溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
進入循環鏈表之前我先解決一下上篇博文最后提到到的一種更方便的管理鏈表的結構:
typedef struct node //節點類型
{
type value;
struct node *next;
}Node;
typedef struct list
{
Node *phead;
Node *ptail;
int length;
}List;
首先來說這種結構只是為了方便管理,對于鏈表之前提的帶頭節點與不帶頭結點所提的區別依然是有效的,ok我們繼續上圖,先認識一下這種結構:
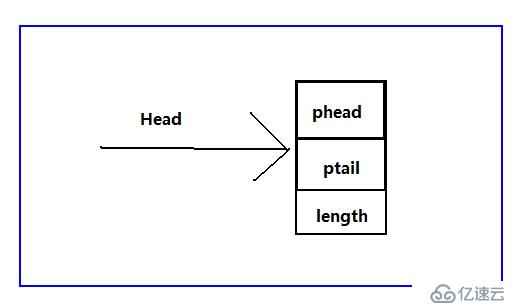
分別通過phead、ptail指向鏈表的頭和尾,length記錄鏈表的長度,這樣就可以方便的記錄鏈表的信息,我們之前說過帶頭結點的鏈表方便操作,那么兩者加起來就更方便。接下來進入今天的主題,循環鏈表,為什么會出現循環鏈表,我個人認為,就是為了彌補單鏈表的不足,在單鏈表中,當我們已經遍歷過某個元素,當我們希望再次查找時,就需要讓臨時指針重新指向頭首元結點,重新遍歷。這樣就很麻煩,有了單循環鏈表,由于尾結點是指向頭,就可以直接找到頭,不需用額外語句,我想這就是單循環鏈表出來的緣故。找到頭的問題解決了,之前單鏈表按位置插入刪除的時候,當我們在需要插入、刪除某個元素的時候不僅要找到特定元素,還需要記住這個元素之前的元素,才能找到特定元素的地址。ok,為了解決這個問題,我們聰明的計算機前輩,又發明了雙循環鏈表,解決了這個問題。接下來,依然為了便于理解,給出我在學習過程中的一些理解圖:帶頭結點、不帶頭結點的鏈表,這里都給出。不過,這里不在采用之前給出的管理鏈表的方式管理鏈表,通過我剛給出的方式處理,請看下圖:
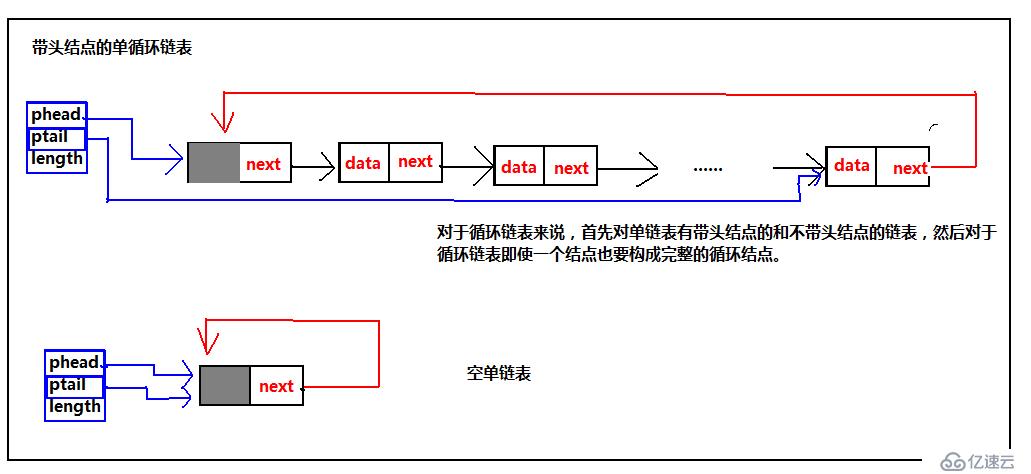
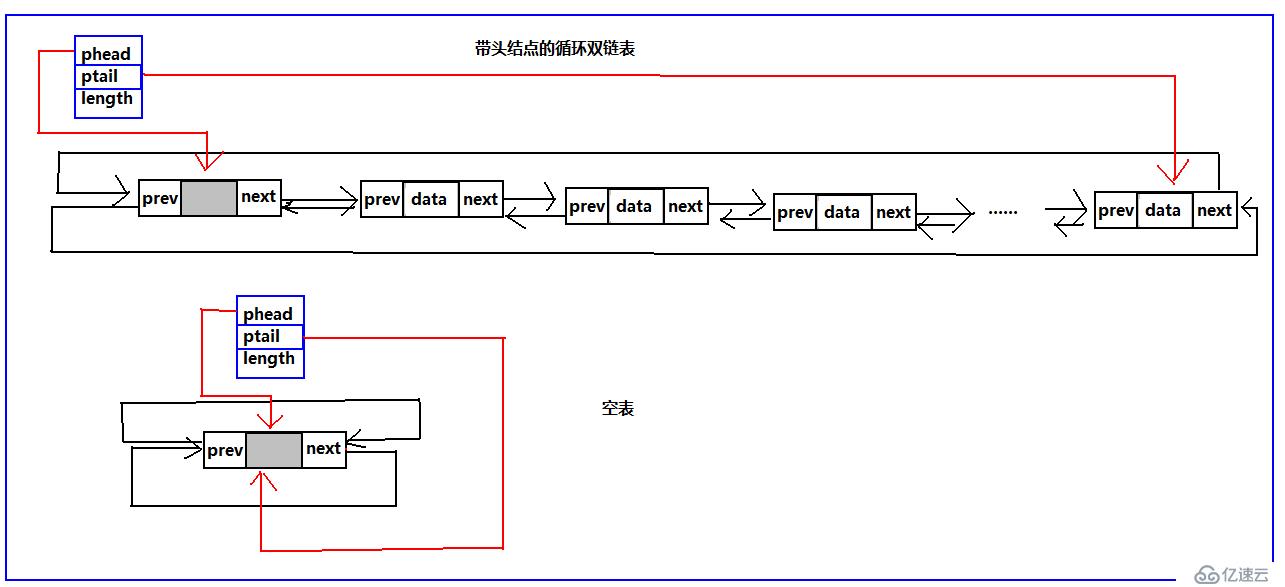
