溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Kubernetes 調度和資源管理,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
首先來看第一部分 - Kubernetes 的調度過程。如下圖所示,畫了一個很簡單的 Kubernetes 集群架構,它包括了一個 kube-ApiServer,一組 Web-hook Controllers,以及一個默認的調度器 kube-Scheduler,還有兩臺物理機節點 Node1 和 Node2,分別在上面部署了兩個 kubelet。
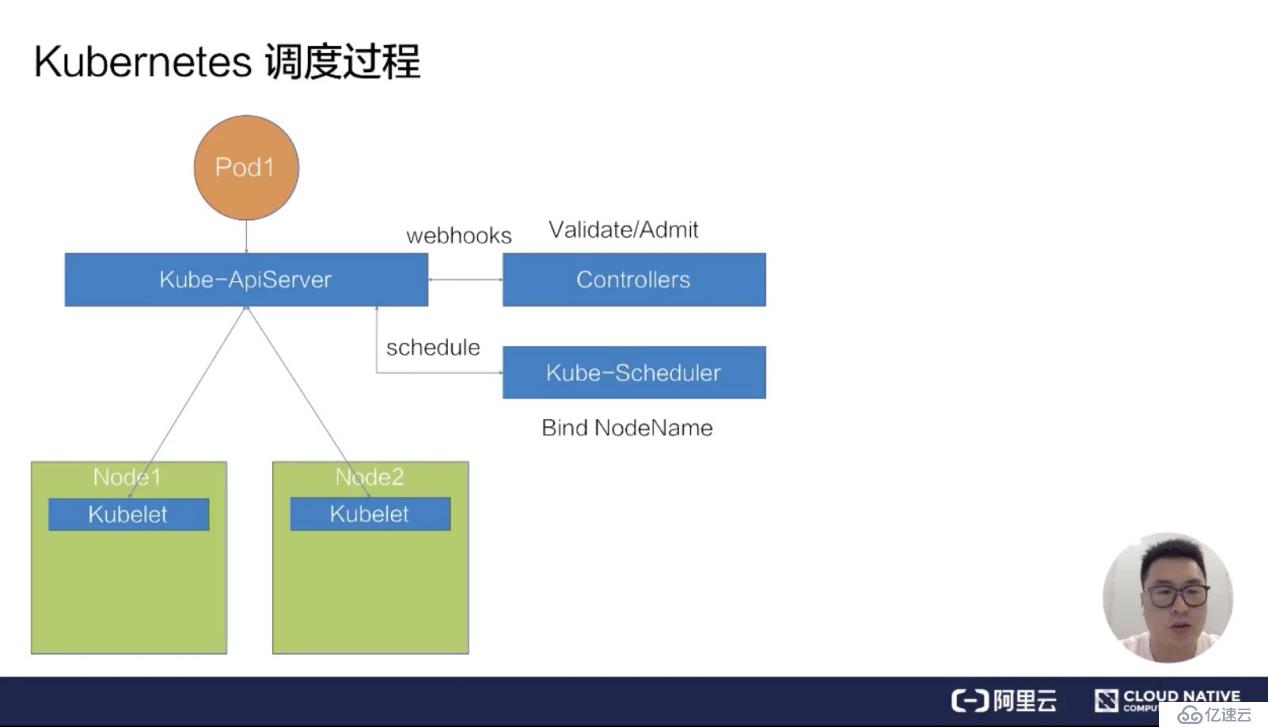
我們來看一下,假如要向這個 Kubernetes 集群提交一個 pod,它的調度過程是什么樣的一個流程?
假設我們已經寫好了一個 yaml 文件,就是下圖中的橙色圓圈 pod1,然后往 kube-ApiServer 里提交這個 yaml 文件。
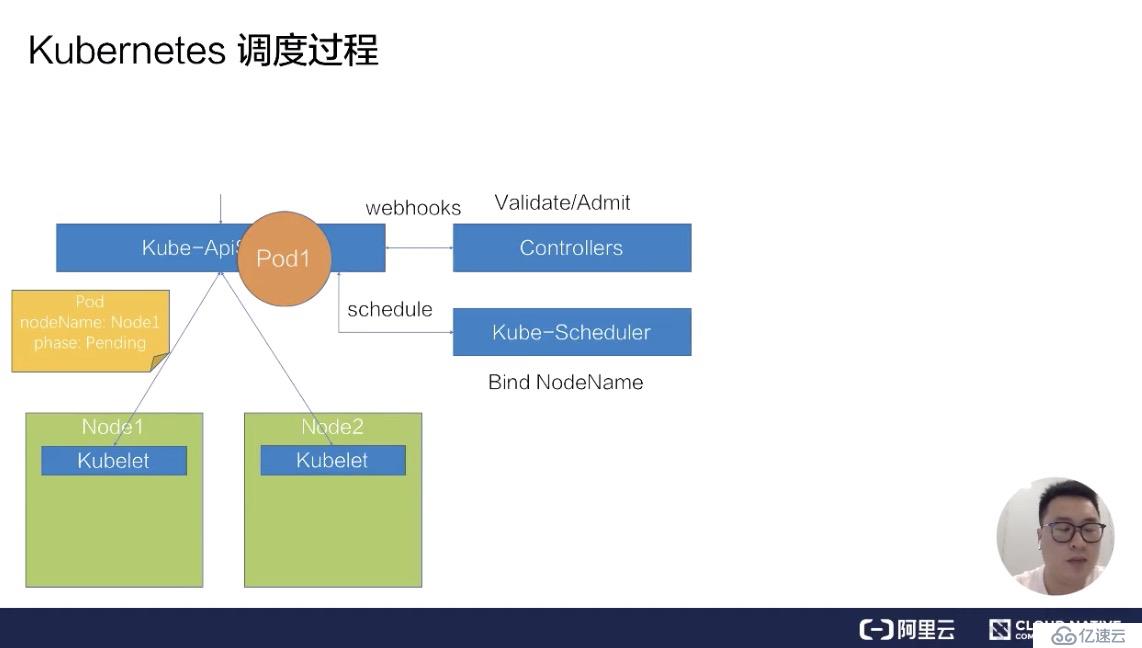
此時 ApiServer 會先把這個待創建的請求路由給我們的 webhook Controllers 進行校驗。
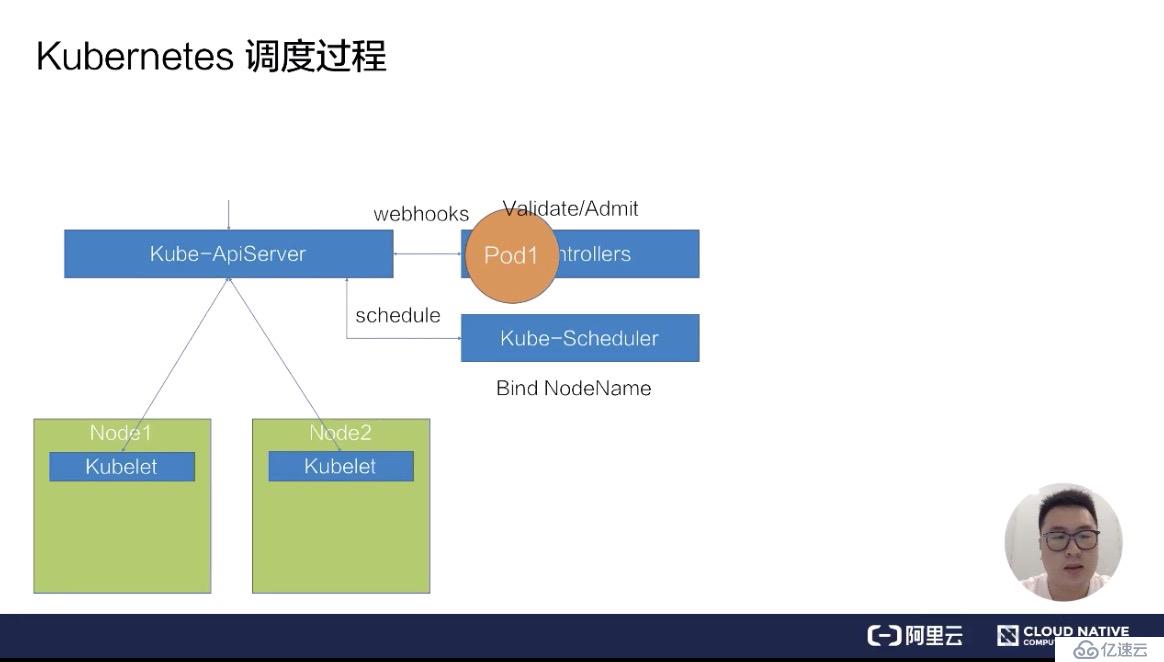
通過校驗之后,ApiServer 會在集群里面生成一個 pod,此時生成的 pod,它的 nodeName 是空的,并且它的 phase 是 Pending 狀態。在生成了這個 pod 之后,kube-Scheduler 以及 kubelet 都能 watch 到這個 pod 的生成事件,kube-Scheduler 發現這個 pod 的 nodeName 是空的之后,會認為這個 pod 是處于未調度狀態。
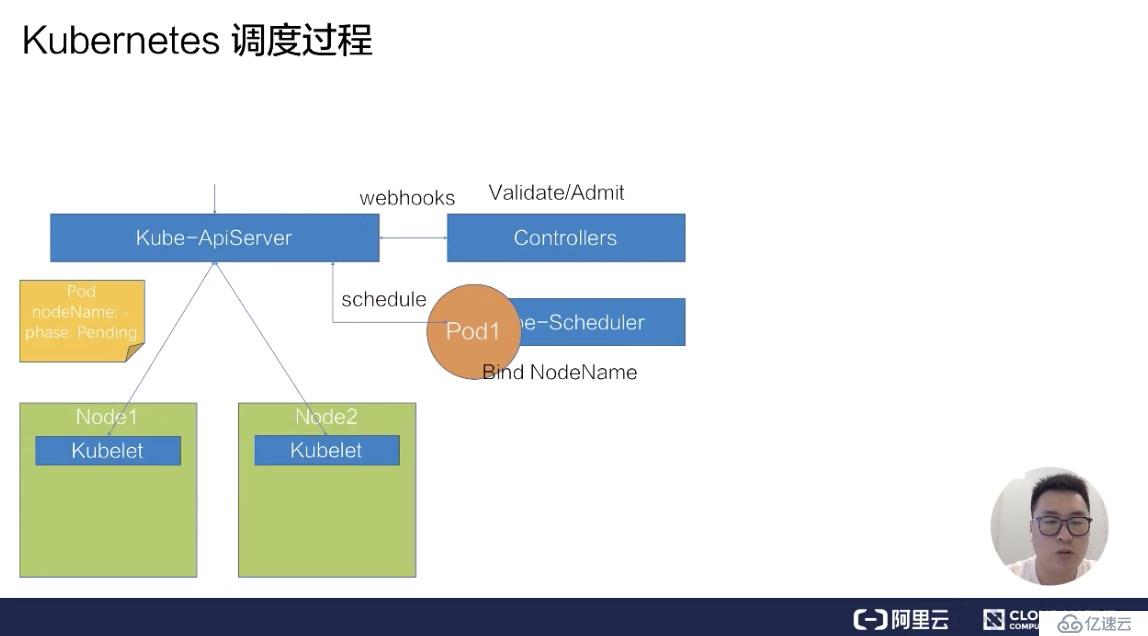
接下來,它會把這個 pod 拿到自己里面進行調度,通過一系列的調度算法,包括一系列的過濾和打分的算法后,Schedule 會選出一臺最合適的節點,并且把這一臺節點的名稱綁定在這個 pod 的 spec 上,完成一次調度的過程。
此時我們發現,pod 的 spec 上,nodeName 已經更新成了 Node1 這個 node,更新完 nodeName 之后,在 Node1 上的這臺 kubelet 會 watch 到這個 pod 是屬于自己節點上的一個 pod。
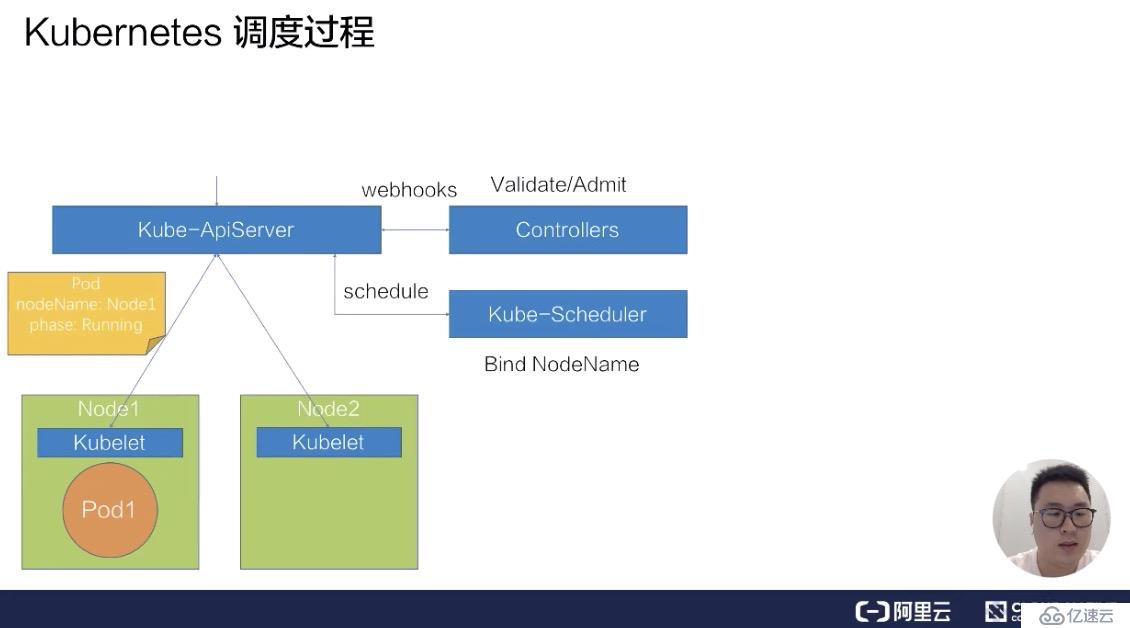
然后它會把這個 pod 拿到節點上進行操作,包括創建一些容器 storage 以及 network,最后等所有的資源都準備完成,kubelet 會把狀態更新為 Running,這樣一個完整的調度過程就結束了。
通過剛剛一個調度過程的演示,我們用一句話來概括一下調度過程:它其實就是在做一件事情,即把 pod 放到合適的 node 上。
這里有個關鍵字“合適”,什么是合適呢?下面給出幾點合適定義的特點:
首先要滿足 pod 的資源要求;
其次要滿足 pod 的一些特殊關系的要求;
再次要滿足 node 的一些限制條件的要求;
最后還要做到整個集群資源的合理利用。
做到以上的要求后,可以認為我們把 pod 放到了一個合適的節點上了。
接下來我會為大家介紹 Kubernetes 是怎么做到滿足這些 pod 和 node 的要求的。
下面為大家介紹一下 Kubernetes 的基礎調度能力,Kubernetes 的基礎調度能力會以兩部分來展開介紹:
第一部分是資源調度——介紹一下 Kubernetes 基本的一些 Resources 的配置方式,還有 Qos 的概念,以及 Resource Quota 的概念和使用方式;
第二部分是關系調度——在關系調度上,介紹兩種關系場景:
pod 和 pod 之間的關系場景,包括怎么去親和一個 pod,怎么去互斥一個 pod?
