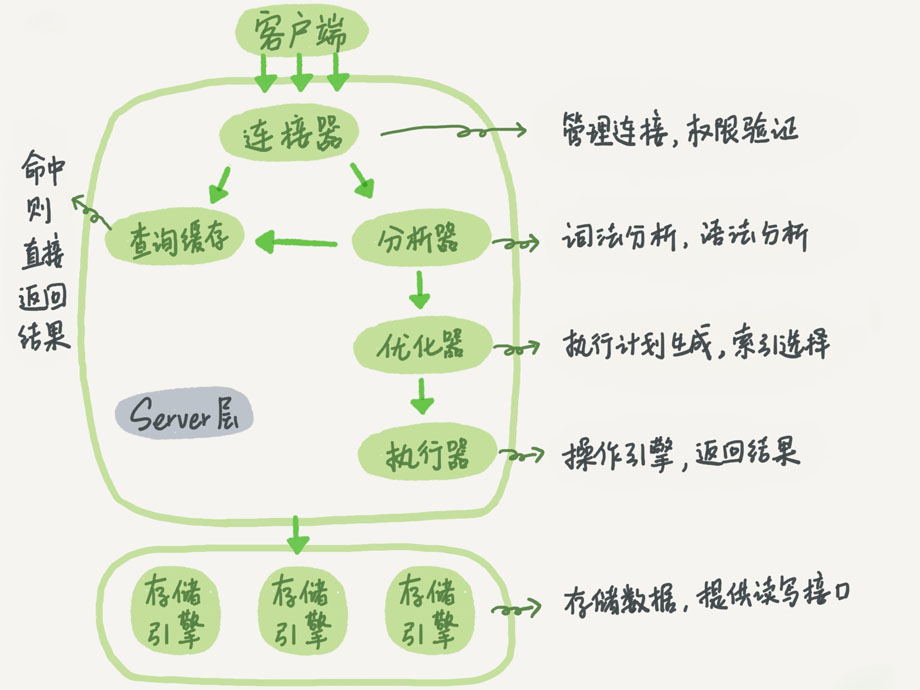
圖來自極客時間的mysql實踐,該圖是描述的是MySQL的邏輯架構。
server層包括連接器、查詢緩存、分析器、優化器、執行器涵蓋 MySQL 的大多數核心服務功能,以及所有的內置函數所有跨存儲引擎的功能都在這一層實現,比如存儲過程、觸發器、視等。
存儲引擎層負責數據的存儲和提取。其架構模式是插件式的,支持InnoDB、MyISAM、Memory 等多個存儲引擎,平常我們比較常用的是innoDB引擎
連接器
我們在使用數據庫之前,需要連接到數據庫,連接語句是
mysql -h $ip -u $username -p $password
而我們的連接器就是處理這個過程的,連接器的主要功能是負責跟客戶端建立連接、獲取權限、維持和管理連接,連接器在使用的過程中如果該用戶的權限改變,是不會馬上生效的,因為用戶權限是在連接的時候讀取的,只能重新連接才可以更新權限
連接器與客戶端通信的協議是tcp協議的,連接以后可以使用show processlist;看到執行的連接數
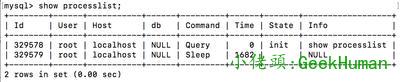
同時在連接時間內超過8小時是sleep的狀態會自動斷開,這個是mysql默認設置,如果一直不斷開,那么這個過程可以叫做一個長連接。
與之對應的有短連接,短連接是指在執行一條或幾條的以后斷開連接。
當不斷使用長連接的時候會占用很大的內存資源,在mysql5.7以后可以使用mysql_reset_connection語句來重新初始化資源。
查詢緩存
經過連接以后,就連接上數據庫了,這個時候可以執行語句了。
執行語句的時候,mysql首先是去查詢緩存,之前有沒有執行過這樣的語句,mysql會將之前執行過的語句和結果以key-value的形式存儲起來(當然有一定的存儲和實效時間)。如果存在緩存,則直接返回緩存的結果。
緩存的工作流程是
服務器接收SQL,以SQL和一些其他條件為key查找緩存表
如果找到了緩存,則直接返回緩存
如果沒有找到緩存,則執行SQL查詢,包括原來的SQL解析,優化等。
執行完SQL查詢結果以后,將SQL查詢結果緩存入緩存表
當然,如果這個表修改了,那么使用這個表中的所有緩存將不再有效,查詢緩存值得相關條目將被清空。所以在一張被反復修改的表中進行語句緩存是不合適的,因為緩存隨時都會實效,這樣查詢緩存的命中率就會降低很多,不是很劃算。
當這個表正在寫入數據,則這個表的緩存(命中緩存,緩存寫入等)將會處于失效狀態,在Innodb中,如果某個事務修改了這張表,則這個表的緩存在事務提交前都會處于失效狀態,在這個事務提交前,這個表的相關查詢都無法被緩存。
一般來說,如果是一張靜態表或者是很少變化的表就可以進行緩存,這樣的命中率就很高。
下面來說說緩存的使用時機,衡量打開緩存是否對系統有性能提升是一個很難的話題
通過緩存命中率判斷, 緩存命中率 = 緩存命中次數 (Qcache_hits) / 查詢次數 (Com_select)
通過緩存寫入率, 寫入率 = 緩存寫入次數 (Qcache_inserts) / 查詢次數 (Qcache_inserts)
通過 命中-寫入率 判斷, 比率 = 命中次數 (Qcache_hits) / 寫入次數 (Qcache_inserts), 高性能MySQL中稱之為比較能反映性能提升的指數,一般來說達到3:1則算是查詢緩存有效,而最好能夠達到10:1
