溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Kubernetes調度管理優先級和搶占機制是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
在日常工作中,每個機場都有調度室,用來管理飛機應該從哪里降落,停在什么地方。在Kubernetes也有這樣的調度器,主要作用就是將Pod安排到合適的節點上。
Kubernetes中的調度器是kube-scheduler,工作流程如下:
在集群中所有Node中,根據調度算法挑選出可以運行該Pod的所有Node;
在上一步的基礎上,再根據調度算法給篩選出的Node進行打分,篩選出分數最高的Node進行調度;
將Pod的spec.nodeName填上調度結果的Node名字;
其原理圖如下:
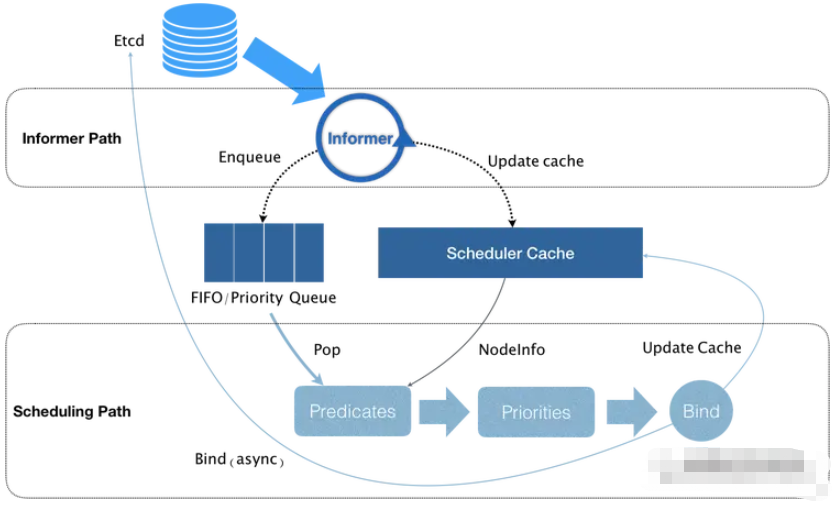
由上圖可知,Kubernetes的調度器核心是兩個相互獨立的控制循環。
1、Informer Path其主要作用是啟動一個Informer來監聽Etcd中Pod,Node,Service等與調度器相關的API對象的變化。當一個Pod被創建出來后,就被通過Informer Handler將待調度的Pod放入調度隊列中,默認情況下,Kubernetes的調度策略是一個優先級隊列,并且當集群信息發生變化的時候,調度器還會對調度隊列里的內容進行一些特殊操作。而且Kubernetes的默認調度器還負責對調度器緩存(scheduler cache)進行更新,以執行調度算法的執行效率。
2、Scheduler Path其主要邏輯是不斷從隊列中出一個Pod,然后調用Predicates進行過濾,然后得到一組Node(也就是可運行Pod的所有Node信息,這些信息都是來自scheduler cache),接下來調用Priorities對篩選出的Node進行打分,然后分數最高的Node會作為本次調度選擇的對象。調度完成后,調度器需要將Pod的spec.nodeName的值修改為調度的Node名字,這個步驟稱為Bind。
但是在Bind階段,Kubernetes默認調度器只會更新scheduler cache中的信息,這種基于樂觀假設的API對象更新方式被稱為Assume。在Assume之后,調度器才會向API Server發起更新Pod的請求,來真正完成Bind操作。如果本次Bind失敗,等到scheduler cache更新之后又會恢復正常。
正是由于有Assume的原因,當一個Pod完成調度需要在某個Node節點運行之前,kubelet還會進行一步Admit操作來驗證該Pod是否能夠運行在該Node上,作為kubelet的二次驗證。
常用的預算策略有:
CheckNodeCondition
GeneralPredication:
HostName, PodFitsHostPort, MatchNodeSelector, PodFitsResources
NoDiskConflict
正常情況下,當一個Pod調度失敗后,它會被擱置起來,直到Pod被更新,或者集群狀態發生變化,調度器才會對這個Pod進行重新調度。但是有的時候我們不希望一個高優先級的Pod在調度失敗就被擱置,而是會把某個Node上的一些低優先級的Pod刪除,來保證高優先級的Pod可以調度成功。
Kubernetes中優先級是通過ProrityClass來定義,如下:
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false description: "This priority class should be used for high priority service pods only."