pod 和 node 之間的關系場景,包括怎么去親和一個 node,以及有一些 node 怎么去限制 pod 調度上來。

上圖是 pod spec 的一個 demo,我們的資源其實是填在 pod spec 中,具體在 containers 的 resources 里。
resources 包含兩個部分:
第一部分是 requests;
第二部分是 limits。
這兩部分里面的內容是一模一樣的,但是它代表的含義有所不同:request 代表的是對這個 pod 基本保底的一些資源要求;limit 代表的是對這個 pod 可用能力上限的一種限制。request、limit 的實現是一個 map 結構,它里面可以填不同的資源的 key/value。
我們可以大概分成四大類的基礎資源:
第一類是 CPU 資源;
第二類是 memory;
第三類是 ephemeral-storage,是一種臨時存儲;
第四類是通用的擴展資源,比如說像 GPU。
CPU 資源,比如說上面的例子填的是2,申請的是兩個 CPU,也可以寫成 2000m 這種十進制的轉換方式,來表達有些時候可能對 CPU 可能是一個小數的需求,比如說像 0.2 個CPU,可以填 200m。而這種方式在 memory 和 storage 之上,它是一個二進制的表達方式,如上圖右側所示,申請的是 1GB 的 memory,同樣也可以填成一個 1024mi 的表達方式,這樣可以更清楚地表達我們對 memory 的需求。
在擴展資源上,Kubernetes 有一個要求,即擴展資源必須是整數的,所以我們沒法申請到 0.5 的 GPU 這樣的資源,只能申請 1 個 GPU 或者 2 個 GPU。
這里為大家介紹完了基礎資源的申請方式。
接下來,我會詳細給大家介紹一下 request 和 limit 到底有什么區別,以及如何通過 request/limit 來表示 QoS。
K8S 在 pod resources 里面提供了兩種填寫方式:第一種是 request,第二種是 limit。
它其實是為用戶提供了對 Pod 一種彈性能力的定義。比如說我們可以對 request 填 2 個 CPU,對 limit 填 4 個 CPU,這樣代表了我希望是有 2 個 CPU 的保底能力,但其實在閑置的時候,可以使用 4 個 GPU。
說到這個彈性能力,我們不得不提到一個概念:QoS 的概念。什么是 QoS呢?QoS 全稱是 Quality of Service,它是 Kubernetes 用來表達一個 pod 在資源能力上的服務質量的標準,Kubernetes 提供了三類 QoS Class:
第一類是 Guaranteed,它是一類高 QoS Class,一般拿 Guaranteed 配置給一些需要資源保障能力的 pods;
第二類是 Burstable,它是中等的一個 QoS label,一般會為一些希望有彈性能力的 pod 來配置 Burstable;
第三類是 BestEffort,它是低QoS Class,通過名字我們也知道,它是一種盡力而為式的服務質量,K8S不承諾保障這類Pods服務質量。
K8s 其實有一個不太好的地方,就是用戶沒法直接指定自己的 pod 是屬于哪一類 QoS,而是通過 request 和 limit 的組合來自動地映射上 QoS Class。
通過上圖的例子,大家可以看到:假如我提交的是上面的一個 spec,在 spec 提交成功之后,Kubernetes 會自動給補上一個 status,里面是 qosClass: Guaranteed,用戶自己提交的時候,是沒法定義自己的 QoS 等級。所以將這種方式稱之為隱性的 QoS class 用法。
接下來介紹一下,我們怎么通過 request 和 limit 的組合來確定我們想要的 QoS level。
Guaranteed Pod

首先我們如何創建出來一個 Guaranteed Pod?
