溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹python如何爬取某網站原圖作為壁紙,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
# -*- coding: utf-8 -*-
"""
Created on Wed May 26 17:53:13 2021
@author: 19088
"""
import urllib.request
import os
import pickle
import re
import random
import sys
#獲取http代理
class getHttpAgents:
#初始化函數
def __init__(self):
self.attArray=self.__loadAgentList()
self.myagent=""
#注意 返回對象未進行解碼
def openUrl(self,url,istry=1):
response=""
ip=""
if(0 != len(self.myagent.strip())):
ip=self.myagent
i=1
if not istry:
i=99
while i<100:
try:
#print(self.attArray)
if(0 == len(self.attArray) and 0==len(ip.strip())):
req=urllib.request.Request(url)
#設置訪問頭
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36")
response=urllib.request.urlopen(req)
else:
if(0 != len(self.attArray)):
ip=random.choice(self.attArray)
if(0 != len(self.myagent.strip())):
ip=self.myagent
print("以{}訪問 {}".format(ip,url))
#設置代理
proxy={"http":ip}
#print(proxy)
#定義一個代理字段
proxy_support=urllib.request.ProxyHandler(proxy)
#建立一個opener
opener=urllib.request.build_opener(proxy_support)
opener.addheaders=[("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36")]
#urllib.request.install_opener(opener)
#獲得網頁對象
response=opener.open(url)
except:
if not istry:
print("{} 無法使用".format(ip))
else:
print("第{}次嘗試連接!".format(i))
else:
break;
finally:
i+=1
if 11==i and istry:
raise ValueError
if not response:
return
html=response.read()
#print(html)
return html
#檢查代理池 去除掉不可用代理ip
def checkMyIpPool(self):
agentsResult=[]
agentList=self.attArray
for iter in agentList:
ip=iter
self.setMyIp(ip)
b=self.__getMyIp()
if not b:
#代理不能用
#agentList.pop(-iter)
pass
else:
agentsResult.append(ip)
#print(b)
#記錄爬取過的可以使用的代理ip
self.__writeAgentList(agentsResult)
self.__setAgents(agentsResult)
self.setMyIp("")
#解析讀取網頁中所有的代理地址
def getAgents(self,html):
#print(html)
#匹配 ip地址 正則表達式
pattern = re.compile(r'(<td>)\s*((25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)\.){3}(25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)\s*</td>')
ipList=[]
ip=pattern.finditer(html)
for ipiter in ip:
ipText=ipiter.group()
ipGroup=re.search(r"((25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)\.){3}(25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)", ipText)
ipList.append(ipGroup.group())
#匹配 端口地址 正則表達式
portList=[]
pattern = re.compile(r'(<td>)\s*\d+\s*</td>')
port = pattern.finditer(html)
for portiter in port:
portText=portiter.group()
portGroup=re.search(r"\d+", portText)
portList.append(portGroup.group())
if(len(ipList) is not len(portList)):
print("注意: ip和端口參數不匹配!")