ok看完了結構圖,我們來看循環鏈表主要的基本操作,同樣的這里把帶頭結點的操作,不帶頭結點的的結構的操作都按照我個人的理解都給出。這里先給出單循環鏈表的代碼以及示意圖
首先我們先給出結構定義等部分的代碼:
typedef int Status;
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int ElemType;
//定義單鏈表的結點
typedef struct node
{
ElemType data;
struct node *next;
}Node;
typedef struct node *LinkNode;
//定義管理鏈表的結構
typedef struct list
{
LinkNode Phead;
LinkNode Ptail;
int length ;
}List;
//構造新結點,寫后面的插入函數后會重復使用構造節點的代碼,因此將重復代碼封裝在函數中減少重復代碼量
Node * BuyNode(ElemType x)
{
LinkNode s = (Node *)malloc(sizeof(Node));
if(NULL == s)
{
return NULL;
}
s->data = x;
s->next = NULL;
return s;
}
//同樣構造完結點后多次使用到判斷是否為空,因此也將代碼封裝成函數精簡代碼。
//判斷是空返回FALSE;不是空返回TRUE;
Status IsEmpty(LinkNode s )
{
if(NULL == s)
{
printf("Out of memory\n");
return FALSE;
}
return TRUE;
}
初始化
//初始化不帶頭結點的循環單鏈表,初始化成功返回TRUE;失敗返回FALSE;
Status Init_No_Head(List * head)
{
head->length = 0;
head->Phead = NULL;
