溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
接著上一篇博文http://12172969.blog.51cto.com/12162969/1918256,把循環鏈表里的雙循環鏈表的基本操縱按照我個人的理解進行總結一下。
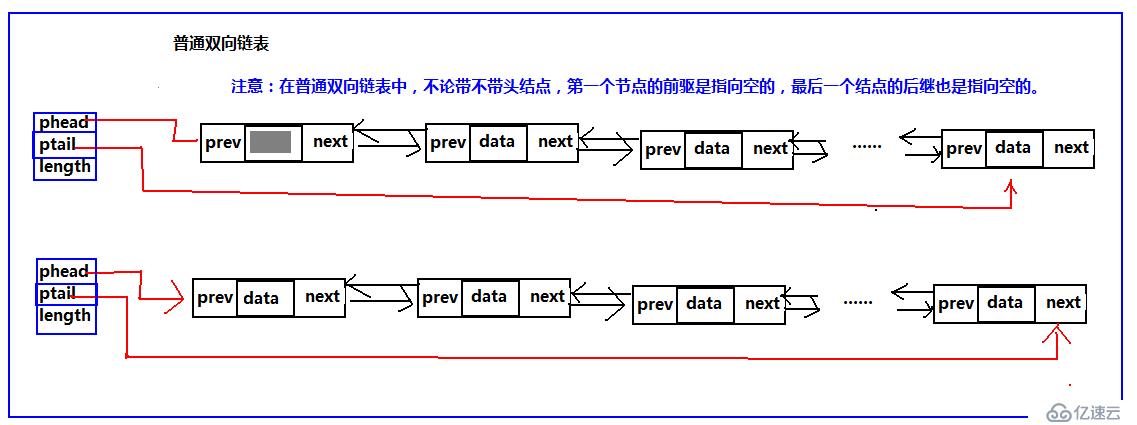
依然沿襲過去的風格,進入雙循環鏈表之前,先提另一種結構,雙向鏈表,先有了雙向鏈表再有了雙循環鏈表。這兩種結構和單鏈表一樣都有帶頭結點和不帶頭結點之分。我們先來看一下這幾種結構的結構圖:
雙鏈表
雙循環鏈表
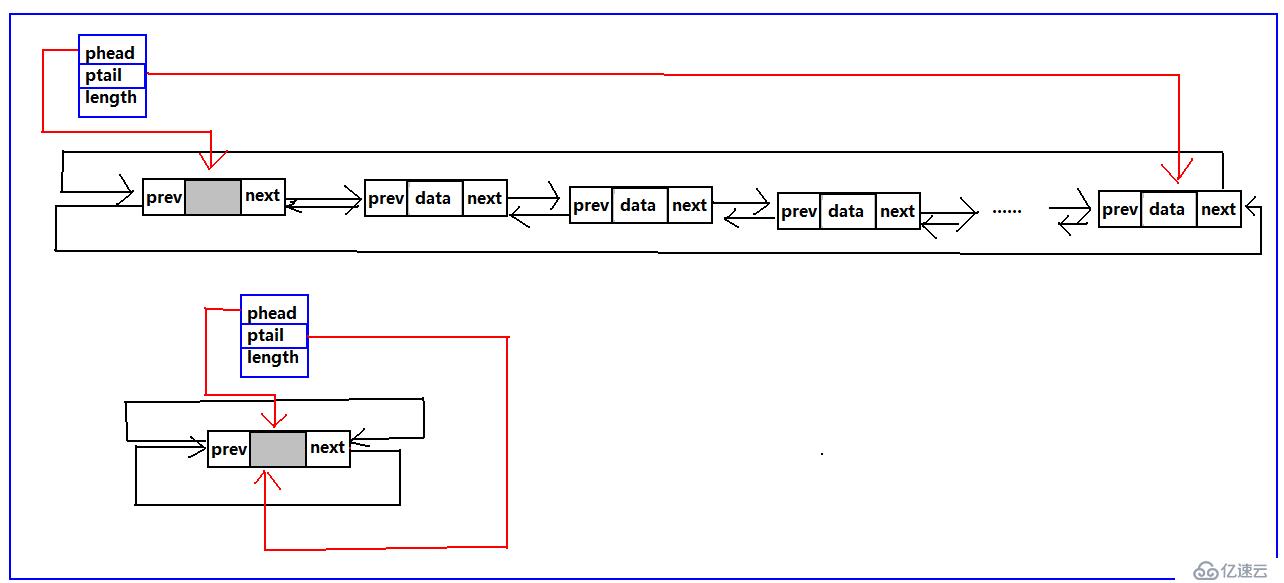
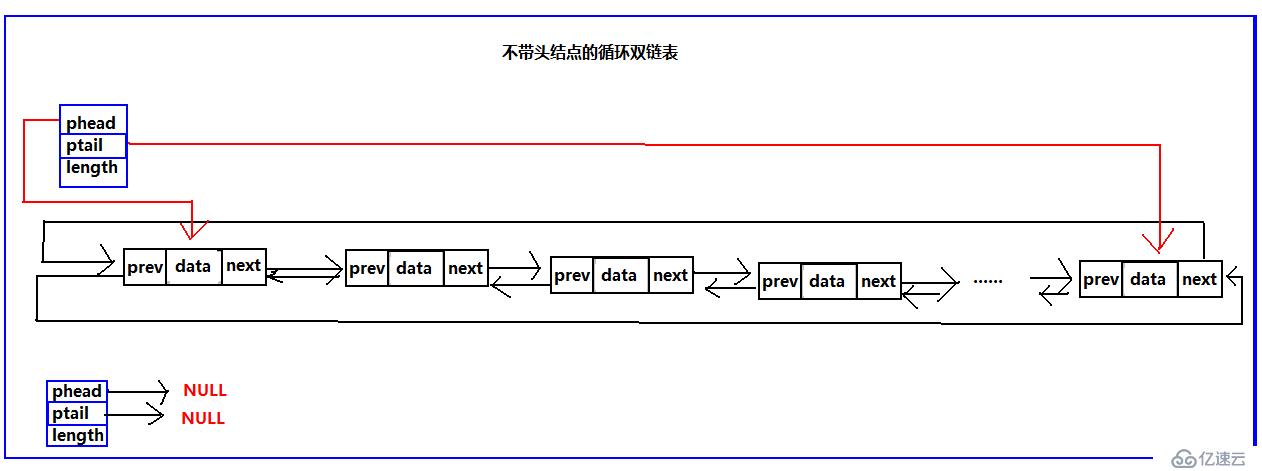
既然單向鏈表有普通的鏈表也就是不循環的鏈表、那么雙向鏈表也一樣,也有普通的雙向鏈表和雙向循環鏈表;也有帶頭結點,不帶頭結點的結構,這里依然是兩種結構都給出算法,但是普通的循環鏈表不寫,這里只寫循環雙鏈表。
首先我們先給出結構定義等部分的代碼:
typedef int Status;
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int ElemType;
//定義雙鏈表的結點
typedef struct node
{
ElemType data;
struct node *next;
struct node *prev;
}Node;
typedef struct node *SeqNode;
//定義管理鏈表的結構
typedef struct list
{
struct node *phead;
struct node *ptail;
size_t length;
}List;
//判斷結點是否為空,空返回FALSE,不空返回TRUE;
Status IsEmpty(SeqNode p)
{
if(NULL ==p)
{
return FALSE;
}
return TRUE;
}
//構造新結點,寫后面的插入函數后會重復使用構造節點的代碼,因此將重復代碼封裝在函數中減少重復代碼量
Node *BuyNode(ElemType x)
{
SeqNode s = (Node*)malloc(sizeof(Node));
