溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python靜態網頁如何爬取高清壁紙,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
前言
在設計爬蟲項目的時候,首先要在腦內明確人工瀏覽頁面獲得圖片時的步驟
一般地,我們去網上批量打開壁紙的時候一般操作如下:
1、打開壁紙網頁
2、單擊壁紙圖(打開指定壁紙的頁面)
3、選擇分辨率(我們要下載高清的圖)
4、保存圖片
實際操作時,我們實現了如下幾步網頁地址的訪問:打開了壁紙的網頁→單擊壁紙圖打開指定頁面→選擇分辨率,點擊后打開最終保存目標圖片網頁→保存圖片
在爬蟲的過程中我們就嘗試通過模擬瀏覽器打開網頁的操作,一步步獲得、訪問網頁、最后獲得目標圖片的下載地址,對圖片進行下載保存到指定路徑中
*這些中間過程中網頁的一些具體篩選條件的構造,需要打開指定頁面的源代碼去觀察和尋找包含有目的鏈接的標簽
具體實現項目與注釋
這里我只想獲得一些指定的圖片,所以我先在網頁上搜索“長門有希”,打開了一個搜索結果頁面,發現在這個頁面上就已經包含了同類型的其他壁紙鏈接,于是我一開始就把最初訪問的目的地址設置為這個搜索結果頁面
目標結果頁面截圖:
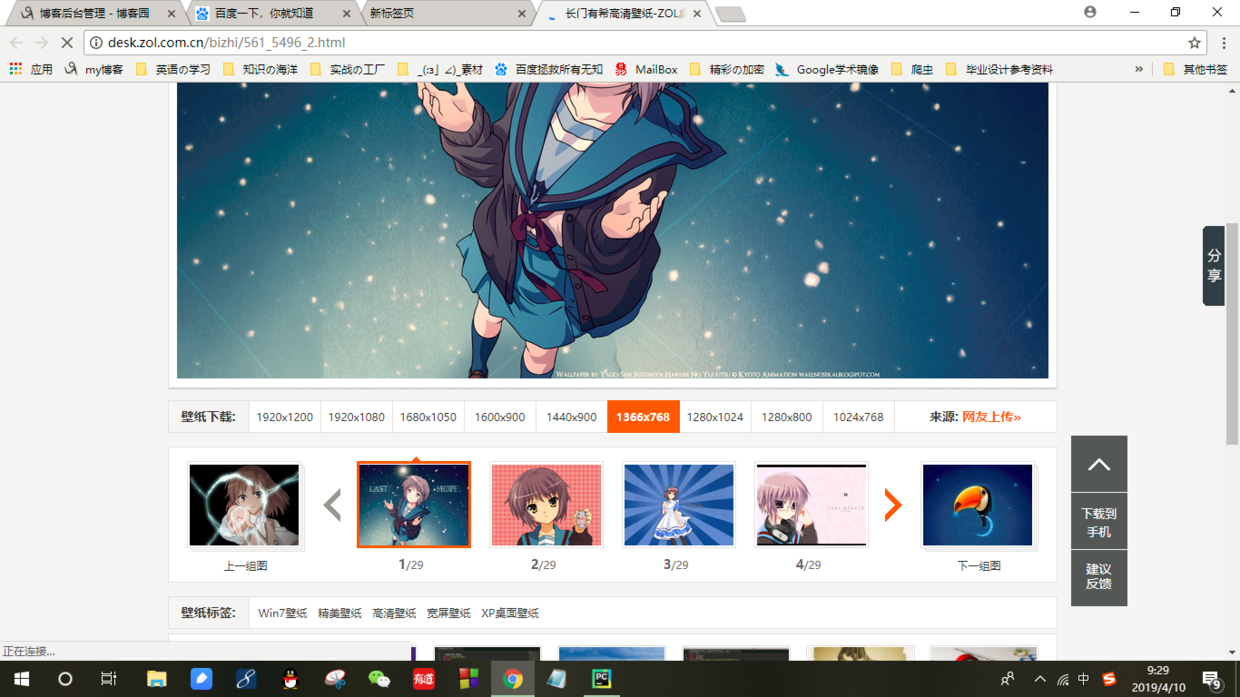
圖中下標為"1/29"."2/29"為其他同類型目標壁紙,通過點擊這些圖片我們可以打開新的目標下載圖片頁面
這里我們查看一下網頁源代碼