Kubernetes 里面有一個要求:如果你要創建出一個 Guaranteed Pod,那么你的基礎資源(包括 CPU 和 memory),必須它的 request==limit,其他的資源可以不相等。只有在這種條件下,它創建出來的 pod 才是一種 Guaranteed Pod,否則它會屬于 Burstable,或者是 BestEffort Pod。
Burstable Pod
然后看一下,我們怎么創建出來一個 Burstable Pod,Burstable Pod 的范圍比較寬泛,它只要滿足 CPU/Memory 的 request 和 limit 不相等,它就是一種 Burstable Pod。

比如說上面的例子,可以不用填寫 memory 的資源,只要填寫 CPU 的資源,它就是一種 Burstable Pod。
BestEffort Pod

第三類 BestEffort Pod,它也是條件比較死的一種使用方式。它必須是所有資源的 request/limit 都不填,才是一種 BestEffort Pod。
所以這里可以看到,通過 request 和 limit 不同的用法,可以組合出不同的 Pod QoS。
接下來,為大家介紹一下:不同的 QoS 在調度和底層表現有什么樣的不同?不同的 QoS,它其實在調度和底層表現上都有一些不一樣。比如說調度表現,調度器只會使用 request 進行調度,也就是說不管你配了多大的 limit,它都不會進行調度使用。
在底層上,不同的 Qos 表現更不相同。比如說 CPU,它是按 request 來劃分權重的,不同的 QoS,它的 request 是完全不一樣的,比如說像 Burstable 和 BestEffort,它可能 request 可以填很小的數字或者不填,這樣的話,它的時間片權重其實是非常低的。像 BestEffort,它的權重可能只有 2,而 Burstable 或 Guaranteed,它的權重可以多到幾千。
另外,當我們開啟了 kubelet 的一個特性,叫 cpu-manager-policy=static 的時候,我們 Guaranteed Qos,如果它的 request 是一個整數的話,比如說配了 2,它會對 Guaranteed Pod 進行綁核。具體的像下面這個例子,它分配 CPU0 和 CPU1 給 Guaranteed Pod。
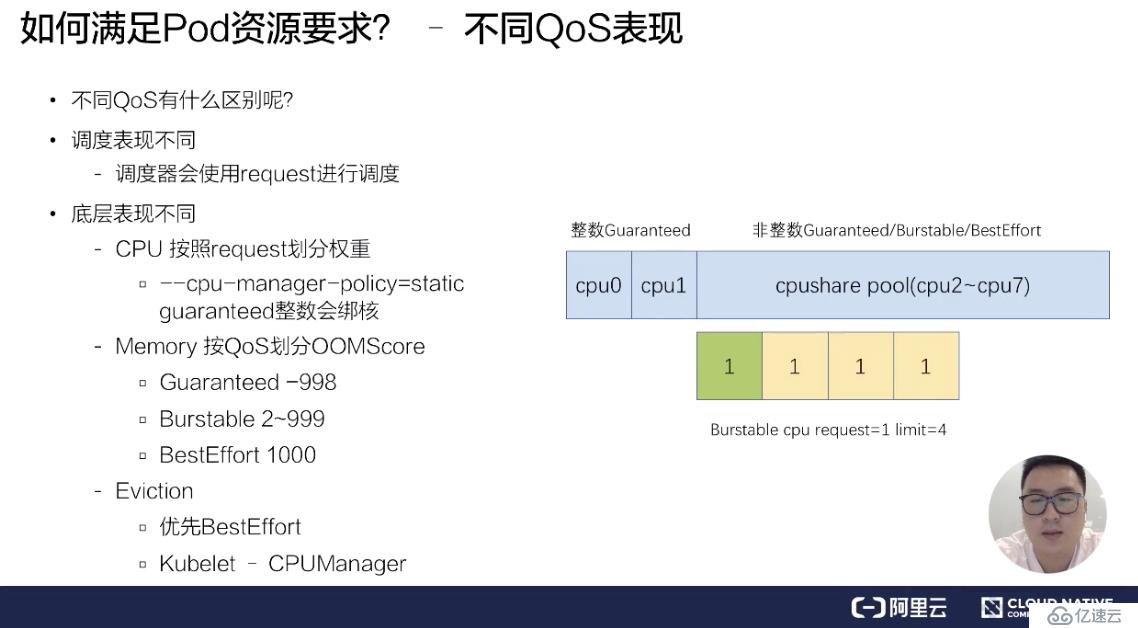
非整數的 Guaranteed/Burstable/BestEffort,它們的 CPU 會放在一塊,組成一個 CPU share pool,比如說像上面這個例子,這臺節點假如說有 8 個核,已經分配了 2 個核給整數的 Guaranteed 綁核,那么剩下的 6 個核 CPU2~CPU7,它會被非整數的 Guaranteed/Burstable/BestEffort 共享,然后它們會根據不同的權重劃分時間片來使用 6 個核的 CPU。
另外在 memory 上也會按照不同的 QoS 進行劃分 OOMScore。比如說 Guaranteed Pod,會固定配置默認的 -998 的 OOMScore;而 Burstable Pod 會根據 Pod 內存設計的大小和節點內存的比例來分配 2-999 的 OOMScore;BestEffort Pod 會固定分配 1000 的 OOMScore,OOMScore 得分越高的話,在物理機出現 OOM 的時候會優先被 kill 掉。