if(FALSE == IsEmpty(s))
{
printf("out of mommery\n");
return FALSE;
}
s->data = x;
s->next = NULL;
s->prev = NULL;
return s;
}
//查找函數:按照值插入,都需要找到需要插入的位置,為了優化代碼,因此將這一部分封裝起來。
//查找要插入的結點,因為雙循環鏈表可以通過當前節點找到自己的地址,因此不需用額外的變量保存當前的地址,
//查找成功返回當前結點的地址,查找失敗返回最后一個空間的地址
Node *Find(List head,SeqNode s,ElemType x)
{
while(head.length--)
{
if(s->data < x)
{
s = s->next;
continue;
}
return s;
}
return s;
}
//查找函數:按照值刪除,都需要找到需要插入的位置,為了優化代碼,因此將這一部分封裝起來。
//查找要插入的結點,因為雙循環鏈表可以通過當前節點找到自己的地址,因此不需用額外的變量保存當前的地址,
//查找成功返回當前結點的地址,查找失敗返回NULL
Node *_Find(List head,SeqNode s,ElemType x)
{
while(head.length--)
{
if(s->data == x)
{
return s;
}
s = s->next;
}
return NULL;
}
初始化
初始化的時候,就是要建立一個空表,上圖中已經給出了空表的示意圖,那么 初始化就是建立這樣一個結構。
//初始化帶頭結點的雙向循環鏈表,初始化成功返回TRUE,失敗FALSE.
Status Init_Yes_SeqNode(List *head)
{
SeqNode s = BuyNode(0);
if(FALSE == IsEmpty(s))
{
printf("初始化失敗\n");
return FALSE;
}
head->length = 0;
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
return TRUE;
}
//初始化不帶頭結點的循環雙鏈表,初始化成功返回TRUE,失敗FALSE.