其中的value就是優先級數值,數值越大,優先級越高。優先級是一個32bit的整數,最大值不超過10億,超過10億的值是被Kubernetes保留下來作為系統Pod使用的,就是為了保證系統Pod不會被搶占。另外如果globalDefault的值設置為 true的話表明這個PriorityClass的值會成為系統默認值,如果是false就表示只有在申明這個PriorityClass的Pod才會擁有這個優先級,而對于其他沒有申明的,其優先級為0。
如下定義Pod并定義優先級:
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent priorityClassName: high-priority
上面的PriotiryClassName就是定義我們的PriorityClass,當這個Pod提交給Kubernetes之后,Kubernetes的PriorityAdmissionController會自動將這個Pod的spec.priority字段設置為我們定義的值。而當這個Pod擁有這個優先級之后,高優先級的Pod就可能比低優先級的Pod先出隊,從而盡早完成調度。
而當一個高優先級的Pod調度失敗后,其搶占機制就會被觸發,這時候調度器就會試圖從當前的集群中尋找一個節點,使得這個節點上的一個或多個低優先級的Pod被刪除,然后這個高優先級的Pod就可以被調度到這個節點上。當搶占發生時,這個高優先級Pod并不會立即調度到即將搶占的節點上,調度器只會將這個Pod的spec.nominatedNodeName的值設置為被搶占節點的Node名字,然后這個Pod會重新進入下一個調度周期,然后會在這個周期內決定這個Pod被調度到哪個節點上。在這個重新調度期間,如果有一個更高的優先級Pod也要搶占這個節點,那么調度器就會清空原Pod的nominatedNodeName的值,而更高優先級的Pod將會搶占這個值。
**實現原理:**Kubernetes用兩個隊列來實現搶占算法:ActiveQ和unschedulableQ。
ActiveQ:凡是在ActiveQ里的Pod,都是下一個周期需要調度的對象,所以當Kubernetes創建一個新的Pod,這個Pod就會被放入ActiveQ里;
unschedulableQ:專門用來存放調度失敗的Pod;
那么如果一個Pod調度失敗,調度器就會將其放入unschedulableQ里,然后調度器會檢查這個調度失敗的原因,分析并確認是否可以通過搶占來解決此次調度問題,如果確定搶占可以發生,那么調度器就會把自己緩存的所有信息都重新復制一份,然后使用這個副本來模擬搶占過程。如果模擬通過,調度器就會真正開始搶占操作了:
調度器會檢查犧牲者列表,清空這些Pod所攜帶的nominatedNodeName字段;
調度器會把搶占者的nominatedNodeName的字段設置為被搶占的Node名字;
調度器會開啟Goroutine,同步的刪除犧牲者;
接下來調度器就會通過正常的調度流程,把搶占者調度成功。在這個過程中,調度器會對這個Node,進行兩次Predicates算法:
假設上述搶占者已經運行在這個節點上,然后運行Predicates算法;
調度器正常執行Predicates算法;
只有上述者兩個都通過的情況下,這個Node和Pod才會被 綁定。
上面介紹的是Kubernetres默認的調度策略,有時候默認的調度策略不能滿足我們的需求,比如想把Pod調度到指定的節點,或者不讓某些節點調度Pod。這時候就要用到更高級的調度策略,主要有如下幾種:
nodeSelector
nodeName
nodeAffinity
podAffinity
podAntiAffinity
污點調度
nodeSelector也可以叫做節點選擇器,其原理是通過在節點上定義label標簽,然后Pod中指定選擇這些標簽,讓Pod能夠調度到指定的節點上。
比如給kk-node01指定env=uat標簽,命令如下:
$ kubectl label nodes kk-node01 env=uat
現在在Pod的YAML清單中配置nodeSelector,如下:
apiVersion: v1 kind: Pod metadata: name: pod-nodeselector spec: containers: - name: myapp image: ikubernetes/myapp:v1 nodeSelector: env: uat
這樣,該Pod就會調度到kk-node01節點上,如果該Pod指定為env=prod,則調度不到kk-node01節點。
nodeName也是節點選擇器,和nodeSelector不同之處在于nodeName是直接指定節點名,這屬于強調度,定義方式如下:
apiVersion: v1 kind: Pod metadata: name: pod-nodename spec: containers: - name: myapp image: ikubernetes/myapp:v1 nodeName: kk-node01 # 節點名字
nodeAffinity叫做節點親和性調度,其調度方式比nodeSelector和nodeName更強大。
目前,nodeAffinity支持兩種調度策略:
preferredDuringSchedulingIgnoredDuringExecution
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution表示如果有Node匹配,則優先調度到該Node,如果沒有,可以根據配置調度到其他節點。requiredDuringSchedulingIgnoredDuringExecution則表示必須滿足條件的節點才允許調度。
定義preferredDuringSchedulingIgnoredDuringExecution的例子如下:
apiVersion: v1 kind: Pod metadata: name: pod-nodeaffinity-preferred spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - preference: matchExpressions: - key: disktype operator: In values: ["ssd", "harddisk"] weight: 60