另外在節點上的 eviction 動作上,不同的 QoS 行為也是不一樣的,比如說發生 eviction 的時候,會優先考慮驅逐 BestEffort 的 pod。所以不同的 QoS 在底層的表現是截然不同的。這反過來也要求我們在生產過程中,根據不同業務的要求和屬性來配置資源的 Limits 和 Requests,做到合理的規劃 QoS Class。
在生產中我們還會遇到一個場景:假如集群是由多個人同時提交的,或者是多個業務同時在使用,我們肯定要限制某個業務或某個人提交的總量,防止整個集群的資源都會被一個業務使用掉,導致另一個業務沒有資源使用。

Kubernetes 給我們提供了一個能力叫 ResourceQuota。它可以做到限制 namespace 資源用量。
具體的做法如上圖右側的 yaml 所示,可以看到它的 spec 包括了一個 hard 和 scopeSelector。hard 內容其實和 Resource 很像,這里可以填一些基礎的資源。但是它比 Resource list 更豐富一點,還可以填寫一些 Pod,這樣可以限制 Pod 數量。另外,scopeSelector 還為這個 ResourceQuota 提供了更豐富的索引能力。
比如上面的例子中,索引出非 BestEffort 的 pod,限制的 cpu 是 1000 個,memory 是 200G,Pod 是 10 個。
ScopeName 除了提供 NotBestEffort,它還提供了更豐富的索引范圍,包括 Terminating/Not Terminating,BestEffort/NotBestEffort,PriorityClass。
當我們創建了這樣的 ResourceQuota 作用于集群,如果用戶真的用超了資源,表現的行為是:它在提交 Pod spec 時,會收到一個 forbidden 的 403 錯誤,提示 exceeded quota。這樣用戶就無法再提交對應用超的資源了。
而如果再提交一個沒有包含在這個 ResourceQuota 里的資源,還是能成功的。
這就是 Kubernetes 里 ResourceQuota 的基本用法。 我們可以用 ResourceQuota 方法來做到限制每一個 namespace 的資源用量,從而保證其他用戶的資源使用。
上面介紹完了基礎資源的使用方式,也就是我們做到了如何滿足 Pod 資源要求。下面做一個小結:
Pod 要配置合理的資源要求
CPU/Memory/EphemeralStorage/GPU
通過 Request 和 Limit 來為不同業務特點的 Pod 選擇不同的 QoS
Guaranteed:敏感型,需要業務保障
Burstable:次敏感型,需要彈性業務
BestEffort:可容忍性業務
為每個 NS 配置 ResourceQuota 來防止過量使用,保障其他人的資源可用
接下來給大家介紹一下 Pod 的關系調度,首先是 Pod 和 Pod 的關系調度。我們在平時使用中可能會遇到一些場景:比如說一個 Pod 必須要和另外一個 Pod 放在一起,或者不能和另外一個 Pod 放在一起。
在這種要求下, Kubernetes 提供了兩類能力:
第一類能力稱之為 Pod 親和調度:PodAffinity;
第二類就是 Pod 反親和調度:PodAntAffinity。