Status Init_No_Head(List *head)
{
head->length = 0;
head->phead = NULL;
head->ptail = NULL;
return FALSE;
}
雙循環鏈表頭插
個人一直覺得只要結構弄清了,寫代碼就好辦了。所以我繼續給出頭插的示意圖:
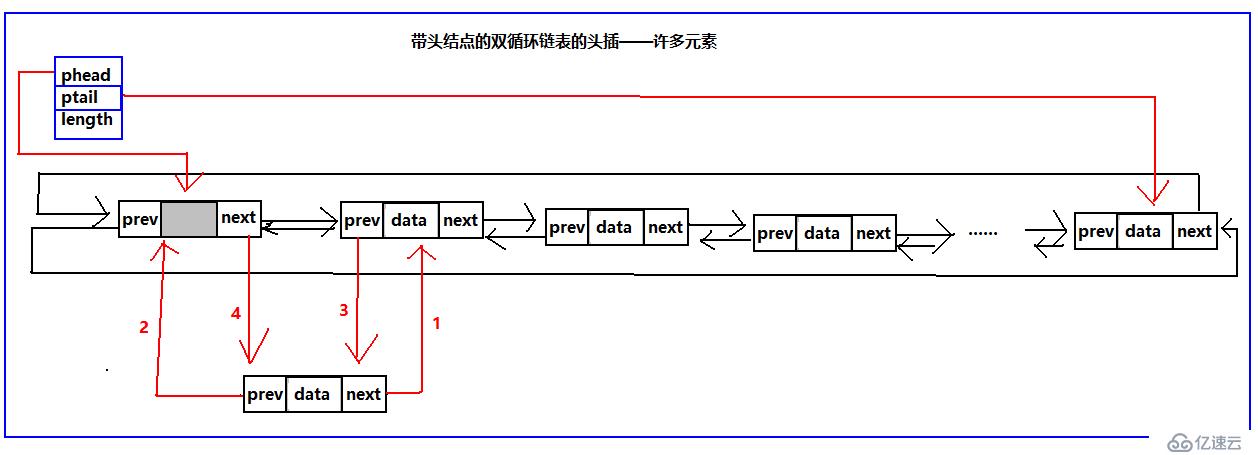
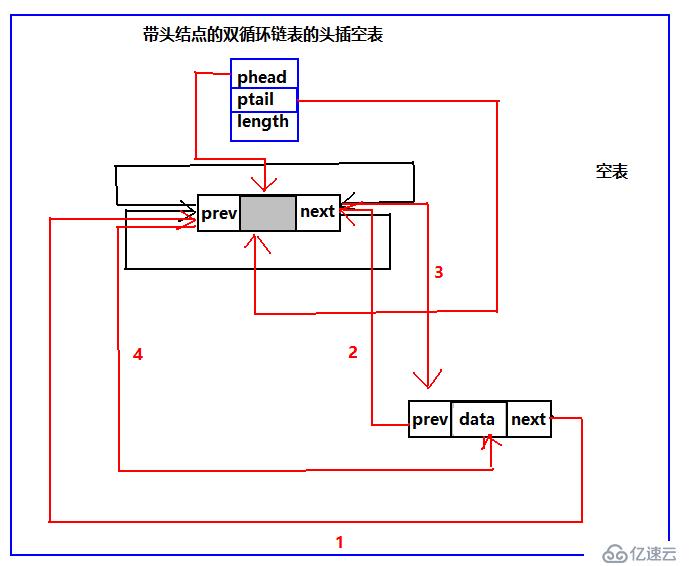
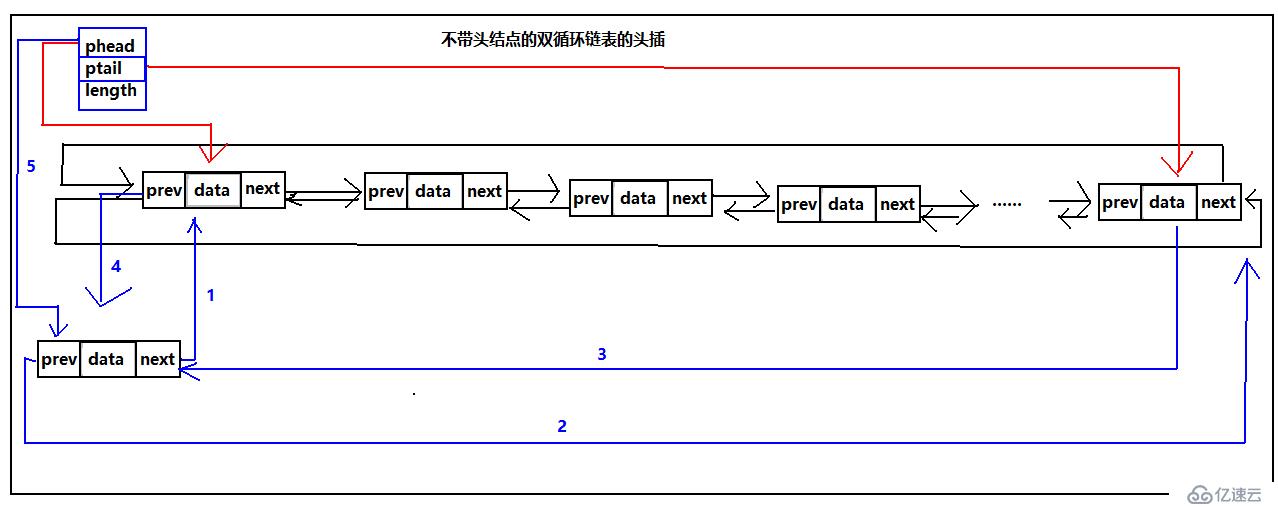
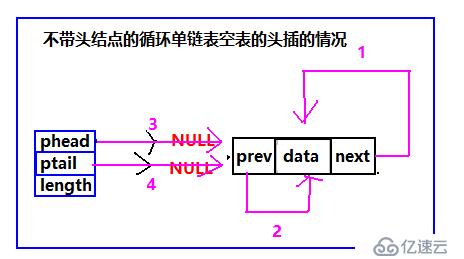
帶不帶頭結點的雙循環鏈表頭插只要按照圖中標號順序,執行就可以頭插成功,兩者都有一個特殊情況,就是空表的時候,需要維護結構的完整性,需要單獨處理。當然我給出的順序只是其中一種,其他的順序同樣可以達到相同的作用。
具體代碼實現如下
//帶頭結點的的雙循環雙鏈表頭插,插入成功返回TRUE,失敗返回FALSE
Status Insert_Yes_Head(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
//需要注意這里SeqNode 定義的變量是一個結點類型的指針,BuyNode(x)函數是我之前定義的函數,用來構造結點的,后邊不在說明
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
s->next = head->phead->next;
s->prev = head->phead;
s->next->prev = s;
s->prev->next = s;
if(0 == head->length) //處理空表的情況
{
head->ptail = s;
}
head->length++;
return TRUE;
}
//不帶頭結點的循環雙鏈表頭插,插入成功返回TRUE,失敗返回FALSE
Status Insert_No_Head(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length)
{
s->next = s;
s->prev = s;
head->phead = s;
head->ptail = s;
}
s->next = head->phead;
s->prev = head->ptail;
s->next->prev = s;
s->prev->next = s;
head->phead = s;
head->length++;
return TRUE;
}
雙循環鏈表尾插
我們繼續看圖:


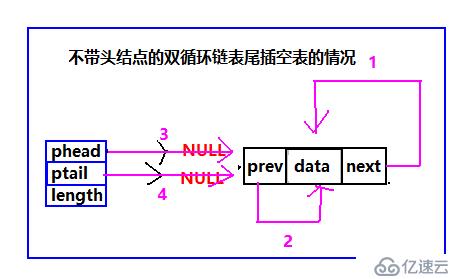
圖看明白了,只要按照步驟來寫帶就可以了。
具體的實現代碼如下:
//帶頭結點的雙循環鏈表的尾插,插入成功返回TRUE,失敗返回FALSE
Status Insert_Yes_Tail(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
s->next = head->phead;
s->prev = head->ptail;
s->prev->next = s;
s->next->prev = s;