head->Ptail = NULL;
return TRUE;
}
//初始化帶頭結點是循環單鏈表,初始化成功返回TRUE;失敗返回FALSE;
Status Init_Yes_Head(List *head)
{
LinkNode s = BuyNode(0);
if(NULL == s)
{
printf("內存不足,初始化失敗\n");
return ERROR;
}
head->length = 0;
head->Phead = head->Ptail = s;
s->next = head->Phead;
return TRUE;
}
單循環鏈表的頭插
同樣也為了便于理解,我這里給出頭插操作的示意圖:
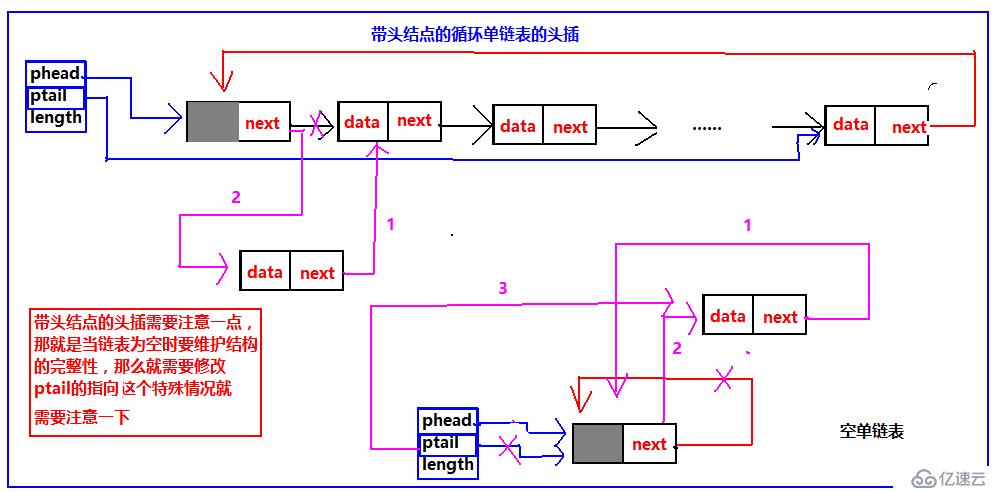
帶頭結點的頭插,由于帶頭結點,所以頭指針phead始終指向頭結點,但是有一種特殊情況,為了維護其結構的完整性,那么對于空表的頭插就是一種特殊情況,就要單獨處理,需要把尾指針的指向修改。
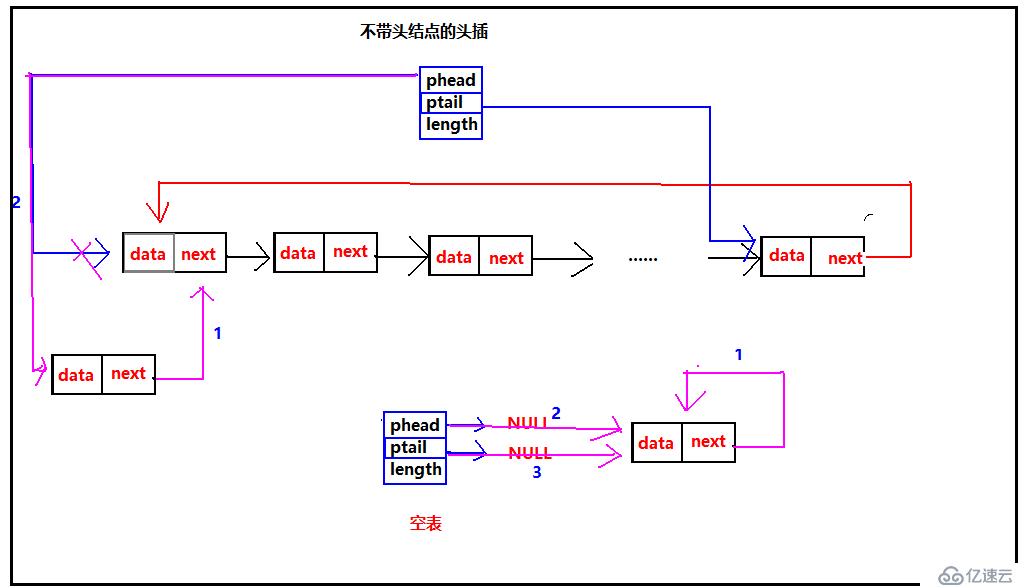
由于不帶頭結點,所以每次頭插就需要修改頭指針的指向。所以不帶頭結點的頭插就會出現兩種情況,1、表中已經有多個元素,頭插時需要把phead始終指向第一個結點,這里沒有頭結點,因此就需要每次需改phead,2、空表的時候,就需要修改頭指針phead和尾指針ptail的指向,并且要把第一個結點next指向自己,構成循環。
具體實現代碼如下:
//不帶頭結點的頭插,插入成功返回TRUE,失敗返回FASLE
Status Insert_No_Head(List *head,ElemType x)
{
LinkNode s = BuyNode(x); //構造新結點
if(FALSE == IsEmpty(s))
{
return FALSE;
}
if(0 == head->length) //處理空鏈表的情況
{
head->Ptail = head->Phead = s;