requiredDuringSchedulingIgnoredDuringExecution的例子如下:
apiVersion: v1 kind: Pod metadata: name: pod-nodeaffinity-required spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: ["ssd", "harddisk"]
其中,operator支持In,NotIn, Exists, DoesNotExist. Gt, and Lt。
上面介紹的nodeSelector,nodeName,nodeAffinity都是針對節點的,下面介紹的podAffinity和podAntiAffinity則是針對Pod。
podAffinity表示Pod親和性調度,意識就是把Pod調度到與它比較緊密的Pod上,如下:
apiVersion: v1 kind: Pod metadata: name: fronted labels: app: myapp row: fronted spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: backend labels: app: db row: backend spec: containers: - name: db image: busybox imagePullPolicy: IfNotPresent command: - "/bin/sh" - "-c" - "sleep 3600" affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: ["myapp"] topologyKey: kubernetes.io/hostname
這表示把后端pod和前端pod調度在一起。
podAffinity也有preferredDuringSchedulingIgnoredDuringExecution和requiredDuringSchedulingIgnoredDuringExecution,也就是硬親和和軟親和,其使用情況和nodeAffinity一樣。
上面介紹了pod的親和性,這里介紹的podAntiAffinity則是Pod的反親和性,也就是說不將這類Pod調度到一起。在日常工作中,這種親和性使用頻率還比較高。微服務很少有單Pod,基本都是多個Pod,為了提高應用的高可用,不會將同應用的多個Pod調度到同一臺機器上,這時候就要用到podAntiAffinity,如下:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname containers: - name: nginx image: nginx
在Kubernetes中,有些節點自帶污點 ,比如Master節點,這類節點,如果Pod沒有配置容忍污點,則這些Pod不會調度到這類節點上。
在實際中,污點調度也是非常有用的,有些場景某些節點只允許某些項目組的Pod允許,比如大數據項目是一些高IO項目,不想和其他普通項目混合在一起,而其他項目如果使用標簽選擇器配置部署又比較麻煩,這時候就可以使用污點選擇器。
我們可以通過kubectl explain node.spec.taints來查看污點相關的配置信息:
$ kubectl explain node.spec.taints KIND: Node VERSION: v1 RESOURCE: taints <[]Object> DESCRIPTION: If specified, the node's taints. The node this Taint is attached to has the "effect" on any pod that does not tolerate the Taint. FIELDS: effect <string> -required- Required. The effect of the taint on pods that do not tolerate the taint. Valid effects are NoSchedule, PreferNoSchedule and NoExecute. Possible enum values: - `"NoExecute"` Evict any already-running pods that do not tolerate the taint. Currently enforced by NodeController. - `"NoSchedule"` Do not allow new pods to schedule onto the node unless they tolerate the taint, but allow all pods submitted to Kubelet without going through the scheduler to start, and allow all already-running pods to continue running. Enforced by the scheduler. - `"PreferNoSchedule"` Like TaintEffectNoSchedule, but the scheduler tries not to schedule new pods onto the node, rather than prohibiting new pods from scheduling onto the node entirely. Enforced by the scheduler. key <string> -required- Required. The taint key to be applied to a node. timeAdded <string> TimeAdded represents the time at which the taint was added. It is only written for NoExecute taints. value <string> The taint value corresponding to the taint key.