head->ptail = s;
head->length++;
return TRUE;
}
//不帶頭結點的雙循環鏈表的尾插,插入成功返回TRUE,失敗返回FALSE
Status Insert_No_Tail(List *head,ElemType x)
{
SeqNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
printf("out of memory\n ");
return FALSE;
}
if(0 == head->length) //處理空鏈表的情況
{
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
}
s->next = head->phead;
s->prev = head->ptail;
s->next->prev = s;
s->prev->next = s;
head->ptail = s;
head->length++;
return TRUE;
}
雙循環鏈表的按值插(這里是按照從小到大的順序)
雙循環鏈表按值插入(這里是從小到大的順序),無論是帶頭結點還是不帶頭結點,當是空表的時候,直接插入鏈表,不需用查找插入位置。
其他情況調用Find函數查找要插入的位置,Find函數的返回值是要插入的地址的后一個元素的地址。由于雙循環鏈表可以同過當前元素找到前一個結點所以Find返回來的地址就可以完成插入操作。當是空表的時候,與頭插或者尾插的空表示意圖一樣,讀者返回到前邊看,這里不給出示意圖,這里只給出有元素的按值插入示意圖:

不帶頭結點的按值插入,有一點需要注意,當只有一個結點的時候再次插入第二個結點的時候需要修改phead和ptail的指向,由于只有一個結點,不管是第二個要插入的值比第一個大還是小,由于是循環鏈表,Find函數返回的都是第一個結點,這樣就需要在插如函數中,進行單獨處理。
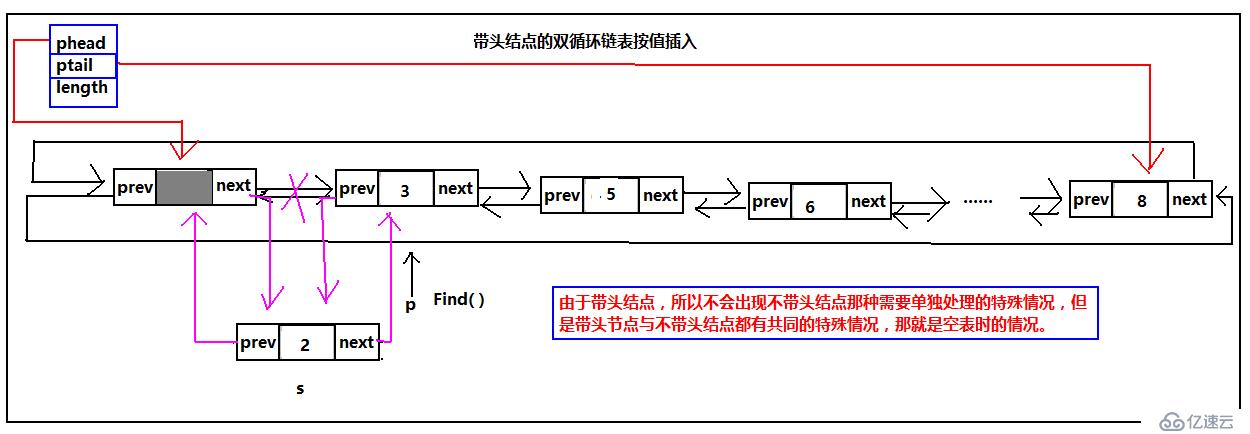
由于帶頭結點,所以不會出現不帶頭結點那種需要單獨處理的特殊情況,但是帶頭節點與不帶頭結點都有共同的特殊情況,那就是空表時的情況。
具體代碼實現:
//帶頭結點的按值插入,插入成功返回TRUE,失敗返回FALSE。
Status Insert_Yse_Value(List *head,ElemType value)
{
SeqNode s = BuyNode(value);
SeqNode p = NULL;
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length) //處理空表的情況
{
s->next = head->phead;
s->prev = head->phead;
head->phead->next = s;
head->ptail = s;
head->phead->prev = s;
head->length++;
return TRUE;
}
p = Find(*head,head->phead->next,value); //Find函數,之前定義的,返回要插入的位置的地址。
//這里我提一下這個判斷條件,給Find函數傳過去的地址,是首元結點的地址,所以當Find()函數返回的地址為head->phead時,說明該元素需要插入到表尾,所以就需要修改ptial的指向。