return
ipDict=dict(zip(ipList,portList))
agentList=[]
for key in ipDict:
agentList.append(key+":"+ipDict.get(key))
agentsResult=[]
for iter in agentList:
ip=iter
self.setMyIp(ip)
b=self.__getMyIp()
if not b:
#代理不能用
pass
#agentList.pop(-iter)
else :
agentsResult.append(ip)
self.__setAgents(agentsResult)
print("{} 可以使用".format(ip))
agentsResult.extend(self.attArray)
#記錄爬取過的可以使用的代理ip
if(0==len(agentsResult)):
return
self.__writeAgentList(agentsResult)
self.__setAgents(agentsResult)
self.setMyIp("")
return agentList
def __setAgents(self,ipArray):
self.attArray=ipArray
def setMyIp(self,ip):
self.myagent=ip
#存儲爬取過的ip代理
def __writeAgentList(self, agentList):
if os.path.exists("agent.pkl"):
os.remove("agent.pkl") #每次重新生成 要不多次 dump需要多次 load
with open("agent.pkl.","wb") as f:
pickle.dump(agentList, f)
print("存儲{}條代理".format(len(agentList)))
#加載之前存儲過的ip代理
def __loadAgentList(self):
agentlist=[]
if not os.path.exists("agent.pkl"):
return agentlist
with open("agent.pkl","rb") as f:
agentlist=pickle.load(f)
print("加載{}條代理".format(len(agentlist)))
return agentlist
#獲取當前使用的ip地址 類的內部方法 僅供內部調用
def __getMyIp(self,ip=""):
url="https://www.baidu.com/"
html=""
try:
html=self.openUrl(url,0).decode("utf-8")
except:
return
#匹配ip地址
#pattern = re.compile(r'((25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)\.){3}(25[0-5]|2[0-4]\d|[0-1]\d\d|\d\d|\d)')
#groupIp=pattern.search(html)
#if groupIp:
#return groupIp.group()
else:
return html
#通過不同的網站去爬取代理
def crawlingAgents(self,index):
try:
url ="http://ip.yqie.com/ipproxy.htm"
print(url)
html=self.openUrl(url)
html=html.decode("utf-8")
self.setMyIp("") #不指定ip 隨機挑選一個作為代理
self.getAgents(html)
except Exception as e:
print("{} 爬取失敗".format(url))
#一共搜集多少頁
page=index
indexCur=1
while indexCur<=page:
try:
url=r"https://www.89ip.cn/index_{}.html".format(indexCur)
print(url)
self.setMyIp("")
html=self.openUrl(url) #不指定ip 隨機挑選一個作為代理
html=html.decode("utf-8")
self.getAgents(html)
except Exception as e:
print("{} 爬取失敗".format(url))
finally:
indexCur+=1
indexCur=1
while indexCur<=page:
try:
url=r"http://www.66ip.cn/{}.html".format(indexCur)
print(url)
self.setMyIp("")
html=a.openUrl(url) #不指定ip 隨機挑選一個作為代理
html=html.decode("gb2312")
self.getAgents(html)
except Exception as e:
print("{} 爬取失敗".format(url))
finally:
indexCur+=1
indexCur=1
while indexCur<=page:
try:
url=r"http://www.ip3366.net/?stype=1&page={}".format(indexCur)
print(url)
self.setMyIp("")
html=a.openUrl(url) #不指定ip 隨機挑選一個作為代理
html=html.decode("gb2312")
self.getAgents(html)
except Exception as e:
print("{} 爬取失敗".format(url))
finally:
indexCur+=1
indexCur=1
while indexCur<=page:
try:
url=r"http://www.kxdaili.com/dailiip/1/{}.html".format(indexCur)
print(url)
self.setMyIp("")
html=a.openUrl(url) #不指定ip 隨機挑選一個作為代理
html=html.decode("utf-8")
self.getAgents(html)
except Exception as e:
print("{} 爬取失敗".format(url))
finally:
indexCur+=1
#下載圖片封裝類
class downLoadPictures:
#構造函數
def __init__(self):
self.sortKey={} #定義一個搜索關鍵字的字典
self.urlLoad=getHttpAgents()
self.bzmenuDict={} #分類信息 風景 美女 什么的分類
self.sortscreenDict={} #按照屏幕尺寸分類
self.littleSignDict={} #分類信息下面的小分類
pass
def getPictures(self,url):
#第一步 打開網頁 讀取page信息
pagerHtml=self.urlLoad.openUrl(url)
#第二步 獲取 pageFolder 鏈接和各種分類信息 返回的是一堆folder鏈接的url
folderPictursUrl=self.readPages(pagerHtml).values()
if not folderPictursUrl:
print("獲取圖片集失敗!")