首先我們來看 Pod 親和調度,假如我想把一個 Pod 和另一個 Pod 放在一起,這時我們可以看上圖中的實例寫法,填寫上 podAffinity,然后填上 required 要求。
在這個例子中,必須要調度到帶了 key: k1 的 Pod 所在的節點,并且打散粒度是按照節點粒度去打散索引的。這種情況下,假如能找到帶 key: k1 的 Pod 所在節點,就會調度成功。假如這個集群不存在這樣的 Pod 節點,或者是資源不夠的時候,那就會調度失敗。這是一個嚴格的親和調度,我們叫做強制親和調度。

有些時候我們并不需要這么嚴格的調度策略。這時候可以把 required 改成 preferred,變成一個優先親和調度。也就是優先可以調度帶 key: k2 的 Pod 所在節點。并且這個 preferred 里面可以是一個 list 選擇,可以填上多個條件,比如權重等于 100 的是 key: k2,權重等于 10 的是 key: k1。那調度器在調度的時候會優先把這個 Pod 分配到權重分更高的調度條件節點上去。
上面介紹了親和調度,反親和調度與親和調度比較相似,功能上是取反的,但語法上基本上是一樣的。僅是 podAffinity 換成了 podAntiAffinity,也是包括 required 強制反親和,以及一個 preferred 優先反親和。
這里舉了兩個例子:一個是禁止調度到帶了 key: k1 標簽的 Pod 所在節點;另一個是優先反親和調度到帶了 key: k2 標簽的 Pod 所在節點。

Kubernetes 除了 In 這個 Operator 語法之外,還提供了更多豐富的語法組合來給大家使用。比如說 In/NotIn/Exists/DoesNotExist 這些組合方式。上圖的例子用的是 In,比如說第一個強制反親和例子里面,相當于我們必須要禁止調度到帶了 key: k1 標簽的 Pod 所在節點。
同樣的功能也可以使用 Exists,Exists 范圍可能會比 In 范圍更大,當 Operator 填了 Exists,就不需要再填寫 values。它做到的效果就是禁止調度到帶了 key: k1 標簽的 Pod 所在節點,不管 values 是什么值,只要帶了 k1 這個 key 標簽的 Pod 所在節點,都不能調度過去。
以上就是 Pod 與 Pod 之間的關系調度。
Pod 與 Node 的關系調度又稱之為 Node 親和調度,主要給大家介紹兩類使用方法。

第一類是 NodeSelector,這是一類相對比較簡單的用法。比如說有個場景:必須要調度 Pod 到帶了 k1: v1 標簽的 Node 上,這時可以在 Pod 的 spec 中填寫一個 nodeSelector 要求。nodeSelector 本質是一個 map 結構,里面可以直接寫上對 node 標簽的要求,比如 k1: v1。這樣我的 Pod 就會強制調度到帶了 k1: v1 標簽的 Node 上。
NodeSelector 是一個非常簡單的用法,但這個用法有個問題:它只能強制親和調度,假如我想優先調度,就沒法用 nodeSelector 來做。于是 Kubernetes 社區又新加了一個用法,叫做 NodeAffinity。

它和 PodAffinity 有點類似,也提供了兩類調度的策略:
第一類是 required,必須調度到某一類 Node 上;
第二類是 preferred,就是優先調度到某一類 Node 上。