if(head->phead == p)
{
head->ptail = s;
}
s->next = p;
s->prev = p->prev;
s->prev->next = s;
s->next->prev = s;
head->length++;
return TRUE;
}
//不帶頭結點的按值插入,插入成功返回TRUE,失敗返回FALSE。
Status Insert_No_Value(List *head,ElemType value)
{
SeqNode s = BuyNode(value);
SeqNode p = NULL;
if(FALSE == IsEmpty(s))
{
printf("out of memory\n");
return FALSE;
}
if(0 == head->length) //處理空表的情況
{
head->phead = s;
head->ptail = s;
s->next = s;
s->prev = s;
head->length++;
return TRUE;
}
p = Find(*head,head->phead,value); //Find函數,之前定義的,返回要插入的位置的地址。
s->next = p;
s->prev = p->prev;
p->prev = s;
s->prev->next = s;
//重點說一下這一部分,由于沒有頭結點,所以當Find()函數head->phead時,有可能是往頭插,也有可能是往尾插,所以就需要進行判斷,當Find()函數的返回值等于頭指針時,如果將要插入的值大于首元結點的值,那么就是說,要插入的值是往最后插,即就是需要把ptail修改指向新結點。否則修改phead。
if(head->phead == p)
{
if( s->data > head->ptail->data)
{
head->ptail = s;
}
else
{
head->phead = s;
}
}
head->length++;
return TRUE;
}
循環雙鏈表的頭刪
不論是帶頭結點的鏈表還是不帶頭結點當鏈表為空時直接返回FALSE;對于帶頭結點和不帶頭結點的雙循環鏈表,都需要注意一個結點的情況,對于帶頭結點的雙循環鏈表,由于phead始終是指向頭結點的,所以,不需用修改頭指針的指向,以及最后一個節點的next域除了當刪除到最后一個結點時,其他的都不用修改phead、ptail、ptail->next、phead->prev。然而對于不帶頭結點就需要每次維護循環鏈表的完整性,修改這些值。我們繼續看圖:
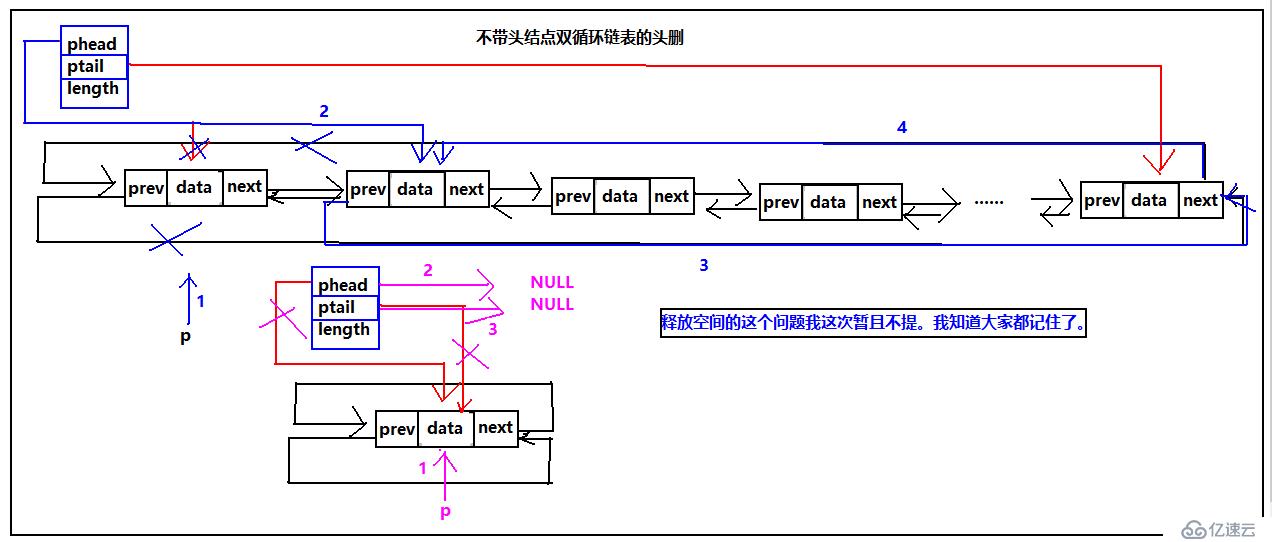

具體代碼實現:
//帶頭結點的循環雙鏈表的頭刪,刪除失敗返回FALSE,刪除成功返回TRUE.
Status Delite_Yes_Head(List *head)
{
SeqNode p = head->phead->next;
if(head->phead == p)
{
printf("鏈表中已空,無元素可刪\n");
return FALSE;
}
head->phead->next = p->next;
p->next->prev = head->phead;
free(p);
p = NULL;