return
for floderiterUrl in folderPictursUrl:
folderUrl=str("https://www.ivsky.com/")+floderiterUrl
folderHtml=self.urlLoad.openUrl(folderUrl)
#第三步 讀取圖片集 獲取單個圖片的鏈接地址 返回的是圖片集里面的一堆文件url
pictursUrlDict=self.readFolders(folderHtml)
for iterPictureKey in pictursUrlDict:
fileName=iterPictureKey+".jpg"
pictureUrl=str("https://www.ivsky.com/")+pictursUrlDict.get(iterPictureKey)
#讀取圖片頁相關信息
pictureHtml=self.urlLoad.openUrl(pictureUrl)
picturDownUrl=self.readPictures(pictureHtml)
pictureDownHtml=self.urlLoad.openUrl(picturDownUrl)
if not pictureDownHtml:
continue
#保存圖片
with open(fileName,"wb+") as f:
f.write(pictureDownHtml)
#提取匹配內容中的所有鏈接地址
def getHrefMap(self,html,isPicture=0,isFolder=0):
hrefDict={}
pattern=re.compile(r'<a\s*.*?\s*</a>',re.I)
if isPicture:
pattern=re.compile(r'<p>\s*?<a\s*.*?</p>',re.I)
hrefIter=pattern.finditer(html)
index=0
for iter in hrefIter:
hrefText=iter.group()
#匹配分類名字
pattern=re.compile(r'"\s*?>\s*?.*?</a>',re.I)
name=""
nameGroup=pattern.search(hrefText)
if nameGroup:
name=nameGroup.group()
if(5==len(nameGroup.group().replace(" ", ""))):
pattern=re.compile(r'title=".*?"',re.I)
nameGroup=pattern.search(hrefText)
if nameGroup:
name=nameGroup.group()[7:-1]
name=name[2:-4].replace(" ", '')
#匹配href
pattern=re.compile(r'href=".*?" rel="external nofollow" ',re.I)
url=""
urlGroup=pattern.search(hrefText)
if urlGroup:
url=urlGroup.group()[6:-1].replace(" ", '')
if isFolder:
index+=1
name+="_"+str(index)
hrefDict[name]=url
return hrefDict
#讀取首頁信息 包含各種分類的鏈接地址 以及圖片集的地址集合
def readPages(self,html):
html=html.decode("utf-8")
#檢索壁紙分類
#匹配 壁紙分類信息
pattern=re.compile(r'<ul\s*class="bzmenu".*?</ul>',re.I)
sortClassGroup=pattern.search(html)
if sortClassGroup:
sortMessage=sortClassGroup.group()
self.bzmenuDict=self.getHrefMap(sortMessage)
#print(self.bzmenuDict)
else:
print("匹配壁紙分類出錯!")
return
#匹配 按照屏幕大小分類
pattern=re.compile(r'<ul\s*class="sall_dd".*?</ul>',re.I)
sortClassGroup=pattern.search(html)
if sortClassGroup:
sortMessage=sortClassGroup.group()
self.sortscreenDict=self.getHrefMap(sortMessage)
#print(self.sortscreenDict)
else:
print("匹配屏幕尺寸分類失敗!")
return
#匹配 獲取小分類
pattern=re.compile(r'<div\s*class="sline".*?</div>',re.I)
sortClassGroup=pattern.search(html)
if sortClassGroup:
sortMessage=sortClassGroup.group()
#print(sortMessage)
self.littleSignDict=self.getHrefMap(sortMessage)
#print(self.littleSignDict)
else:
print("匹配小分類失敗")
return
pictureDict={}
#匹配 圖片集地址
pattern=re.compile(r'<ul\s*class="ali".*?</ul>',re.I)
sortClassGroup=pattern.search(html)
if sortClassGroup:
sortMessage=sortClassGroup.group()
pictureDict=self.getHrefMap(sortMessage,1)
#print(pictureDict)
else:
print("匹配圖片集地址失敗!")