}
s->next = head->Phead;
head->Phead = s;
head->Ptail->next = s;
head->length++;
return TRUE;
}
//帶頭結點的循環單鏈表的頭插,插入成功返回TRUE,失敗返回FASLE
//帶頭結點的頭插需要注意一點,那就是當鏈表為空時要維護結構的完整性,那么就需要修改ptail的指向
Status Isert_Yse_Head(List *head ,ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
s->next = head->Phead->next;
head->Phead->next= s;
if(0 == head->length) //處理空鏈表的情況
{
head->Ptail = s;
s->next = head->Phead;
}
head->length++;
return TRUE;
}
單循環鏈表的尾插
同樣我們來看尾插的示意圖:
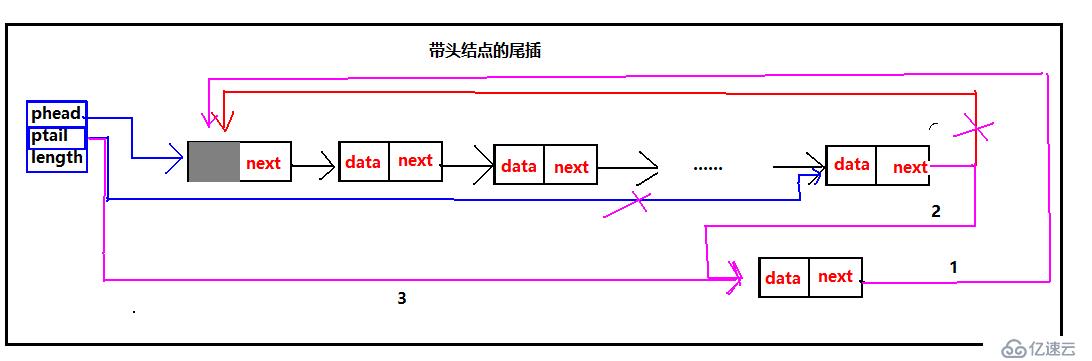
帶頭結點的尾插不論是空表還是有元素的表處理的情況是一樣,每次都要修改ptail的指向
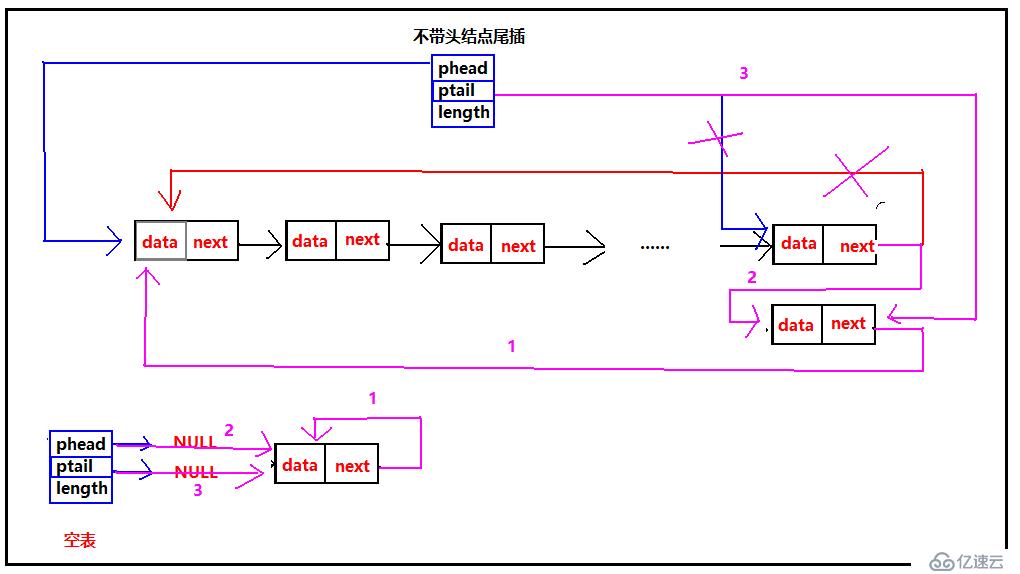
對于不帶頭結點的鏈表,需要注意空表時的情況,此時鏈表為空phead和ptail都指向空,所以就需要修改phead的指向。
具體實現代碼如下:
//不帶頭結點的循環單鏈表的尾插,插入成功返回RUE,失敗返回FALSE
Status Isert_No_Tail(list *head,ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
if(0 == head->length) //處理空鏈表的情況
{
head->Phead = head->Ptail = s;
}
s->next = head->Phead;