if(1 == head->length) //處理刪除時只有一個結點時的情況
{
head->ptail = head->phead;
}
head->length--;
return TRUE;
}
//不帶頭結點的頭刪,刪除失敗返回FALSE,刪除成功返回TRUE.
Status Delite_No_Head(List *head)
{
SeqNode p = head->phead;
if(NULL == p)
{
printf("鏈表已空,已經無元素可以刪除\n");
return FALSE;
}
if(1 == head->length) //處理刪除時只有一個結點時的情況
{
head->phead = NULL;
head->ptail = NULL;
}
else //處理一般情況
{
head->phead = p->next;
p->next->prev = head->phead;
head->ptail->next = head->phead; //維護循環鏈表的完整性
head->phead->prev = head->ptail;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
循環雙鏈表的尾刪
由于尾刪每次都需要修改ptail的指向,并且修改頭結點的prev的指向,所以對于帶頭結點的雙循環鏈表,所有情況都是一樣的不需用單獨處理那種情況,然而對于不帶頭結點的雙循環鏈表,由于刪除最后一個結點后phead和ptail都會指向NULL,所以要對不帶頭結點的雙循環鏈表的一個結點的情況單獨處理。ok,能用圖解決的問題覺絕不廢話,當然這是玩笑 ,好了我們來看圖:
,好了我們來看圖:
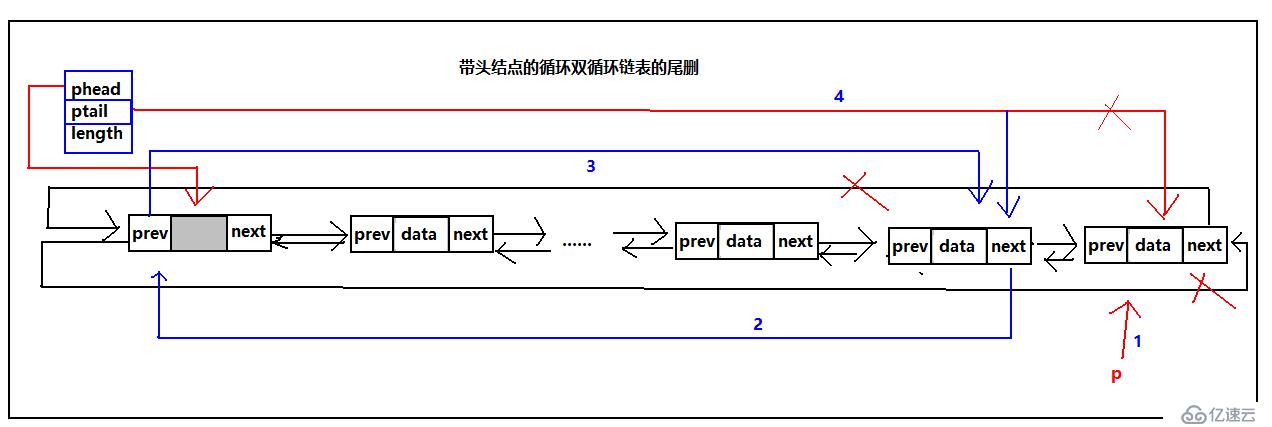
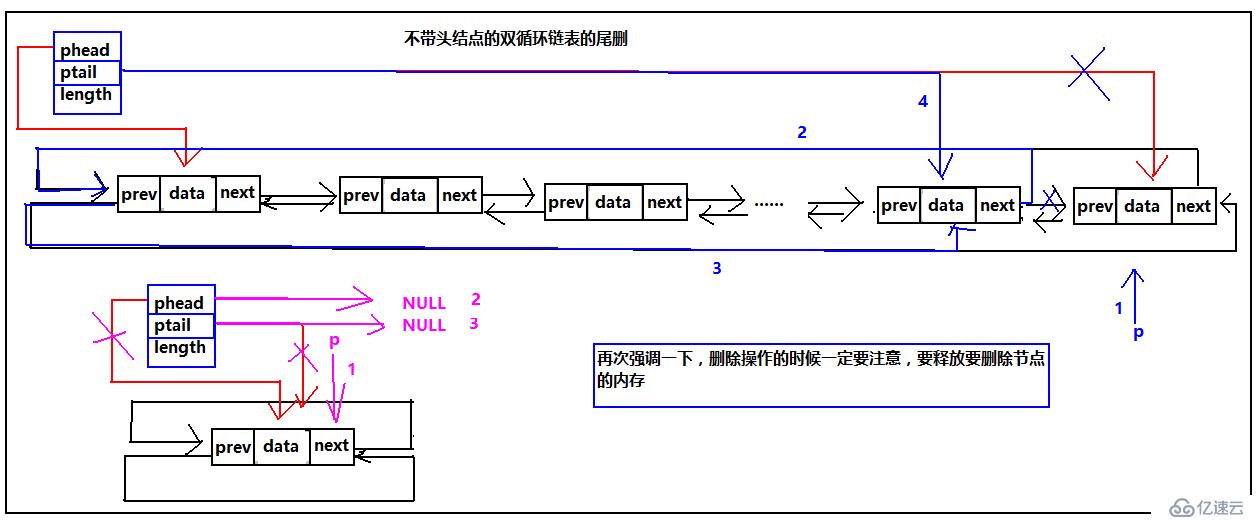
具體代碼實現:
//帶頭結點的尾刪,刪除成功返回TRUE,失敗返回FALSE;
Status Delite_Yes_Tail(List *head)
{
SeqNode p = head->ptail;
if(head->phead == p)
{
printf("鏈表已空、已經無元素可以刪除\n");
return FALSE;
}
p->prev->next = head->phead;
head->phead->prev = p->prev;
head->ptail = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
//不帶頭結點的循環雙鏈表的尾刪
Status Delite_No_Tail(List *head)
{
SeqNode p = head->ptail;
if(NULL == p)
{
printf("鏈表已空、已經無元素可以刪除\n");
return FALSE;
}
if(1 == head->length) //處理只有一個結點的情況
{
head->phead = NULL;
head->ptail = NULL;
}
else
{
p->prev->next = head->phead;
head->phead->prev = p->prev;
head->ptail = p->prev;
}
free(p); //釋放結點空間
p = NULL;
head->length--;