return
#print(html)
return pictureDict
#解析每個圖片集合對應的圖片集內容 解析出單個圖片的鏈接地址
def readFolders(self,html):
if not html:
return
html=html.decode("utf-8")
#獲取圖片集里面每個圖片的具體地址和名稱
#匹配 獲取小分類
pattern=re.compile(r'<ul\s*class="pli".*?</ul>',re.I)
sortClassGroup=pattern.search(html)
pictureUrlDict={}
if sortClassGroup:
sortMessage=sortClassGroup.group()
#print(sortMessage)
pictureUrlDict=self.getHrefMap(sortMessage,1,1)
#print(pictureUrlDict)
else:
print("匹配小分類失敗")
return
return pictureUrlDict
#解析每個圖片集合對應的圖片集內容 解析出單個圖片的鏈接地址
def readPictures(self,html):
if not html:
return
html=html.decode("utf-8")
#獲取圖片集里面每個圖片的具體地址和名稱
#匹配 獲取小分類
pattern=re.compile(r'<div\s*class="pic".*?</div>',re.I)
sortClassGroup=pattern.search(html)
pictureUrl=""
if sortClassGroup:
sortMessage=sortClassGroup.group()
#匹配href
pattern=re.compile(u"src='.*?'",re.I)
url=""
urlGroup=pattern.search(sortMessage)
if urlGroup:
url=urlGroup.group()[5:-1].replace(" ", '')
url=url.replace('img-pre', 'img-picdown')
url=url.replace('pre', 'pic')
url=str("https:")+url
#print(sortMessage)
pictureUrlDict=url
#print(url)
else:
print("匹配小分類失敗")
return
return pictureUrlDict
class UrlUser:
def __init__(self):
self.agent=getHttpAgents()
self.downPicture=downLoadPictures()
#下載圖片調用函數
def downPictures(self):
#url="https://www.ivsky.com/bizhi"
#b.getPictures(url)
#確定保存路徑
dirPath=input("請輸入保存路徑:")
if not os.path.exists(dirPath):
os.mkdir(dirPath)
if not os.path.isdir(dirPath):
print("savePath is wrong!")
sys.exit()
os.chdir(dirPath) #切換工作目錄
#url=r"https://www.ivsky.com/bizhi/nvxing_1920x1080/index_{}.html"
page=input("爬取前多少頁的圖片?\n")
indexRe = re.search(r"\d+", page)
if(not indexRe):
print("輸入頁數有誤!")
indexRe=int(indexRe.group())
indexCur=1
while indexCur<=indexRe:
try:
#注意 爬取什么類型的圖片可以根據不同的網址進行設計 下載類里面已經讀取了所有分類對應的地址 有興趣可以自己完善
url=r"https://www.ivsky.com/bizhi/nvxing_1920x1080/index_{}.html".format(indexCur)
print(url)
self.downPicture.getPictures(url)
except:
print("打開出錯!")
pass
finally:
indexCur+=1
#爬取代理
def downAgents(self):
page=input("爬取前多少頁的代理?\n")
indexRe = re.search(r"\d+", page)
if(not indexRe):
print("輸入頁數有誤!")
return
indexRe=int(indexRe.group())
self.agent.crawlingAgents(indexRe)
# 檢查當前代理池是否可以
def checkPool(self):
self.agent.checkMyIpPool()
if __name__ == "__main__":
print("*"*20)
print("1.爬取代理\n")
print("2.檢查代理\n")
print("3.爬取圖片")
print("*"*20)
mode=input("請輸入數字選擇處理模式:\n")
indexRe = re.search(r"\d+", mode)
if(not indexRe):
print("輸入頁數有誤!")
sys.exit()
indexRe=int(indexRe.group())
#實例化一個對象
uesrObj=UrlUser()
if 1 == indexRe:
uesrObj.downAgents()
elif 2 == indexRe:
uesrObj.checkPool()
elif 3 == indexRe:
uesrObj.downPictures()
else:
print("模式選擇錯誤!")
sys.exit()
print("爬取完畢!")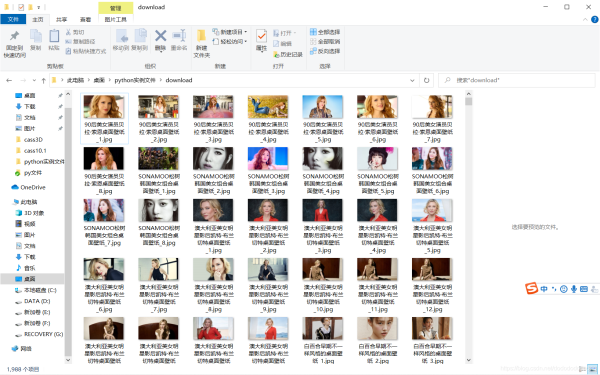
以上是“python如何爬取某網站原圖作為壁紙”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





