溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Kubernetes Resource QoS機制是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Kubernetes Resource QoS機制是什么”吧!
Kubernetes根據Pod中Containers Resource的request和limit的值來定義Pod的QoS Class。
對于每一種Resource都可以將容器分為3中QoS Classes: Guaranteed, Burstable, and Best-Effort,它們的QoS級別依次遞減。
Guaranteed 如果Pod中所有Container的所有Resource的limit和request都相等且不為0,則這個Pod的QoS Class就是Guaranteed。
注意,如果一個容器只指明了limit,而未指明request,則表明request的值等于limit的值。
Examples:
containers: name: foo resources: limits: cpu: 10m memory: 1Gi name: bar resources: limits: cpu: 100m memory: 100Mi
containers: name: foo resources: limits: cpu: 10m memory: 1Gi requests: cpu: 10m memory: 1Gi name: bar resources: limits: cpu: 100m memory: 100Mi requests: cpu: 100m memory: 100Mi
Best-Effort 如果Pod中所有容器的所有Resource的request和limit都沒有賦值,則這個Pod的QoS Class就是Best-Effort.
Examples:
containers: name: foo resources: name: bar resources:
Burstable 除了符合Guaranteed和Best-Effort的場景,其他場景的Pod QoS Class都屬于Burstable。
當limit值未指定時,其有效值其實是對應Node Resource的Capacity。
Examples:
容器bar沒有對Resource進行指定。
containers: name: foo resources: limits: cpu: 10m memory: 1Gi requests: cpu: 10m memory: 1Gi name: bar
容器foo和bar對不同的Resource進行了指定。
containers: name: foo resources: limits: memory: 1Gi name: bar resources: limits: cpu: 100m
容器foo未指定limit,容器bar未指定request和limit。
containers: name: foo resources: requests: cpu: 10m memory: 1Gi name: bar
kube-scheduler調度時,是基于Pod的request值進行Node Select完成調度的。Pod和它的所有Container都不允許Consume limit指定的有效值(if have)。
How the request and limit are enforced depends on whether the resource is compressible or incompressible.
For now, we are only supporting CPU.
Pods are guaranteed to get the amount of CPU they request, they may or may not get additional CPU time (depending on the other jobs running). This isn't fully guaranteed today because cpu isolation is at the container level. Pod level cgroups will be introduced soon to achieve this goal.
Excess CPU resources will be distributed based on the amount of CPU requested. For example, suppose container A requests for 600 milli CPUs, and container B requests for 300 milli CPUs. Suppose that both containers are trying to use as much CPU as they can. Then the extra 10 milli CPUs will be distributed to A and B in a 2:1 ratio (implementation discussed in later sections).
Pods will be throttled if they exceed their limit. If limit is unspecified, then the pods can use excess CPU when available.
For now, we are only supporting memory.
Pods will get the amount of memory they request, if they exceed their memory request, they could be killed (if some other pod needs memory), but if pods consume less memory than requested, they will not be killed (except in cases where system tasks or daemons need more memory).
When Pods use more memory than their limit, a process that is using the most amount of memory, inside one of the pod's containers, will be killed by the kernel.
Pods will be admitted by Kubelet & scheduled by the scheduler based on the sum of requests of its containers. The scheduler & kubelet will ensure that sum of requests of all containers is within the node's allocatable capacity (for both memory and CPU).
CPU Pods will not be killed if CPU guarantees cannot be met (for example if system tasks or daemons take up lots of CPU), they will be temporarily throttled.
Memory Memory is an incompressible resource and so let's discuss the semantics of memory management a bit.
Best-Effort pods will be treated as lowest priority. Processes in these pods are the first to get killed if the system runs out of memory. These containers can use any amount of free memory in the node though.
Guaranteed pods are considered top-priority and are guaranteed to not be killed until they exceed their limits, or if the system is under memory pressure and there are no lower priority containers that can be evicted.
Burstable pods have some form of minimal resource guarantee, but can use more resources when available. Under system memory pressure, these containers are more likely to be killed once they exceed their requests and no Best-Effort pods exist.
Pod OOM score configuration
Note that the OOM score of a process is 10 times the % of memory the process consumes, adjusted by OOM_SCORE_ADJ, barring exceptions (e.g. process is launched by root). Processes with higher OOM scores are killed.