其中effect定義對Pod的排斥效果:
NoSchdule:僅影響調度過程,對現存在的Pod不產生影響;
NoExecute:不僅影響調度,而且還影響現存Pod,不容忍的Pod對象將被驅逐;
PreferNoSchedule:軟排斥,不是完全禁止Pod調度;
如果要給節點添加污點,則如下:
$ kubectl taint nodes kk-node01 node-type=dev:NoSchedule
給節點 kk-node01增加一個污點,它的鍵名是 node-type,鍵值是 dev,效果是 NoSchedule。這表示只有擁有和這個污點相匹配的容忍度的 Pod 才能夠被分配到 kk-node01這個節點。
如果要刪除污點,則使用如下命令:
$ kubectl taint nodes kk-node01 node-type=dev:NoSchedule-
如果要配置容忍污點,則如下:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 imagePullPolicy: IfNotPresent ports: - containerPort: 80 tolerations: - key: "node-type" operator: Equal value: dev effect: NoSchedule tolerationSeconds: 20
operator支持Equal和Exists,默認是Equal。
如果是Equal,表示污點的鍵值需要一致,如果使用Exists,則表示只要存在該鍵的污點,比如:
tolerations: - key: "key1" operator: "Exists" effect: "NoSchedule"
該配置表示只要匹配容忍度,并且key1的健存在即可調度。
如果一個容忍度的 key 為空且 operator 為 Exists, 表示這個容忍度與任意的 key、value 和 effect 都匹配,即這個容忍度能容忍任何污點。如果 effect 為空,則可以與所有鍵名 key1 的效果相匹配。
你可以給一個節點添加多個污點,也可以給一個 Pod 添加多個容忍度設置。Kubernetes 處理多個污點和容忍度的過程就像一個過濾器:從一個節點的所有污點開始遍歷, 過濾掉那些 Pod 中存在與之相匹配的容忍度的污點。余下未被過濾的污點的 effect 值決定了 Pod 是否會被分配到該節點,特別是以下情況:
如果未被忽略的污點中存在至少一個 effect 值為 NoSchedule 的污點, 則 Kubernetes 不會將 Pod 調度到該節點。
如果未被忽略的污點中不存在 effect 值為 NoSchedule 的污點, 但是存在 effect 值為 PreferNoSchedule 的污點, 則 Kubernetes 會 嘗試 不將 Pod 調度到該節點。
如果未被忽略的污點中存在至少一個 effect 值為 NoExecute 的污點, 則 Kubernetes 不會將 Pod 調度到該節點(如果 Pod 還未在節點上運行), 或者將 Pod 從該節點驅逐(如果 Pod 已經在節點上運行)。
例如,假設你給一個節點添加了如下污點
$ kubectl taint nodes node1 key1=value1:NoSchedule $ kubectl taint nodes node1 key1=value1:NoExecute $ kubectl taint nodes node1 key2=value2:NoSchedule
假定有一個 Pod,它有兩個容忍度:
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule" - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute"
在這種情況下,上述 Pod 不會被調度到上述節點,因為其沒有容忍度和第三個污點相匹配。但是如果在給節點添加上述污點之前,該 Pod 已經在上述節點運行, 那么它還可以繼續運行在該節點上,因為第三個污點是三個污點中唯一不能被這個 Pod 容忍的。
通常情況下,如果給一個節點添加了一個 effect 值為 NoExecute 的污點, 則任何不能忍受這個污點的 Pod 都會馬上被驅逐,任何可以忍受這個污點的 Pod 都不會被驅逐。但是,如果 Pod 存在一個 effect 值為 NoExecute 的容忍度指定了可選屬性 tolerationSeconds 的值,則表示在給節點添加了上述污點之后, Pod 還能繼續在節點上運行的時間。例如:
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute" tolerationSeconds: 3600
這表示如果這個 Pod 正在運行,同時一個匹配的污點被添加到其所在的節點, 那么 Pod 還將繼續在節點上運行 3600 秒,然后被驅逐。如果在此之前上述污點被刪除了,則 Pod 不會被驅逐。
在Kubernetes中,kube-scheduler負責將Pod調度到合適的Node上,但是Kubernetes是一個非常動態的,高度彈性的環境,有時候會造成某一個或多個節點pod數分配不均,比如:
一些節點利用率低下或過度使用
添加刪除標簽或添加刪除污點,pod或Node親和性改變等造成原調度不再滿足
一些節點故障,其上運行的Pod調度到其他節點
新節點加入集群
由于以上種種原因,可能導致多個Pod運行到不太理想的節點,而整個K8S集群也會處于一段時間不均衡的狀態,這時候就需要重新平衡集群。Descheduler就是這樣一個項目。
Descheduler可以根據一些規則配置來重新平衡集群狀態,目前支持的策略有:
RemoveDuplicates
LowNodeUtilization
RemovePodsViolatingInterPodAntiAffinity
RemovePodsViolatingNodeAffinity
RemovePodsViolatingNodeTaints
RemovePodsViolatingTopologySpreadConstraint
RemovePodsHavingTooManyRestarts
PodLifeTime
這些策略可以啟用,也可以關閉,默認情況下,所有策略都是啟動的。
另外,還有一些通用配置,如下:
nodeSelector:限制要處理的節點
evictLocalStoragePods: 驅除使用LocalStorage的Pods
ignorePvcPods: 是否忽略配置PVC的Pods,默認是False
maxNoOfPodsToEvictPerNode:節點允許的最大驅逐Pods數
由于我集群版本是1.24.2,所以安裝descheduler v0.24版本。
(1)下載對應的Helm chart,我這里選擇的是0.24版本
$ wget https://github.com/kubernetes-sigs/descheduler/releases/download/descheduler-helm-chart-0.24.0/descheduler-0.24.0.tgz
(2)如果可以科學上網,直接使用以下命令部署即可。
$ helm install descheduler .