head->Ptail->next = s;
head->Ptail = s;
//帶頭結點的循環單鏈表尾插,插入成功返回RUE,失敗返回FALSE
Status Insert_Yes_Tail(list *head, ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
s->next = head->Phead;
head->Ptail->next = s;
head->Ptail = s;
head->length++;
return TRUE;
}
單循環鏈表的頭刪
我們繼續來循環單鏈表的頭刪的示意圖:
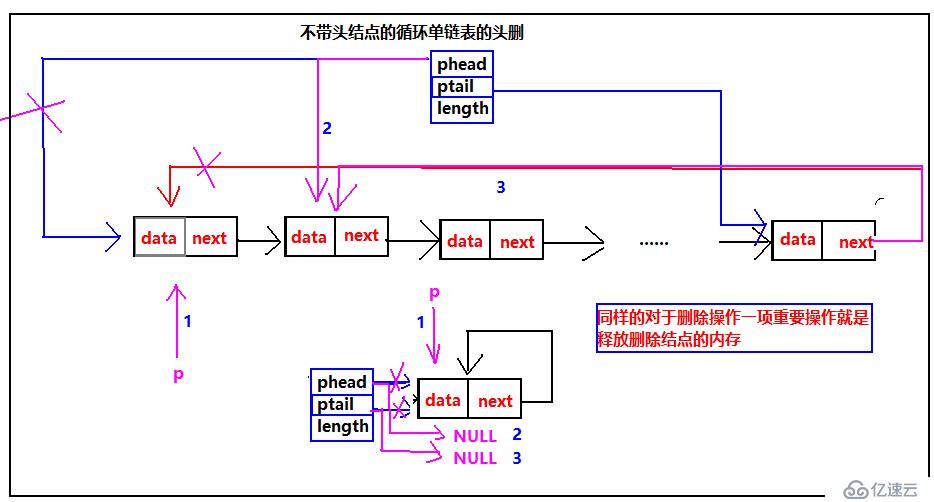
對于不帶頭結點的循環單鏈表,表中有多個元素的時候,按照步驟修改指向,特別注意一定要釋放刪除的結點內存,不讓會造成內存泄露,并且為了防止產生野指針,把指向刪除結點的指針指向NULL;頭刪一個結點的時候是一個種特殊情況,需要特別關注,需要把phead和ptail 的指向全部修改。
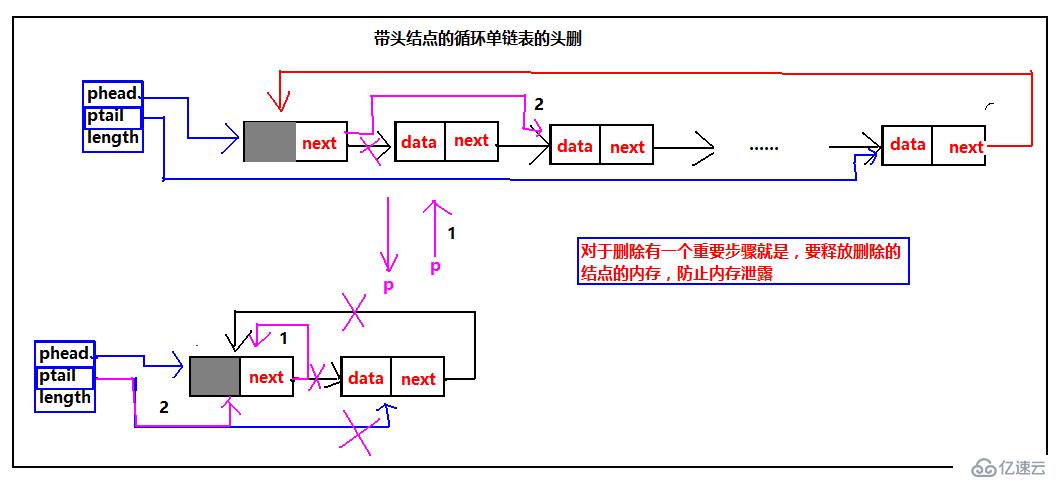
對于帶頭結點的循環單鏈表,表中元素較多時,依然是按照圖中標的步驟操作,這沒得說,當然也需要注意釋放刪除的結點的空間并把指針指向NULL;帶頭結點的循環單鏈表一個結點的時候,也是一種特殊情況。需要把ptail的指向修改,當然釋放內存空間,并把指針指向NULL,依然沒的說。
具體實現代碼如下:
//不帶頭結點的頭刪,刪除成功返回TRUE,失敗失敗返回FALSE;
Status Delite_No_Head(list *head,ElemType *x)
{
LinkNode p = head->Phead;
if(NULL == p)
{
printf("鏈表已空,不能刪除了\n");
return FALSE;
}
*x = p->data;
head->Phead = p->next;