return TRUE;
}
循環雙鏈表的尾刪
為了便于操作,這里就要用到之前寫的另一個Find函數,注意這兩個Find是不一樣的這里Find函數名是_Find函數名前有個下劃線,這只是從名字上的差別,它的功能也不同_Find函數在鏈表中搜索一個特定值,如果搜索到返回當前地址,沒有搜索到返回NULL。
然后對于帶頭結點的雙循環單鏈表,就有這么幾種情況,1、如果表為空,直接返回不用查找了。2、如果_Find返回NULL,說明表中沒有此元素,所以也刪除失敗,3、再就是找到元素,返回它的地址,將其刪除掉釋放掉空間,這里需要注意,由于帶頭結點phead始終指向頭結點,絕不需要修改phead的指向,但是當刪除ptail指向的結點時就需要修改指向。這個要單獨處理。
對于不帶頭結點的雙循環鏈表。1、同樣如果鏈表為空,不用查找直接返回,刪除失敗;2、如果_Find返回NULL,說明表中沒有此元素,所以也刪除失敗;3、再就是找到元素,對于不帶頭結點的鏈表,又分為四種情況:a、如果phead == ptail 并且 _Find 返回的地址等于他們說明鏈表只有一個結點,并且要把他刪除了;b、如果_Find 返回的地址 == ptail 就需要修改 ptail的指向以及附帶的指向;c、如果_Find 返回的地址 == phead 就需要修改phead的指向以及附帶的指向。d、再就是一般情況,注意這幾個條件判斷是有順序的,如果沒有順序就需要b和c再添加條件。接下來我們繼續不看圖了,直接上代碼,這篇都畫了那么多圖了,并且這里會出現的情況,也就是之前那么多刪除操作的綜合,ok,所以沒有圖咯,不上圖了呢,代碼呢我就會給出盡可能多的注釋。
//帶頭結點的按照值,刪除,這里先不考慮重復值,刪除成功返回TRUE,失敗返回FALSE;
Status Delite_Yes_Value(List *head,ElemType value)
{
SeqNode p = NULL;
if(0 == head->length) //表為空,不用查找,刪除失敗,直接返回FALSE
{
printf("鏈表已空,%d刪除失敗\n",value);
return FALSE;
}
p = _Find(*head,head->phead->next,value);
if(NULL == p) //查找完成,表中不存在特定值的情況,刪除失敗,返回FALSE
{
printf("%d刪除失敗,鏈表中沒有%d\n",value,value);
return FALSE;
}
if(head->ptail == p ) //刪除尾結點的情況,就需要修改ptail指向
{
head->ptail = head->ptail->prev;
}
p->prev->next = p->next;
p->next->prev = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
//不帶頭結點的按照值刪除,這里不考慮重復值,只刪除第一個遇到的,刪除成功返回TRUE,失敗返回FALSE;
Status Delite_No_Value(List *head,ElemType value)
{
SeqNode p = head->phead;
if(FALSE == IsEmpty(p)) //表為空,不用查找,刪除失敗,直接返回
{
