溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“基于prompt tuning v2怎么訓練好一個垂直領域的chatglm-6b”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
官方的廣告數據集是如下結構的
{
"content": "類型#上衣*版型#寬松*版型#顯瘦*圖案#線條*衣樣式#襯衫*衣袖型#泡泡袖*衣款式#抽繩",
"summary": "這件襯衫的款式非常的寬松,利落的線條可以很好的隱藏身材上的小缺點,穿在身上有著很好的顯瘦效果。領口裝飾了一個可愛的抽繩,漂亮的繩結展現出了十足的個性,配合時尚的泡泡袖型,盡顯女性甜美可愛的氣息。"
}官方的多輪對話數據集是如下結構的
{
"prompt": "是的。上下水管都好的",
"response": "那就要檢查線路了,一般風扇繼電器是由電腦控制吸合的,如果電路存在斷路,或者電腦壞了的話會出現繼電器不吸合的情況!",
"history": [
[
"長城h4風扇不轉。繼電器好的。保險絲好的傳感器新的風扇也新的這是為什么。就是繼電器缺一個信號線",
"用電腦能讀數據流嗎?水溫多少"
],
[
"95",
"上下水管溫差怎么樣啊?空氣是不是都排干凈了呢?"
]
]
}今天的所有實驗都是探索單輪生成chatglm-6B上的適配性。
ptuning chatglm 6B中有兩個數據集作為標準的官方微調數據集案例
我們看一下ptuning chatglm 6B中的啟動參數有哪些。
PRE_SEQ_LEN=128 LR=2e-2 CUDA_VISIBLE_DEVICES=0 python3 main.py \ --do_train \ --do_eval \ --train_file AdvertiseGen/patent_train.32.128.512.json \ --validation_file AdvertiseGen/patent_dev.32.128.512.json \ --prompt_column content \ --response_column summary \ --overwrite_cache \ --model_name_or_path THUDM/chatglm-6b \ --output_dir output/patent_dev-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ --overwrite_output_dir \ --max_source_length 128 \ --max_target_length 512 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 16 \ --predict_with_generate \ --max_steps 3000 \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate $LR \ --fp16 False\ --pre_seq_len $PRE_SEQ_LEN
PRE_SEQ_LEN 預序列長度
LR 學習率
do_train 是否進行訓練
do_eval 是否進行預測
train_file 訓練文件相對地址
validation_file 驗證文件相對地址
prompt_column prompt 提示信息字段
response_column 響應信息字段
overwrite_cache 重寫數據集緩存。
model_name_or_path 模型名稱或模型地址
output_dir 訓練好的模型保存的地址
per_device_train_batch_size 每個設備上的訓練批次大小 在實際的訓練過程中3090顯卡可以把這個參數開到4。
模型的指令輸入應該如何拼接才可以讓chatglm更好的服務。
train.sh 中的 PRE_SEQ_LEN 和 LR 分別是 soft prompt 長度和訓練的學習率,可以進行調節以取得最佳的效果。P-Tuning-v2 方法會凍結全部的模型參數,可通過調整 quantization_bit 來被原始模型的量化等級,不加此選項則為 FP16 精度加載。 在默認配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型參數被凍結,一次訓練迭代會以 1 的批處理大小進行 16 次累加的前后向傳播,等效為 16 的總批處理大小,此時最低只需 6.7G 顯存。若想在同等批處理大小下提升訓練效率,可在二者乘積不變的情況下,加大 per_device_train_batch_size 的值,但也會帶來更多的顯存消耗,請根據實際情況酌情調整。
編輯切換為居中
添加圖片注釋,不超過 140 字(可選)