它的基本語法和上文中的 PodAffinity 以及 PodAntiAffinity 也是類似的。在 Operator 上,NodeAffinity 提供了比 PodAffinity 更豐富的 Operator 內容。增加了 Gt 和 Lt,數值比較的用法。當使用 Gt 的時候,values 只能填寫數字。
還有第三類調度,可以通過給 Node 打一些標記,來限制 Pod 調度到某些 Node 上。Kubernetes 把這些標記稱之為 Taints,它的字面意思是污染。

那我們如何限制 Pod 調度到某些 Node 上呢?比如說現在有個 node 叫 demo-node,這個節點有問題,我想限制一些 Pod 調度上來。這時可以給這個節點打一個 taints,taints 內容包括 key、value、effect:
key 就是配置的鍵值
value 就是內容
effect 是標記了這個 taints 行為是什么
目前 Kubernetes 里面有三個 taints 行為:
NoSchedule 禁止新的 Pod 調度上來;
PreferNoSchedul 盡量不調度到這臺;
NoExecute 會 evict 沒有對應 toleration 的 Pods,并且也不會調度新的上來。這個策略是非常嚴格的,大家在使用的時候要小心一點。
如上圖綠色部分,給這個 demo-node 打了 k1=v1,并且 effect 等于 NoSchedule 之后。它的效果是:新建的 Pod 沒有專門容忍這個 taint,那就沒法調度到這個節點上去了。
假如有些 Pod 是可以調度到這個節點上的,應該怎么來做呢?這時可以在 Pod 上打一個 Pod Tolerations。從上圖中藍色部分可以看到:在 Pod 的 spec 中填寫一個 Tolerations,它里面也包含了 key、value、effect,這三個值和 taint 的值是完全對應的,taint 里面的 key,value,effect 是什么內容,Tolerations 里面也要填寫相同的內容。
Tolerations 還多了一個選項 Operator,Operator 有兩個 value:Exists/Equal。Equal 的概念是必須要填寫 value,而 Exists 就跟上文說的 NodeAffinity 一樣,不需要填寫 value,只要 key 值對上了,就認為它跟 taints 是匹配的。
上圖中的例子,給 Pod 打了一個 Tolerations,只有打了這個 Tolerations 的 Pod,才能調度到綠色部分打了 taints 的 Node 上去。這樣的好處是 Node 可以有選擇性的調度一些 Pod 上來,而不是所有的 Pod 都可以調度上來,這樣就做到了限制某些 Pod 調度到某些 Node 的效果。
我們已經介紹完了 Pod/Node 的特殊關系和條件調度,來做一下小結。
首先假如有需求是處理 Pod 與 Pod 的時候,比如 Pod 和另一個 Pod 有親和的關系或者是互斥的關系,可以給它們配置下面的參數:
PodAffinity
PodAntiAffinity
假如存在 Pod 和 Node 有親和關系,可以配置下面的參數:
NodeSelector
NodeAffinity
假如有些 Node 是限制某些 Pod 調度的,比如說一些故障的 Node,或者說是一些特殊業務的 Node,可以配置下面的參數:
Node -- Taints
Pod -- Tolerations
介紹完了基礎調度能力之后,下面來了解一下高級調度能力。