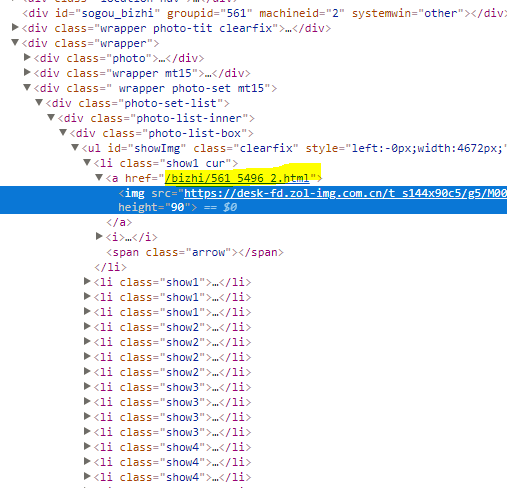
圖中黃色底的地方就是打開這些同類壁紙的目的地址(訪問的時候需要加上前綴"http://desk.zol.com.cn")
現在我們可以嘗試實現構建爬蟲:
打開指定頁面→篩選獲得所有長門有希壁紙的目標下載頁面鏈接
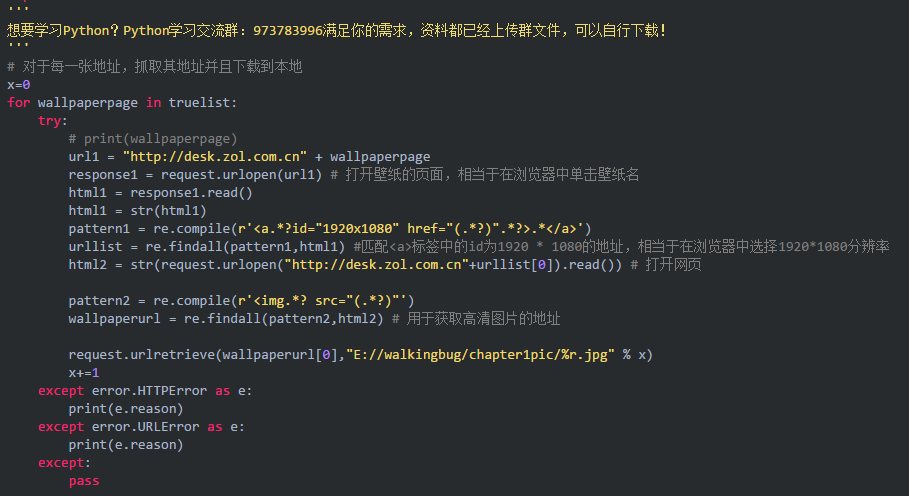
代碼如下:
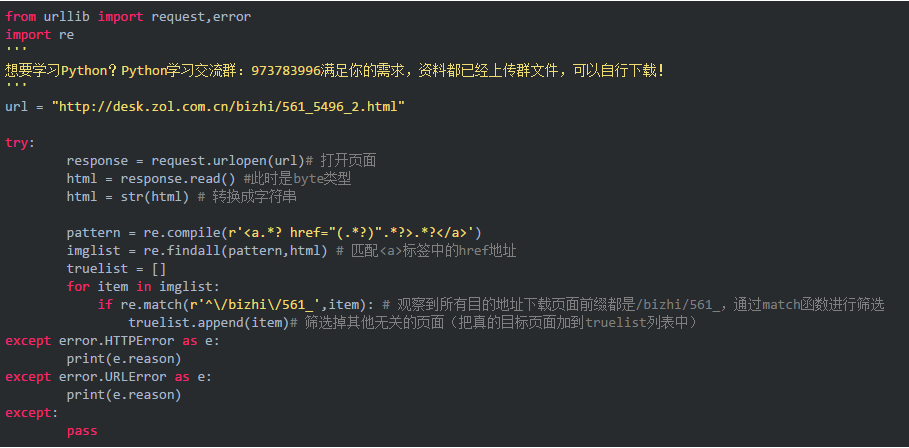
獲得地址以后我們可以通過獲取地址→打開指定頁面→選擇分辨率→獲得目的下載地址→保存到本地指定路徑中
在測試的時候我輸出了一下上一步truelist中保存的內容
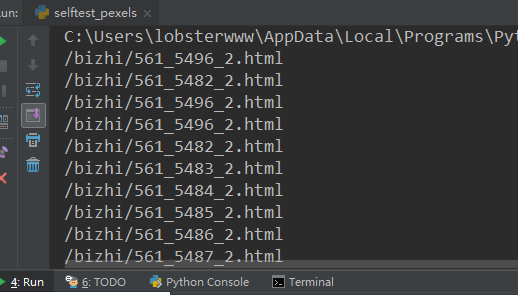
可以看到保存的只是一個后綴,在訪問的時候我們需要加上一個指定的前綴
實現代碼如下(注釋見代碼):
最后可以在自己的目標文件夾中看到爬下來的圖片集~

1、云計算,典型應用OpenStack。2、WEB前端開發,眾多大型網站均為Python開發。3.人工智能應用,基于大數據分析和深度學習而發展出來的人工智能本質上已經無法離開python。4、系統運維工程項目,自動化運維的標配就是python+Django/flask。5、金融理財分析,量化交易,金融分析。6、大數據分析。
看完了這篇文章,相信你對“Python靜態網頁如何爬取高清壁紙”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