分析器
在查詢緩存實效或者是無緩存的時候,這個時候MySQL的server就會利用分析器來分析語句,分析器也叫解析器。
MySQL分析器由兩部分組成,第一部分是用來詞法分析掃描字符流,根據構詞規則識別單個單詞,MySQL使用Flex來生成詞法掃描程序在sql/lex.h中定義了MySQL關鍵字和函數關鍵字,用兩個數組存儲;第二部分的功能是語法分析在詞法分析的基礎上將單詞序列組成語法短語,最后生成語法樹,提交給優化器語法分析器使用Bison,在sql/sql_yacc.yy中定義了語法規則。然后根據關系代數理論生成語法樹。
上面解釋分析器太官方和復雜了,其實分析器主要是用來進行“詞法分析”然后知道這個數據庫語句是要干嘛,代表啥意思。
這個時候如果分析器分析出這個語句有問題的時候會報錯,比如ERROR 1064 (42000): You have an error in your SQL syntax
優化器
在分析器分析完了以后知道這個語句是干嘛的時候,接下來是專門用一個優化器進行語句優化,優化器的任務是發現執行SQL查詢的最佳方案。大多數查詢優化器,包括MySQL的查詢優化器,總或多或少地在所有可能的查詢評估方案中搜索最佳方案。
優化器主要是選擇一個最佳的執行方案,執行方案是為了減少開銷,提高執行效率。
MySQL的優化器是一個非常復雜的部件,它使用了非常多的優化策略來生成一個最優的執行計劃:
重新定義表的關聯順序(多張表關聯查詢時,并不一定按照SQL中指定的順序進行,但有一些技巧可以指定關聯順序)
優化MIN()和MAX()函數(找某列的最小值,如果該列有索引,只需要查找B+Tree索引最左端,反之則可以找到最大值,具體原理見下文)
提前終止查詢(比如:使用Limit時,查找到滿足數量的結果集后會立即終止查詢)
優化排序(在老版本MySQL會使用兩次傳輸排序,即先讀取行指針和需要排序的字段在內存中對其排序,然后再根據排序結果去讀取數據行,而新版本采用的是單次傳輸排序,也就是一次讀取所有的數據行,然后根據給定的列排序。對于I/O密集型應用,效率會高很多)
隨著MySQL的不斷發展,優化器使用的優化策略也在不斷的進化,這里僅僅介紹幾個非常常用且容易理解的優化策略而已。
執行器
在分析器知道語句要干什么,優化器知道怎么做以后,下面就到了執行的階段,執行是交給執行器的。
執行器在執行的時候首先判斷該用戶對該表有沒有執行權限,如果沒有則會返回denied之類的錯誤提示。
如果有權限,則會打開表繼續執行。打開表的時候,執行器會根據表定義的引擎,去使用該引擎的接口。
最后執行語句得到數據返回給客戶端。
總結
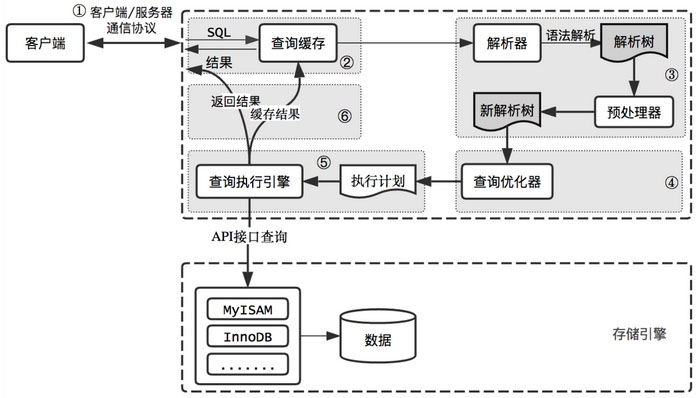
MySQL得到sql語句后,大概流程如下:
0.連接器負責和客戶端進行通信
1.查詢緩存:首先查詢緩存看是否存在k-v緩存
2.解析器:負責解析和轉發sql
3.預處理器:對解析后的sql樹進行驗證
4.優化器:得到一個執行計劃
5.查詢執行引擎:執行器執行語句得到數據結果集
6.將數據放回給調用端。
感謝各位的閱讀!關于“mysql中執行查詢語句的流程分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