優先級調度和搶占,主要概念有:
Priority
Preemption
首先來看一下調度過程提到的四個特點,我們如何做到集群的合理利用?當集群資源足夠的話,只需要通過基礎調度能力就能組合出合理的使用方式。但是假如資源不夠,我們怎么做到集群的合理利用呢?通常的策略有兩類:
先到先得策略 (FIFO) -簡單、相對公平,上手快
優先級策略 (Priority) - 比較符合日常公司業務特點
在實際生產中,如果使用先到先得策略,反而是一種不公平的策略,因為公司業務里面肯定是有高優先級的業務和低優先級的業務,所以優先級策略會比先到先得策略更能夠符合日常公司業務特點。
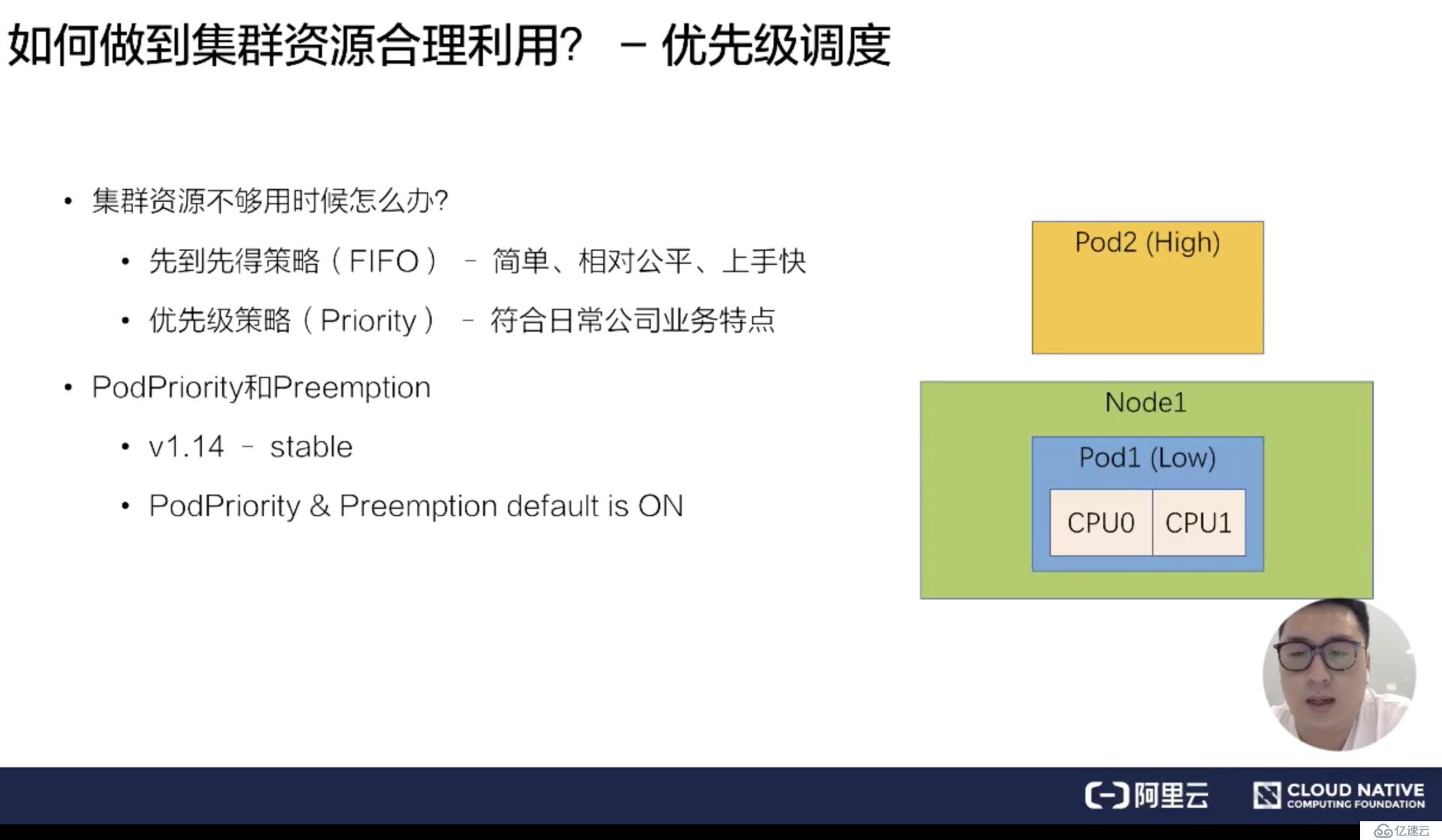
接下來介紹一下優先級策略下的優先級調度是什么樣的一個概念。比如說有一個 Node 已經被一個 Pod 占用了,這個 Node 只有 2 個 CPU。另一個高優先級 Pod 來的時候,低優先級的 Pod 應該把這兩個 CPU 讓給高優先級的 Pod 去使用。低優先級的 Pod 需要回到等待隊列,或者是業務重新提交。這樣的流程就是優先級搶占調度的一個流程。
在 Kubernetes 里,PodPriority 和 Preemption,就是優先級和搶占的特點,在 v1.14 版本中變成了 stable。并且 PodPriority 和 Preemption 功能默認是開啟的。
如何使用優先級調度呢?需要創建一個 priorityClass,然后再為每個 Pod 配置上不同的 priorityClassName,這樣就完成了優先級以及優先級調度的配置。

首先來看一下如何創建一個 priorityClass。上圖右側定義了兩個 demo:
一個是創建了名為 high 的 priorityClass,它是高優先級,得分為 10000;
另一個創建了名為 low 的 priorityClass,它的得分是 100。
同時在第三部分給 Pod1 配置上了 high,Pod2 上配置了 low priorityClassName,藍色部分顯示了 pod 的 spec 的配置位置,就是在 spec 里面填寫一個 priorityClassName: high。這樣 Pod 和 priorityClass 做完配置,就為集群開啟了一個 priorityClass 調度。
當然 Kubernetes 里面還內置了默認的優先級。如 DefaultpriorityWhenNoDefaultClassExistis,如果集群中沒有配置 DefaultpriorityWhenNoDefaultClassExistis,那所有的 Pod 關于此項數值都會被設置成 0。
用戶可配置的最大優先級限制為:HighestUserDefinablePriority = 10000000000(10 億),會小于系統級別優先級:SystemCriticalPriority = 20000000000(20 億)
其中內置了兩個系統級別優先級:
system-cluster-critical
system-node-critical
這就是K8S優先級調度里內置的優先級配置。
下面介紹簡單的優先級調度過程:
首先介紹只觸發優先級調度但是沒有觸發搶占調度的流程。
假如有一個 Pod1 和 Pod2,Pod1 配置了高優先級,Pod2 配置了低優先級。同時提交 Pod1 和 Pod2 到調度隊列里。