The base OOM score is between 0 and 1000, so if process A’s OOM_SCORE_ADJ - process B’s OOM_SCORE_ADJ is over a 1000, then process A will always be OOM killed before B.
The final OOM score of a process is also between 0 and 1000
Best-effort
Set OOM_SCORE_ADJ: 1000
So processes in best-effort containers will have an OOM_SCORE of 1000
Guaranteed
Set OOM_SCORE_ADJ: -998
So processes in guaranteed containers will have an OOM_SCORE of 0 or 1
Burstable
If total memory request > 99.8% of available memory, OOM_SCORE_ADJ: 2
Otherwise, set OOM_SCORE_ADJ to 1000 - 10 * (% of memory requested)
This ensures that the OOM_SCORE of burstable pod is > 1
If memory request is 0, OOM_SCORE_ADJ is set to 999.
So burstable pods will be killed if they conflict with guaranteed pods
If a burstable pod uses less memory than requested, its OOM_SCORE < 1000
So best-effort pods will be killed if they conflict with burstable pods using less than requested memory
If a process in burstable pod's container uses more memory than what the container had requested, its OOM_SCORE will be 1000, if not its OOM_SCORE will be < 1000
Assuming that a container typically has a single big process, if a burstable pod's container that uses more memory than requested conflicts with another burstable pod's container using less memory than requested, the former will be killed
If burstable pod's containers with multiple processes conflict, then the formula for OOM scores is a heuristic, it will not ensure "Request and Limit" guarantees.
Pod infra containers or Special Pod init process
OOM_SCORE_ADJ: -998
Kubelet, Docker
OOM_SCORE_ADJ: -999 (won’t be OOM killed)
Hack, because these critical tasks might die if they conflict with guaranteed containers. In the future, we should place all user-pods into a separate cgroup, and set a limit on the memory they can consume.
QoS的源碼位于:pkg/kubelet/qos,代碼非常簡單,主要就兩個文件pkg/kubelet/qos/policy.go,pkg/kubelet/qos/qos.go。
上面討論的各個QoS Class對應的OOM_SCORE_ADJ定義在:
pkg/kubelet/qos/policy.go:21 const ( PodInfraOOMAdj int = -998 KubeletOOMScoreAdj int = -999 DockerOOMScoreAdj int = -999 KubeProxyOOMScoreAdj int = -999 guaranteedOOMScoreAdj int = -998 besteffortOOMScoreAdj int = 1000 )
容器的OOM_SCORE_ADJ的計算方法定義在:
pkg/kubelet/qos/policy.go:40
func GetContainerOOMScoreAdjust(pod *v1.Pod, container *v1.Container, memoryCapacity int64) int {
switch GetPodQOS(pod) {
case Guaranteed:
// Guaranteed containers should be the last to get killed.
return guaranteedOOMScoreAdj
case BestEffort:
return besteffortOOMScoreAdj
}
// Burstable containers are a middle tier, between Guaranteed and Best-Effort. Ideally,
// we want to protect Burstable containers that consume less memory than requested.
// The formula below is a heuristic. A container requesting for 10% of a system's
// memory will have an OOM score adjust of 900. If a process in container Y
// uses over 10% of memory, its OOM score will be 1000. The idea is that containers
// which use more than their request will have an OOM score of 1000 and will be prime
// targets for OOM kills.
// Note that this is a heuristic, it won't work if a container has many small processes.
memoryRequest := container.Resources.Requests.Memory().Value()
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
// A guaranteed pod using 100% of memory can have an OOM score of 10. Ensure
// that burstable pods have a higher OOM score adjustment.
if int(oomScoreAdjust) < (1000 + guaranteedOOMScoreAdj) {
return (1000 + guaranteedOOMScoreAdj)
}
// Give burstable pods a higher chance of survival over besteffort pods.
if int(oomScoreAdjust) == besteffortOOMScoreAdj {
return int(oomScoreAdjust - 1)
}
return int(oomScoreAdjust)
}獲取Pod的QoS Class的方法為:
pkg/kubelet/qos/qos.go:50
// GetPodQOS returns the QoS class of a pod.
// A pod is besteffort if none of its containers have specified any requests or limits.
// A pod is guaranteed only when requests and limits are specified for all the containers and they are equal.