head->Ptail->next = head->Phead;
if(1 == head->length) //處理只有一個結點的情況
{
head->Phead = NULL;
head->Ptail = NULL;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
//帶頭結點的頭刪,刪除成功返回TRUE,失敗失敗返回FALSE;
Status Delite_Yes_Head(list *head,ElemType *x)
{
LinkNode p = head->Phead->next;
if(head->Phead == p)
{
printf("鏈表已空,已經無法刪除\n");
return FALSE;
}
head->Phead->next = p->next;
*x = p->data;
if(1 == head->length) //處理只有一個結點的情況
{
head->Ptail = head->Phead;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
單循環鏈表的尾刪
最后我們來看循環單鏈表尾刪的示意圖:
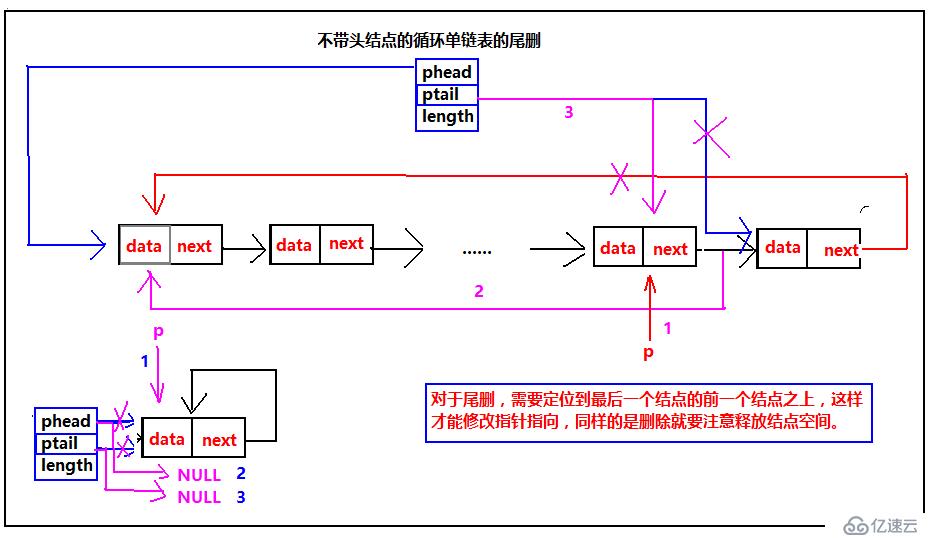
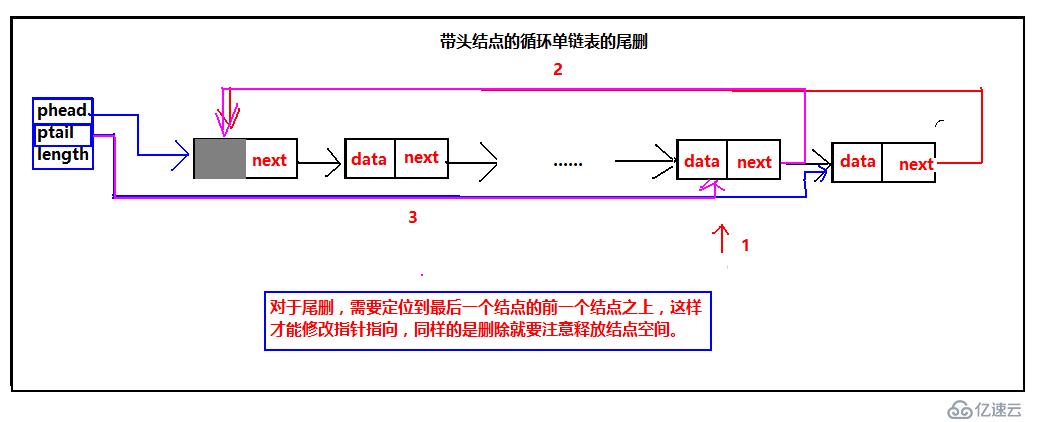
不管是帶頭結點還是不帶頭結點的循環單鏈表的尾刪,都需要定位到最后一個結點的前一個結點,只有前一個結點才知道后一個節點的內存,并且,尾刪的時候需要修改最后一個結點的前一個結點的指針指向。最后還是要強調一下釋放內存空間并且把指針指向指向NULL。需要注意:不帶頭結點的尾刪,當是一個結點的時候需要單獨處理。
//不帶頭結點的尾刪,刪除成功返回TRUE,失敗失敗返回FALSE;
Status Delite_No_Tail(list *head,ElemType *x)
{
LinkNode s = head->Phead;
if(NULL == s)
