溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享的是C++中的字符串編碼怎么處理,相信很多人都不太了解,為了讓大家更加了解,所以給大家總結了以下內容,一起往下看吧。一定會有所收獲的哦。
今天由于在項目中用到一些與C++混合開發的東西 ,需要通過socket與C++那邊交換數據,沒啥特別的,字節碼而已,兩邊確定一種編碼規則就行了。我們確定的UTF-8。關于C++的 這種又是寬字節 又是MessageBoxW 又是MessageBoxA 的 ,說實話相比C#而言 搞的確實非常的和稀泥 搞的非常的糊,別說新手 有些不是新手的都搞不明白。
什么是字符串?C#里的 string?C++里的char* ? 字符串的本質是什么?字符串不過是一個特殊的數據字節包裝 帶有編碼信息,特別是C++的 更原始 更便于我們想清楚這個底層,其實其他的已經迎刃而解了。首先我們無論如何確定一個東西 那就是交換的東西是字節碼 ,說白了 也就是C++ 里的char [ ] 也就是char *,在我不管你編碼的情況下 我新建VC++項目 在代碼里這樣寫:
char str1[] = "中a";
printf("%s\r\n", str1);能不能輸出東西?能不能輸出中文 當然能,那這個str1 字節碼到底是什么字節碼, 只要我們把這個搞明白就可以了。一切未知的恐懼源于不明白。我們先調試C++代碼 取到字節碼,然后編寫下面這兩句C#代碼:
byte[] bts2 = new byte[] { 0xd6, 0xd0, 0x61 };
Console.WriteLine(Encoding.GetEncoding("gb2312").GetString(bts2));正常輸出了C++代碼里的中文 由此可見C++里默認代碼到字節 的字面量轉換 就是gb2312 ,就這樣而已。就這樣而已 ,真的就這么點東西 ,不要探究是什么機制驅使VC++默認把字符串轉換到了gb2312編碼,事情不要歪呀歪的想想復雜了,人的精力是有限的 要放在有作用的地方。你看C++里是char [ ] 還不像C#的string經過包裝的 更便于你想明白這個過程。不是說C++有std庫么 不是有string 么 還沒講呢 ,C++這門語言呢又好又不好 設計特點是暴露的細節多 各個細節你都可以自己控制 讓會用的人知道自己在做什么 ,但是也有些坑,其實string 就是char[] 的變種而已。你看C++里 在你琢磨不透的情況下悄然在你不知情編碼的情況下轉換成了字節碼,C#的string 封裝的 不會給你這個機會 有明確的Encoding庫調用指定編碼。
C++里字符串的字面量分為兩種 一種是普通的窄字符 ,也就是普通的char [ ] 一個元素占1字節, 另一種是寬字符 wchar_t [ ] 一個元素占2字節,_T("中a") 或者L"中a" 這種就是強行表示Unicode寬字符字面量。 寬字符 怎么個寬法呢,我們說他是Unicode 也就是utf-16,我們用C#進行驗證:
byte[] bts3 = new byte[] { 0x2d,0x4e, 0x61,0x00, };
Console.WriteLine(Encoding.Unicode.GetString(bts3));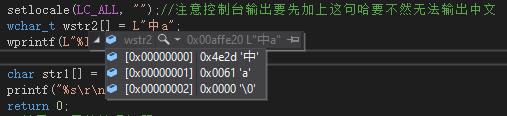

好了,這就明朗了,C++這玩意兒 由于歷史遺留原因,直接在代碼書寫字符串字面量搞了兩套標準 窄字符和寬字符 ,你看上面的同字符里面的字節碼整的兩套標準 這就很扯,整的被迫大多數C++的函數 或者接口都要按照這個套路玩。就有了看到的MessageBoxA ()接受char[]窄字符參數,MessageBoxW()接受寬字符參數 ,不要有誤區哈 覺得char[ ] 就不能輸出中文 ,能不能是由對應的地方能不能解析這個字節碼決定的 而不是其他。
utf-8的現實意義更大于編程的字面量意義 ,為什么這么說,現在網絡 數據交換都是UTF-8 編碼,C++編程 字面量 沒有所謂UTF-8這個說法 ,UTF-8是一種落地編碼,落地編碼 懂嗎?就像圖像編程 保存最終格式有.jpg .png,utf-8 他是變長的 對于字符串處理會出現很多問題 不利于程序處理,圖像編程中不管你jpg png格式也好載入到內存中最后都是易于處理的BMP內存映像。編程中都是Unicode因為2字節代表一個字符 標標準準的 是對齊的,利于編程處理。還有 utf-8 一個中文3字節 其實比utf-16 一個中文2字節 多, 但是如果是英文的話 就是1字節 可以實現Unicode到ASCII的無縫轉換 可以處理一些老舊系統的兼容問題。 C++里Unicode可以通過手段轉換為UTF-8:
void UnicodeToUtf8(const wchar_t* unicode,char utf82[],int * lenout)
{
int len;
len = WideCharToMultiByte(CP_UTF8, 0, unicode, -1, NULL, 0, NULL, NULL);
char szUtf82[50] = { 0 };
*lenout = len;
WideCharToMultiByte(CP_UTF8, 0, unicode, -1, utf82, len, NULL, NULL);
}什么意思呢:
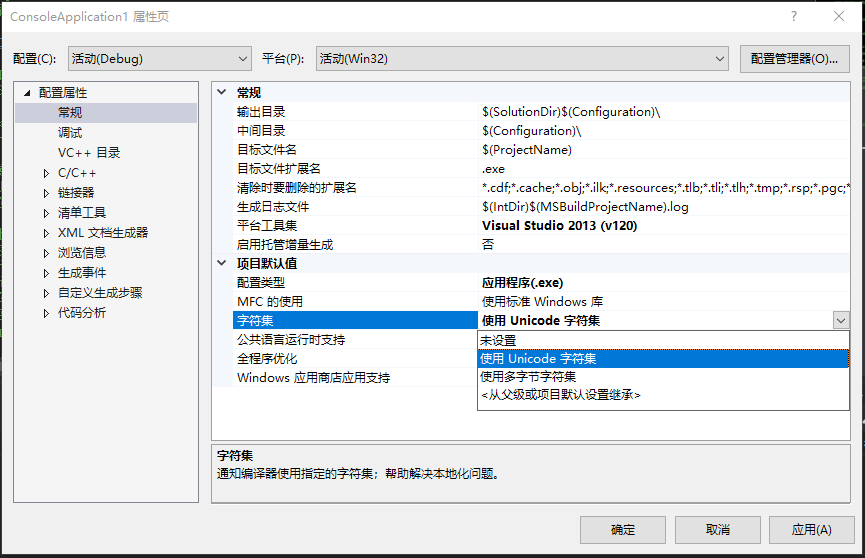
當選擇“使用Unicode字符集”時,編譯器會增加宏定義——UNICODE;而選擇“使用多字節字符集”時,編譯器則不會增加宏定義——UNICODE。https://blog.csdn.net/huashuolin001/article/details/95620424
當選用“使用Unicode字符集”時,調用函數MessageBox,實際使用的是MessageBoxW,MessageBoxW關于字符串的入參類型是LPCWSTR,使用MessageBox時,字符串前需加L::MessageBox(NULL, L"這是一個測試程序!", L"Title", MB_OK);
多字節,默認的窄字符char[]帶中文 就是典型的多字節,接上面章節說明 多字節+中文 對于字符串處理分割 會帶來很多問題,所以帶中文請盡量使用寬字符。然后另一個 基于gb2312和Unicode編碼我就不細說了哈,如果你想你的程序能夠賣到國外在世界范圍內使用,那么請使用Unicode,也就是 L" " 寬字符。C++里這些概念搞的比較糊 ,我描述的這些也是個意會 ,也許某些細節部分說錯了 像原來文章里那些評論里那樣 尖銳的指出來 不怕批評。
最后 ,一些測試的大雜燴代碼:
// ConsoleApplication1.cpp : 定義控制臺應用程序的入口點。
//
#include "stdafx.h"
#include <iostream>
#include "h2.h"
#include "FqTabData.h"
#include "test1.h"
#include <windows.h>
#include <string>
#include <iomanip>
#include <type_traits>
using namespace std;
//引用的使用方式
void test1(int &r){
r = r+1;
}
void UnicodeToUtf8(const wchar_t* unicode,char utf82[],int * lenout)
{
int len;
len = WideCharToMultiByte(CP_UTF8, 0, unicode, -1, NULL, 0, NULL, NULL);
char szUtf82[50] = { 0 };
*lenout = len;
WideCharToMultiByte(CP_UTF8, 0, unicode, -1, utf82, len, NULL, NULL);
}
int _tmain(int argc, _TCHAR* argv[])
{
setlocale(LC_ALL, "");//注意控制臺輸出要先加上這句哈要不然無法輸出中文
wchar_t wstr2[] = L"中a";
wprintf(L"%ls\r\n", wstr2);
char str1[] = "中ab";
printf("%s\r\n", str1);
return 0;
//關于c++里的編碼問題
// 并非 不在在項目屬性里設置編碼字符集 為Unicode 就不能顯示中文
//char str11[] = "中a"; printf("%s", str11);
//這段代碼照樣顯示中文,中a被編譯器編成3個元素存在str11 里+\0結尾