如果不能科學上網,就替換鏡像,修改value.yaml里的鏡像信息,如下:
image: repository: registry.cn-hangzhou.aliyuncs.com/coolops/descheduler # Overrides the image tag whose default is the chart version tag: "v0.24.0" pullPolicy: IfNotPresent
然后再執行安裝命令。
安裝完成過后,會配置默認的調度策略,如下:
apiVersion: v1 data: policy.yaml: | apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: LowNodeUtilization: enabled: true params: nodeResourceUtilizationThresholds: targetThresholds: cpu: 50 memory: 50 pods: 50 thresholds: cpu: 20 memory: 20 pods: 20 RemoveDuplicates: enabled: true RemovePodsViolatingInterPodAntiAffinity: enabled: true RemovePodsViolatingNodeAffinity: enabled: true params: nodeAffinityType: - requiredDuringSchedulingIgnoredDuringExecution RemovePodsViolatingNodeTaints: enabled: true kind: ConfigMap metadata: annotations: meta.helm.sh/release-name: descheduler meta.helm.sh/release-namespace: default creationTimestamp: "2022-08-02T03:06:57Z" labels: app.kubernetes.io/instance: descheduler app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: descheduler app.kubernetes.io/version: 0.24.0 helm.sh/chart: descheduler-0.24.0 name: descheduler namespace: default resourceVersion: "894636" uid: 4ab2e628-9404-4e52-bd88-615f5e096d90
其中配置了:
LowNodeUtilization:設置了cpu\內存\pod水位,thresholds表示未充分利用,targetThresholds表示過度使用
RemoveDuplicates:開啟同節點只有一個Pod運行
RemovePodsViolatingInterPodAntiAffinity:刪除違反親和性的Pod
RemovePodsViolatingNodeAffinity:刪除不滿足Node親和性的Pod
RemovePodsViolatingNodeTaints:刪除不被Node污點容忍的Pod
并且會創建一個CronJob,周期性的執行調度均衡。
apiVersion: batch/v1 kind: CronJob metadata: annotations: meta.helm.sh/release-name: descheduler meta.helm.sh/release-namespace: default creationTimestamp: "2022-08-02T03:06:57Z" generation: 1 labels: app.kubernetes.io/instance: descheduler app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: descheduler app.kubernetes.io/version: 0.24.0 helm.sh/chart: descheduler-0.24.0 name: descheduler namespace: default resourceVersion: "898221" uid: e209e498-71cb-413f-97a9-372aea5442bc spec: concurrencyPolicy: Forbid failedJobsHistoryLimit: 1 jobTemplate: metadata: creationTimestamp: null spec: template: metadata: annotations: checksum/config: 5efec14c3638fa4028e25f3fa067758f13dcae442fe711439c7d0b2e9913d41e creationTimestamp: null labels: app.kubernetes.io/instance: descheduler app.kubernetes.io/name: descheduler name: descheduler spec: containers: - args: - --policy-config-file - /policy-dir/policy.yaml - --v - "3" command: - /bin/descheduler image: registry.cn-hangzhou.aliyuncs.com/coolops/descheduler:v0.24.0 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10258 scheme: HTTPS initialDelaySeconds: 3 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 name: descheduler resources: requests: cpu: 500m memory: 256Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL privileged: false readOnlyRootFilesystem: true runAsNonRoot: true terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /policy-dir name: policy-volume dnsPolicy: ClusterFirst priorityClassName: system-cluster-critical restartPolicy: Never schedulerName: default-scheduler securityContext: {} serviceAccount: descheduler serviceAccountName: descheduler terminationGracePeriodSeconds: 30 volumes: - configMap: defaultMode: 420 name: descheduler name: policy-volume schedule: '*/2 * * * *' successfulJobsHistoryLimit: 3 suspend: false status: lastScheduleTime: "2022-08-02T03:28:00Z" lastSuccessfulTime: "2022-08-02T03:28:03Z"
該Job會每2分鐘執行一次均衡調度。
以上就是“Kubernetes調度管理優先級和搶占機制是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