{
printf("鏈表已空,已經無元素可以刪除\n");
return FALSE;
}
if(1 == head->length) //處理只有一個結點的情況
{
head->Phead = head->Ptail = NULL;
*x = s->data;
head->length--;
return TRUE;
}
while(head->Ptail != s->next) //尋找最后一個結點的前一個結點
{
s = s->next;
}
*x = s->next->data;
head->Ptail = s;
free(s->next);
s->next = head->Phead;
head->length--;
return TRUE;
}
//帶頭結點尾刪,刪除成功返回TRUE,失敗失敗返回FALSE;
Status Delite_Yes_Tail(list *head,ElemType *x)
{
LinkNode s = head->Phead->next;
if(0 == head->length)
{
printf("鏈表已空,已經無元素可以刪除\n");
return FALSE;
}
while(head->Ptail != s->next) //尋找最后一個結點的前一個結點
{
s = s->next;
}
head->Ptail = s;
*x = s->next->data;
free(s->next);
s->next = head->Phead;
head->length--;
return TRUE;
}
以上就是按照我個人理解總結的單循環鏈表的基本操作,已經經過測試。上邊盡可能詳細的給出了操作的主要思想以及示意圖,代碼還有許多可以優化的地方。希望讀者提出意見和建議。雙循環鏈表的基本操作不在本篇總結了,在后續的博文中會對其按照我個人的理解總結。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