//當選擇“使用Unicode字符集”時,編譯器會增加宏定義——UNICODE;而選擇“使用多字節字符集”時,編譯器則不會增加宏定義——UNICODE。
//https://blog.csdn.net/huashuolin001/article/details/95620424
//當選用“使用Unicode字符集”時,調用函數MessageBox,實際使用的是MessageBoxW,MessageBoxW關于字符串的入參類型是LPCWSTR,
//使用MessageBox時,字符串前需加L
//::MessageBox(NULL, L"這是一個測試程序!", L"Title", MB_OK);
//關于這個L ,等同于_T("") Tchar 這些玩意兒他們都有同等意義
//可以傻瓜的理解 L 本身就是搞一個寬字符型 字符串 ,每個字符占2字節
//wchar_t ws[] = L"國家";
//設置為Unicode 就意味著寬字符 就意味著字符串 要加L
//就像前面的 好多函數接口有兩種版本 MessageBoxA MessageBoxW ,
//MessageBoxW就意味著你要傳一個寬字符數組進去 也就是 wchar_t 或者L"dd"
//注意多字節字符集是一個很容易讓人費解的玩意兒,
//我們說 utf-8是 一種Unicode的落地編碼
//編程里都是用 Unicode 不管項目設沒設置Unicode字符集 wchar_t ws[] = L"國家"; 得到的都是寬字符串
//但是編程代碼里 沒有utf-8 這一說法 utf-8是變長的 也就是多字節 他是一種編碼落地
//你想想你整個變長 別人接口怎么寫 ,怎么達到在讓你用變長省內存的同時 識別你的有效字符
//如果數組里存utf-8 你想想 別人要以字節數讀字符 半個的時候怎么搞
//這跟gdi圖像處理是同一個道理 jpg png 各種是落地格式都可以讀進來 但是到內存都是bmp
//還有不論哪種printf 或者其他接口 都不支持所謂的utf-8的參數 也沒這種接口可言
//https://zhuanlan.zhihu.com/p/23190549
//前幾天在微博上受到了@Belleve給我的啟發,于是簡單地實現了幾個在 Windows
//下接受 UTF - 8 參數的 printf 系列函數。大致思路是判斷當前 stdout / stderr
//是否為控制臺,如果是控制臺則將參數轉為 UTF - 16 后調用 wprintf 輸出,否則不轉換直接調用 printf。
//L 是一個很微妙的 ,稱之為轉換為寬字符的字面量 什么叫字面量 根據你當前編程環境 以及源代碼編碼 轉換成對應的字節
//L"發" 字面量 你細品
setlocale(LC_ALL, "");
printf("--------------------");
//wchar_t wc = L'破';
std::wstring wstr = L"破a的";
std::cout << wstr.size() << std::endl;
//utf-8 只是流行 ,事實上utf-8 一個漢字要占3字節 而utf-16一個漢字一字節
/*wchar_t wstr2[] = L"破曉S";
wprintf(L"%ls", wstr2);*/
printf("--------------------//");
char utf82[50] = { 0 };
int len = 0;
UnicodeToUtf8(wstr2, utf82, &len);
//char* str222 = UnicodeToUtf8(wstr2);
//printf("%S", str222);
//printf("aaa");
return 0;
//
//c++ 中指針的變種 引用的使用方式
printf("aaa\r\n");
int a = 123;
int& b = a;
a = 456;
printf("%d \r\n", b);
test1(b);
printf("%d \r\n", b);
int c = 345;
test1(c);
printf("%d \r\n", c);
return 0;
}關于C++中的字符串編碼怎么處理就分享到這里了,希望以上內容可以對大家有一定的參考價值,可以學以致用。如果喜歡本篇文章,不妨把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