printf("鏈表已空,%d刪除失敗\n",value);
return FALSE;
}
p = _Find(*head,head->phead,value);
if(NULL == p) //查找完成,表中不存在特定值的情況,刪除失敗,返回FALSE
{
printf("%d刪除失敗,鏈表中沒有%d元素\n",value,value);
return FALSE;
}
//表中元素只有一個并且要刪除的元素就是這一個,就需要修改phead 和 ptail的指向
if(head->phead == head->ptail && p == head->phead)
{
head->phead = NULL;
head->ptail = NULL;
}
//刪除頭結點的情況,就需要修改phead指向,以及附帶的其他指向,使其保持循環結構的完整性
else if(head->phead == p)
{
head->phead = head->phead->next;
head->ptail = head->phead;
}
//刪除尾結點的情況,就需要修改ptail指向,以及附帶的其他指向,使其保持循環結構的完整性
else if(head->ptail == p)
{
head->ptail = head->ptail->prev;
head->phead->prev = head->phead;
}
//一般情況
p->prev->next = p->next;
p->next->prev = p->prev;
free(p);
p = NULL;
head->length--;
return TRUE;
}
循環雙鏈表的打印輸出
//打印輸出不帶頭結點的循環雙鏈表中所有元素。
void Show_No(List head)
{
SeqNode p = head.phead;
if(NULL == p)
{
printf("鏈表為空\n");
return ;
}
if(1 == head.length)
{
printf("%d ",p->data);
printf("\n");
return ;
}
while(head.phead != p->next)
{
printf("%d ",p->data);
p = p->next;
}
printf("%d ",p->data);
printf("\n");
}
//打印輸出帶頭結點的循環雙鏈表中所有元素。
void Show_Yes(List head)
{
SeqNode p = head.phead->next;
while(head.phead != p)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
寫到這里循環鏈表的基本操作就寫完了,當然有幾個操作沒有寫,比如排序,這里先不寫,后邊會有一個專題是寫排序的。還有獲取鏈表長度等大家都很容易實現的就沒有寫,主要把帶頭結點不帶頭結點的插入刪除對比的實現。后續會繼續完善。好了以上就是雙循環鏈表的基本操作,雙循環鏈表寫完了,線性表也就告一段落了。ok,從線性表到鏈表,我把帶頭節點不帶頭結點的基本操作都盡可能多的實現了,我們會發現帶頭結點的操作會方便了好多。接下來,數據結構繼續向前推進
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