// A pod is burstable if limits and requests do not match across all containers.
func GetPodQOS(pod *v1.Pod) QOSClass {
requests := v1.ResourceList{}
limits := v1.ResourceList{}
zeroQuantity := resource.MustParse("0")
isGuaranteed := true
for _, container := range pod.Spec.Containers {
// process requests
for name, quantity := range container.Resources.Requests {
if !supportedQoSComputeResources.Has(string(name)) {
continue
}
if quantity.Cmp(zeroQuantity) == 1 {
delta := quantity.Copy()
if _, exists := requests[name]; !exists {
requests[name] = *delta
} else {
delta.Add(requests[name])
requests[name] = *delta
}
}
}
// process limits
qosLimitsFound := sets.NewString()
for name, quantity := range container.Resources.Limits {
if !supportedQoSComputeResources.Has(string(name)) {
continue
}
if quantity.Cmp(zeroQuantity) == 1 {
qosLimitsFound.Insert(string(name))
delta := quantity.Copy()
if _, exists := limits[name]; !exists {
limits[name] = *delta
} else {
delta.Add(limits[name])
limits[name] = *delta
}
}
}
if len(qosLimitsFound) != len(supportedQoSComputeResources) {
isGuaranteed = false
}
}
if len(requests) == 0 && len(limits) == 0 {
return BestEffort
}
// Check is requests match limits for all resources.
if isGuaranteed {
for name, req := range requests {
if lim, exists := limits[name]; !exists || lim.Cmp(req) != 0 {
isGuaranteed = false
break
}
}
}
if isGuaranteed &&
len(requests) == len(limits) {
return Guaranteed
}
return Burstable
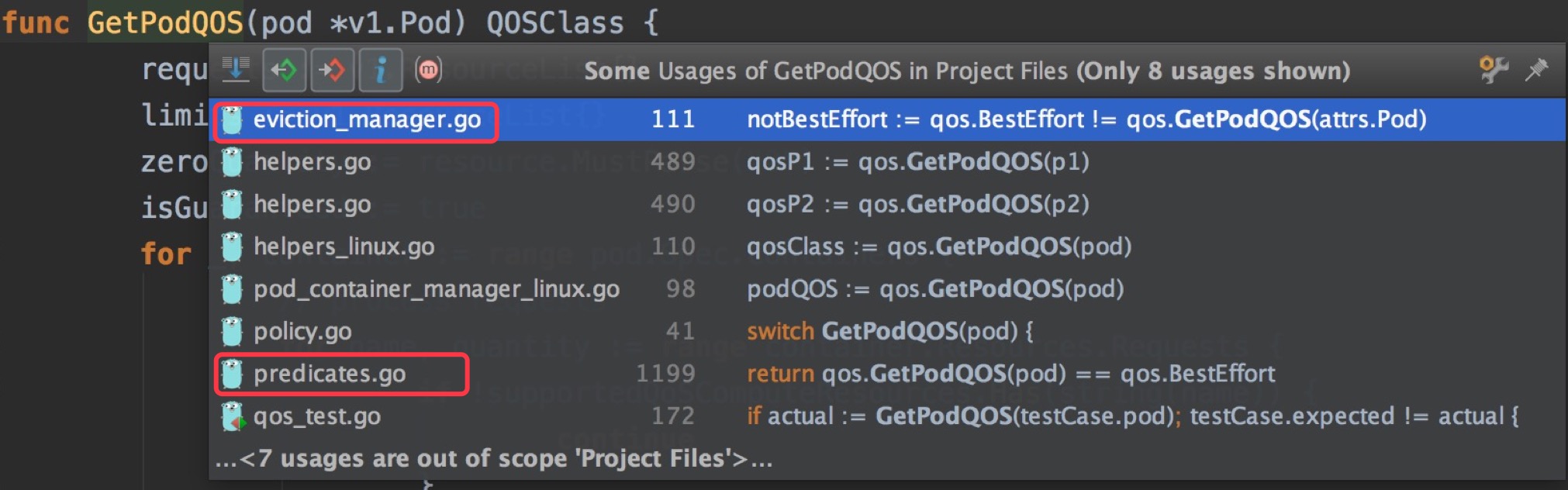
}PodQoS會在eviction_manager和scheduler的Predicates階段被調用,也就說會在k8s處理超配和調度預選階段中被使用。
到此,相信大家對“Kubernetes Resource QoS機制是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