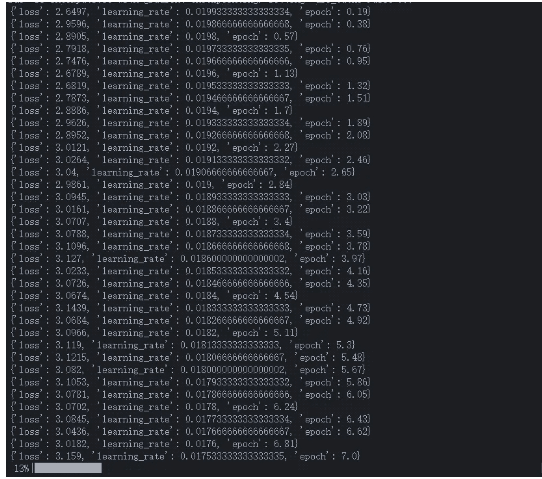
基于openbayes的3090單卡,prompt tuning v2 訓練chatglm 6B模型。
訓練專利prompt的數據的時候基礎訓練參數 修改了 per_device_train_batch_size 為 4。
***** Running training ***** Num examples = 3384 Num Epochs = 58 Instantaneous batch size per device = 4 Total train batch size (w. parallel, distributed & accumulation) = 64 Gradient Accumulation steps = 16 Total optimization steps = 3000 Number of trainable parameters = 29360128
其中每一個設備的batch size設定為4,總共訓練的批次大小是64。這里的總批次是因為采用了梯度累計策略,所以總訓練批次大小是64。那如果是兩張卡的話這里是128。
編輯切換為居中
添加圖片注釋,不超過 140 字(可選)
中國大百科數據集

編輯切換為居中
添加圖片注釋,不超過 140 字(可選)
PyTorch DataParallel和DDP是PyTorch提供的兩個數據并行擴展。 1. PyTorch Data Parallel PyTorch Data Parallel是PyTorch框架中的一個重要組成部分,它提供了一種高效的并行計算機制,使得在GPU上運行Torch模型變得更加容易。Data Parallel使用GPU上的多線程來并行計算多個輸入特征,從而提高計算效率。 Data Parallel的實現方式包括: - Data parallel器:負責將輸入特征按照一定的規則劃分成一組數據 parallel,例如按照相似度、長度、形狀等特征進行劃分。 - 并行化操作:將數據 parallel劃分為多個并行塊,并執行相應的操作。 - 數據預處理:對數據parallel塊進行一些預處理,例如合并、排序、歸一化等操作。 使用Data Parallel可以大大簡化GPU編程,并提高模型的訓練效率。 2. DDP 官方建議用新的DDP,采用all-reduce算法,本來設計主要是為了多機多卡使用,但是單機上也能用,使用方法如下:
初始化使用nccl后端
torch.distributed.init_process_group(backend="nccl")
模型并行化
model=torch.nn.parallel.DistributedDataParallel(model)
需要注意的是:DDP并不會自動shard數據 1. 如果自己寫數據流,得根據torch.distributed.get_rank()去shard數據,獲取自己應用的一份 2. 如果用Dataset API,則需要在定義Dataloader的時候用DistributedSampler 去shard:
sampler = DistributedSampler(dataset) # 這個sampler會自動分配數據到各個gpu上 DataLoader(dataset, batch_size=batch_size, sampler=sampler)
在chatglm 6B中訓練的并行是基于transformers架構實現的
from transformers.trainer import Trainer
trainer默認是用torch.distributed的api來做多卡訓練的,因此可以直接支持多機多卡,單機多卡,單機單卡。
目前autodl沒有多卡資源,所以也沒辦法驗證多卡這個如何可以更高效率的執行出來有效的結果。
autodl 模型下載速度比較慢 可以通過在新建環境時候選擇合適的thuglm鏡像來減少模型下載上所需要的時間。實例初始化空間為20GB系統空間+50GB數據空間,數據空間可以擴容。
openbayes 模型下載速度比較快,環境每次重啟的時候都要執行一遍pip install安裝步驟。啟動訓練是需要在命令行中加上 --fp16 False,不然會報錯。實例硬盤上限只有50GB,需要注意保存策略。存儲空間費用如下。
用我的專用邀請鏈接,注冊 OpenBayes,雙方各獲得 60 分鐘 RTX 3090 使用時長,支持累積,永久有效:
注冊 - OpenBayes
要不是autodl沒有卡,我也不會來openbayes租用顯卡。最吐槽的問題就是硬盤空間問題。作為個人研究者還要為硬盤按月付費實在是讓人不舒服。目前我付費了100GB的硬盤。一個月80多塊。
“基于prompt tuning v2怎么訓練好一個垂直領域的chatglm-6b”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