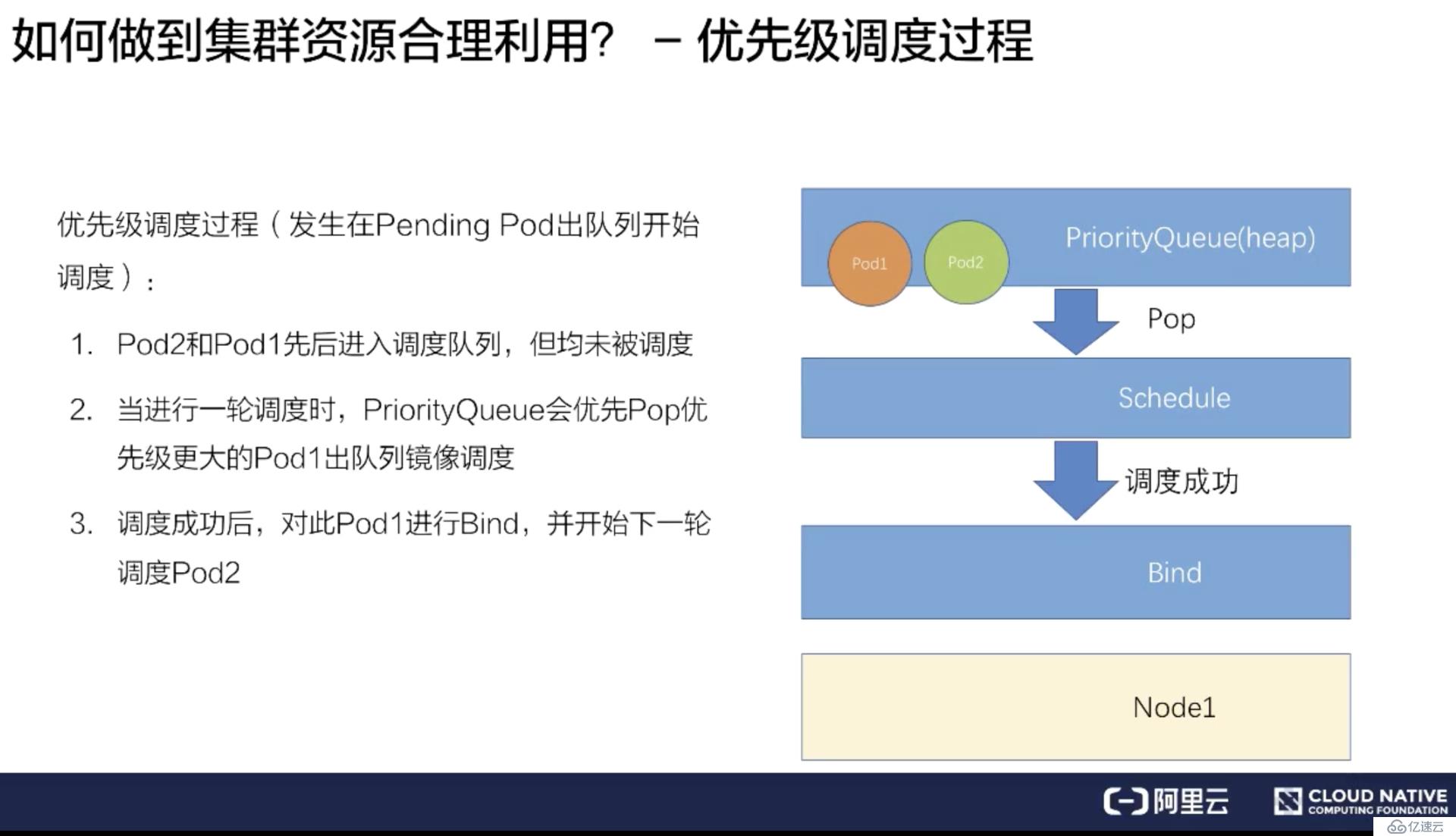
調度器處理隊列的時候會挑選一個高優先級的 Pod1 進行調度,經過調度過程把 Pod1 綁定到 Node1 上。
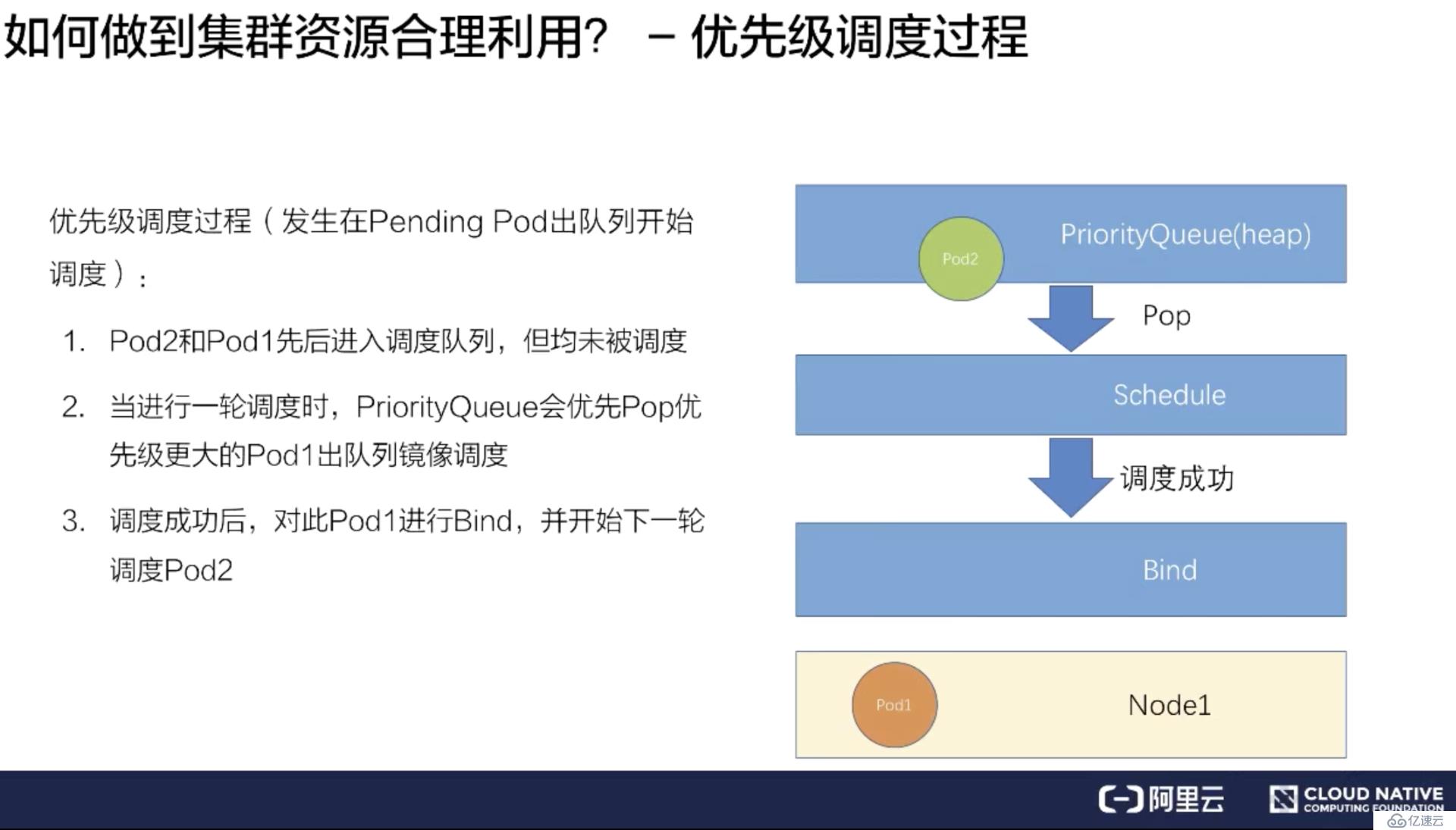
其次再挑選一個低優先的 Pod2 進行同樣的過程,綁定到 Node1 上。
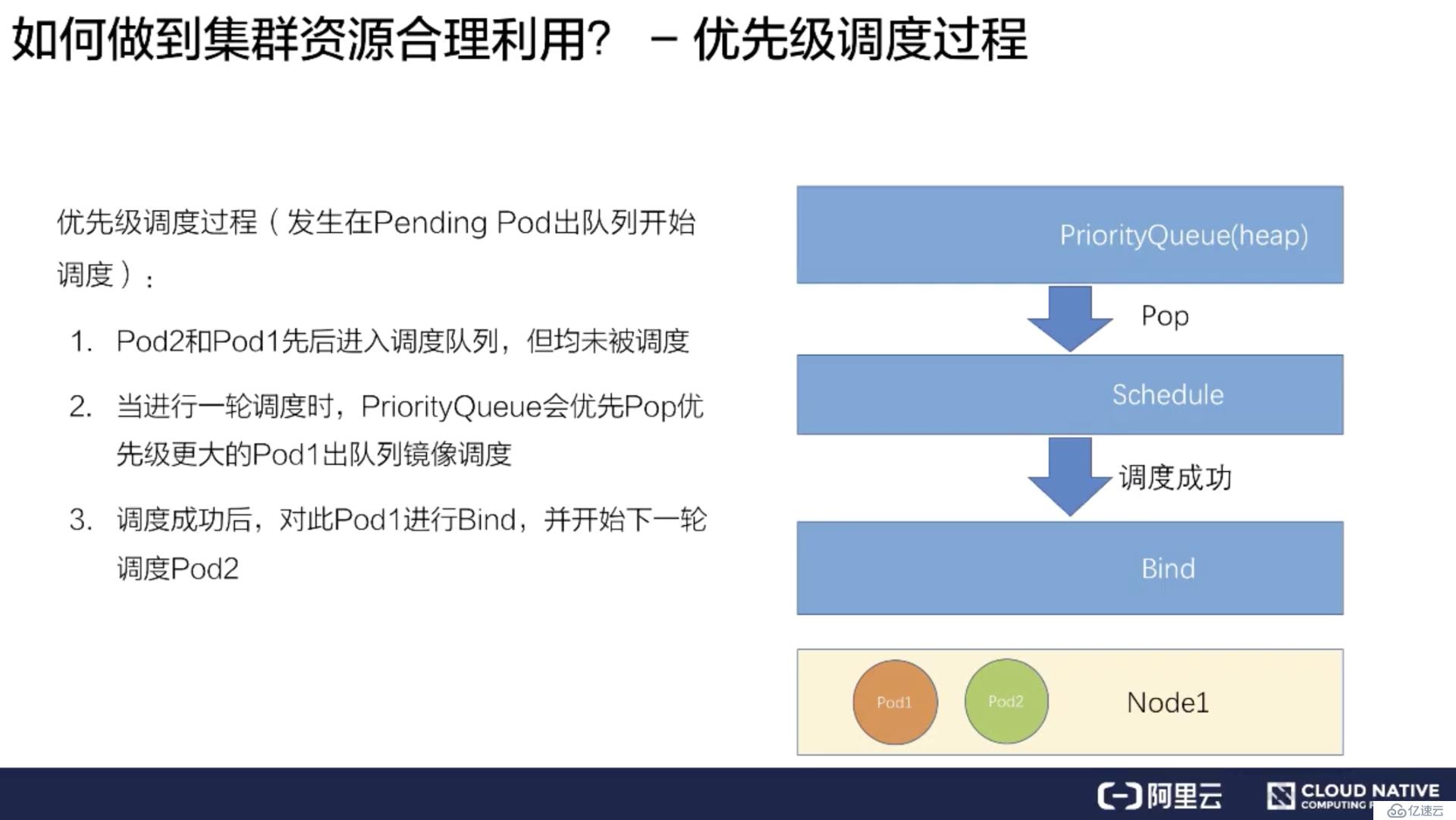
這樣就完成了一個簡單的優先級調度的流程。
假如高優先級的 Pod 在調度的時候沒有資源,那么會是一個怎么樣的流程呢?
首先是跟上文同樣的場景,但是提前在 Node1 上放置了 Pod0,占去了一部分資源。同樣有 Pod1 和 Pod2 待調度,Pod1 的優先級大于 Pod2。
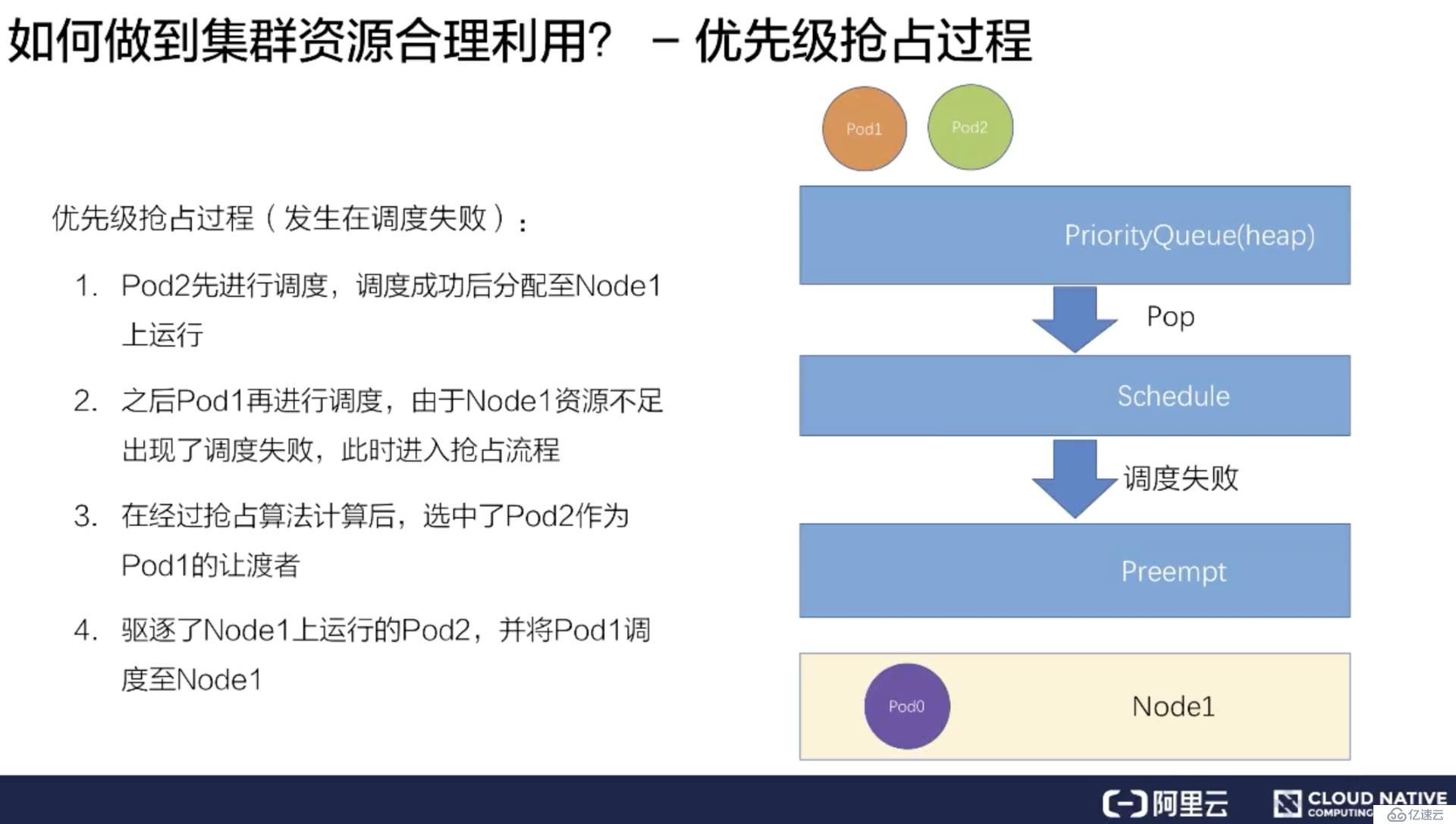
假如先把 Pod2 調度上去,它經過一系列的調度過程綁定到了 Node1 上。
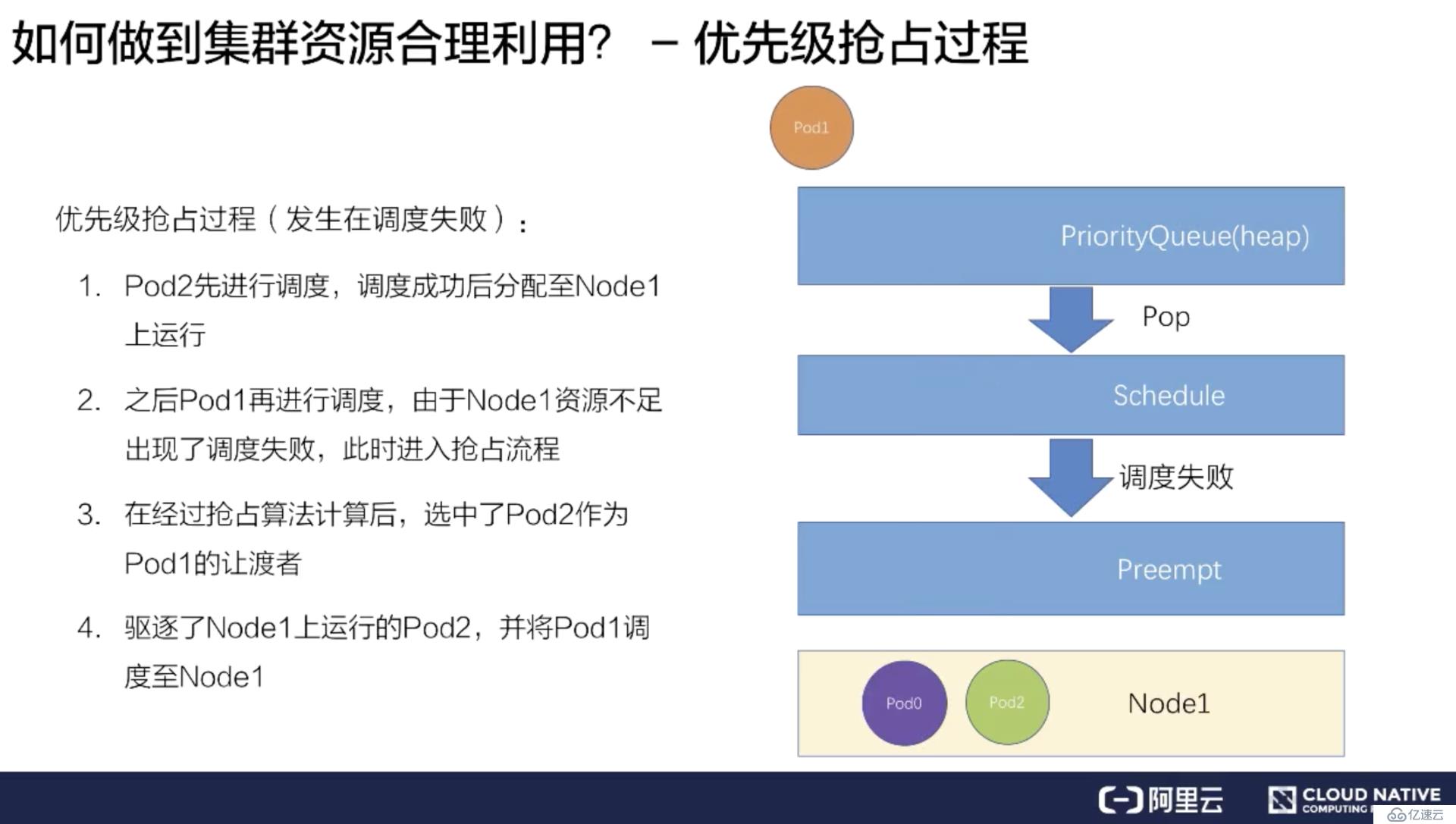
緊接著再調度 Pod1,因為 Node1 上已經存在了兩個 Pod,資源不足,所以會遇到調度失敗。
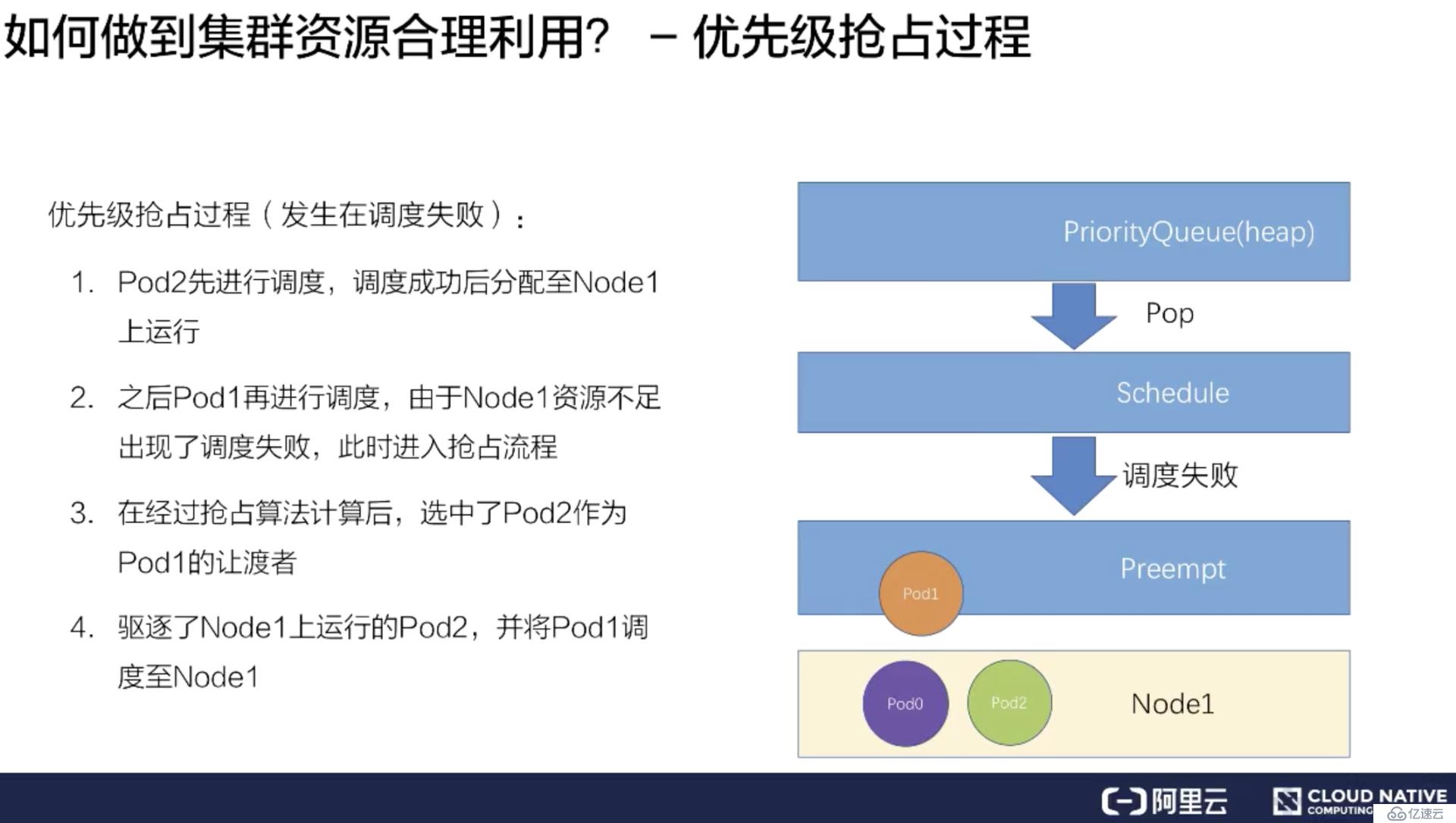
在調度失敗時 Pod1 會進入搶占流程,這時會進行整個集群的節點篩選,最后挑出要搶占的 Pod 是 Pod2,此時調度器會把 Pod2 從 Node1 上移除數據。
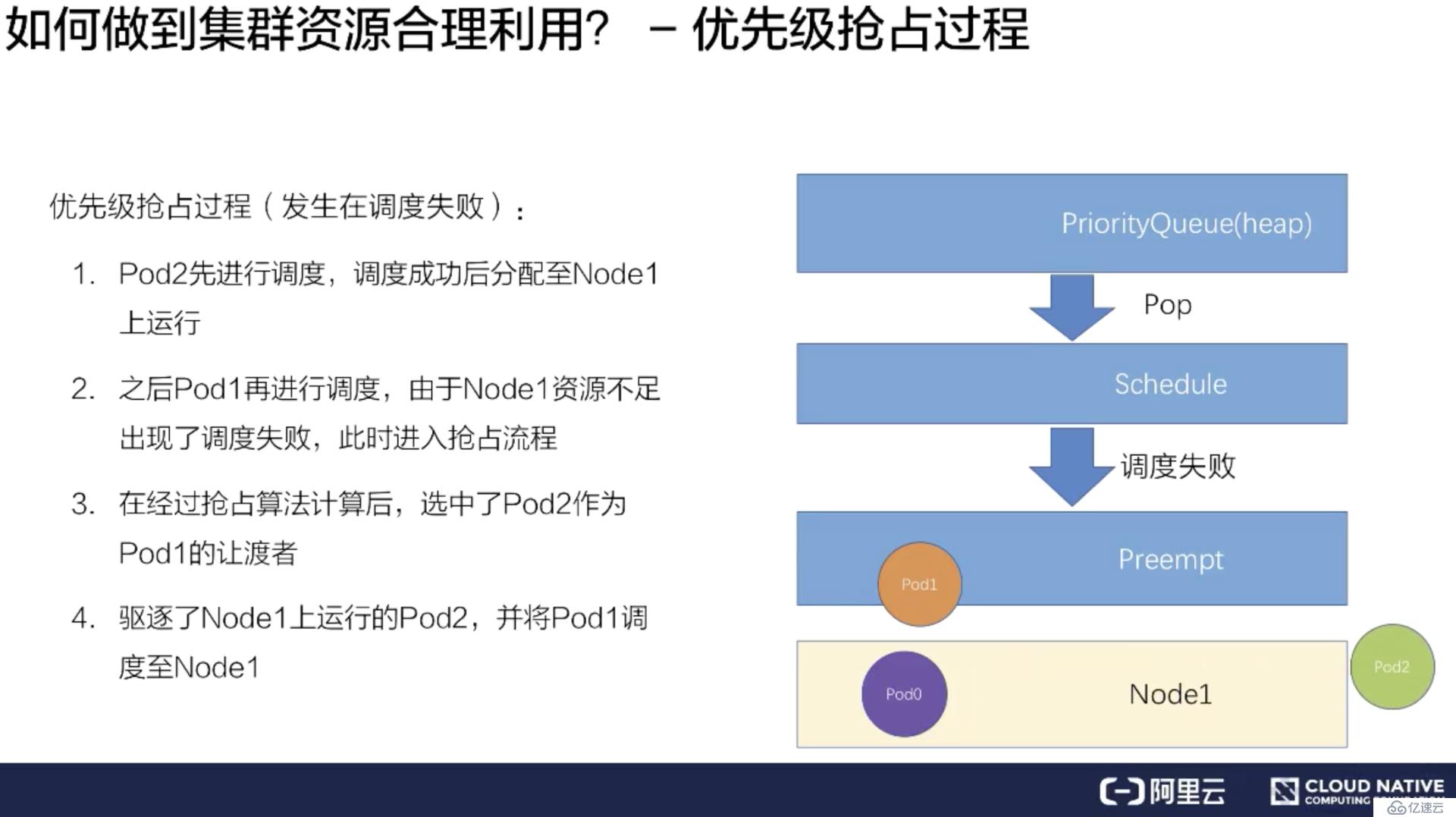
再把 Pod1 調度到 Node1 上。這樣就完成了一次搶占調度的流程。
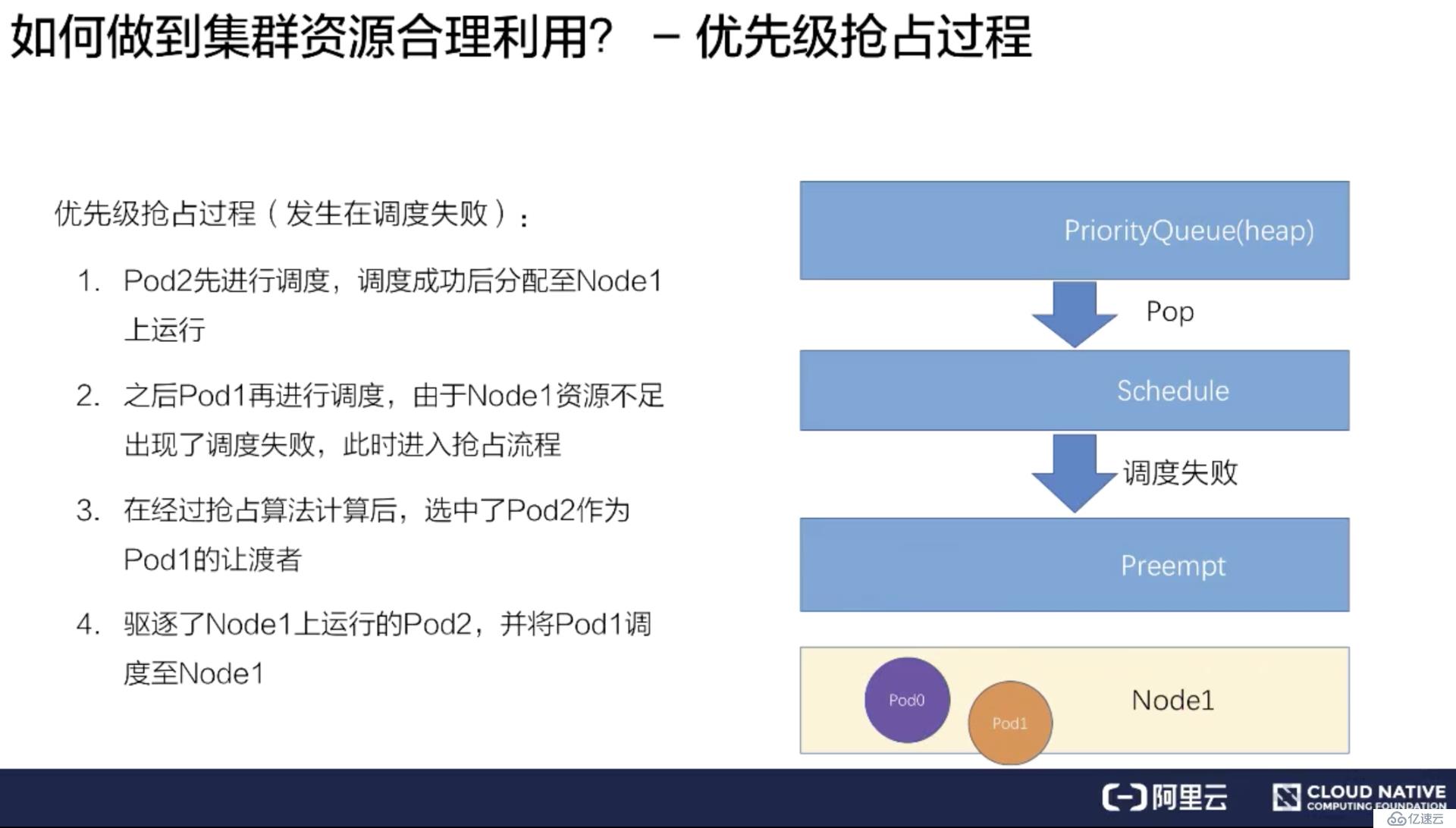
接下來介紹具體的搶占策略和搶占流程
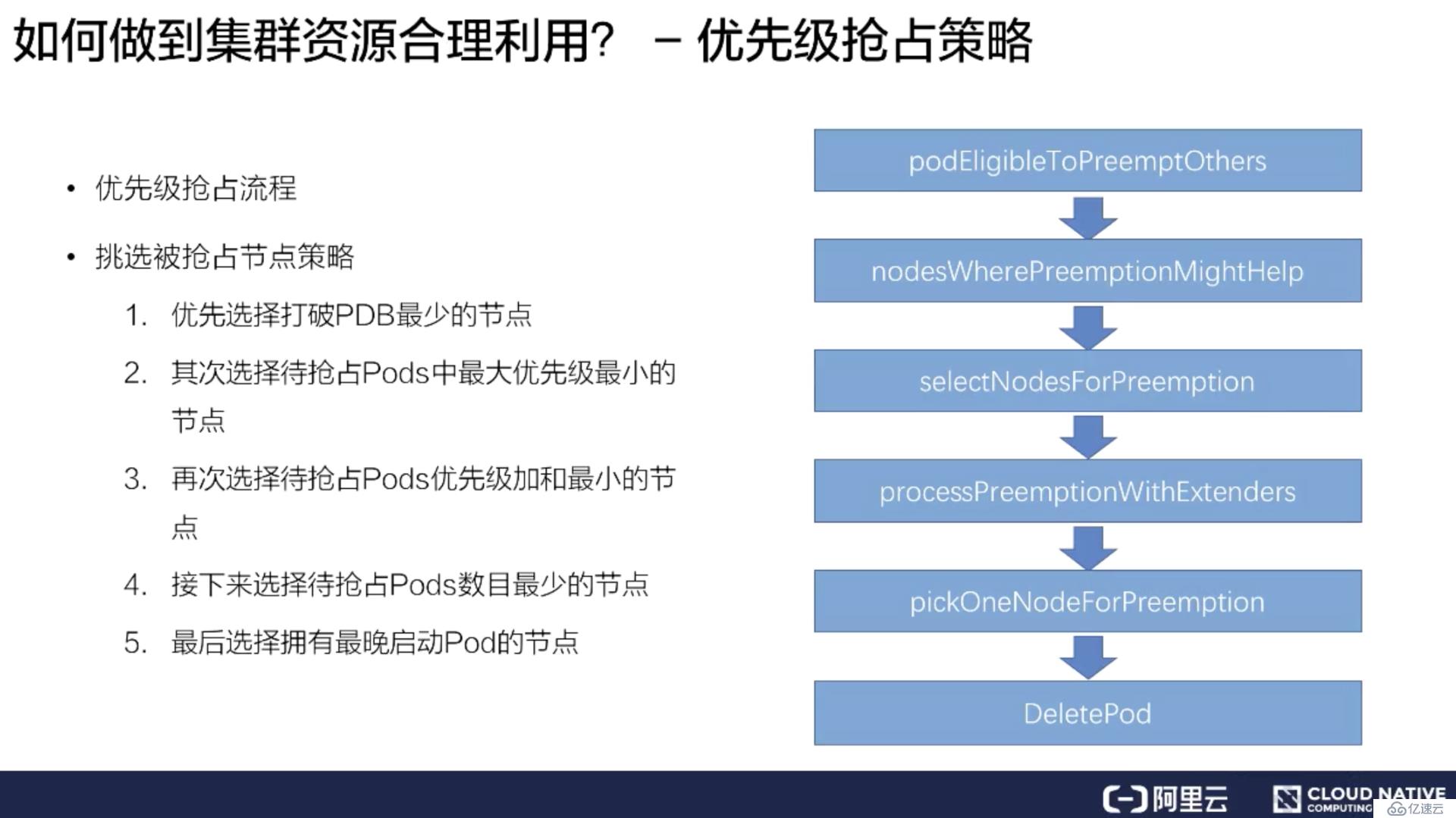
上圖右側是整個kube-scheduler優先級搶占的調度流程。首先一個 Pod 進入搶占的時候,會判斷 Pod 是否擁有搶占的資格,有可能上次已經搶占過一次。如果符合搶占資格,它會先對所有的節點進行一次過濾,過濾出符合這次搶占要求的節點,如果不符合就過濾掉這批節點。
接著從過濾剩下的節點中,挑選出合適的節點進行搶占。這次搶占的過程會模擬一次調度,把上面優先級低的 Pod 先移除出去,再把待搶占的 Pod 嘗試能否放置到此節點上。然后通過這個過程選出一批節點,進入下一個過程 ProcessPreemptionWithExtenders。這是一個擴展的鉤子,用戶可以在這里加一些自己搶占節點的策略,如果沒有擴展鉤子,這里面是不做任何動作的。
接下來的流程叫做 PickOneNodeForPreemption,就是從上面 selectNodeForPreemption list 里面挑選出最合適的一個節點,這是有一定的策略的。上圖左側簡單介紹了一下策略:
優先選擇打破 PDB 最少的節點;
其次選擇待搶占 Pods 中最大優先級最小的節點;
再次選擇待搶占 Pods 優先級加和最小的節點;
接下來選擇待搶占 Pods 數目最小的節點;
最后選擇擁有最晚啟動 Pod 的節點;
通過這五步串行策略過濾之后,會選出一個最合適的節點。然后對這個節點上待搶占的 Pod 進行 delete,這樣就完成了一次待搶占的過程。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





