溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Go單隊列到優先級隊列如何實現的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
隊列,是數據結構中實現先進先出策略的一種數據結構。而優先隊列則是帶有優先級的隊列,即先按優先級分類,然后相同優先級的再 進行排隊。優先級高的隊列中的元素會優先被消費。如下圖所示:
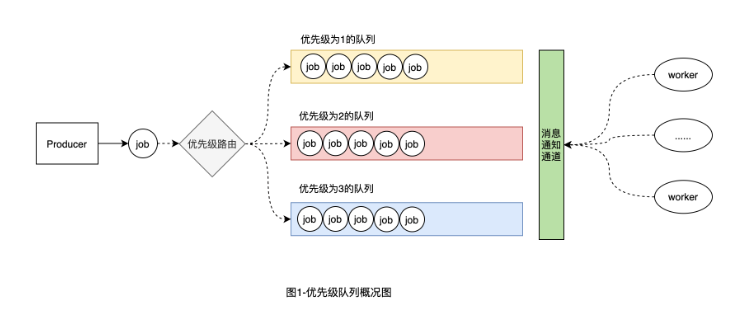
在Go中,可以定義一個切片,切片的每個元素代表一種優先級隊列,切片的索引順序代表優先級順序,后面代碼實現部分我們會詳細講解。
先來看現實生活中的例子。銀行的辦事窗口,有普通窗口和vip窗口,vip窗口因為排隊人數少,等待的時間就短,比普通窗口就會優先處理。同樣,在登機口,就有貴賓通道和普通,同樣貴賓通道優先登機。
在互聯網中,當然就是請求和響應。使用優先級隊列的作用是將請求按特定的屬性劃分出優先級,然后按優先級的高低進行優先處理。在研發服務的時候這里有個隱含的約束條件就是服務器資源(CPU、內存、帶寬等)是有限的。如果服務器資源是無限的,那么也就不需要隊列進行排隊了,來一個請求就立即處理一個請求就好了。所以,為了在最大限度的利用服務器資源的前提下,將更重要的任務(優先級高的請求)優先處理,以更好的服務用戶。
對于請求優先級的劃分可以根據業務的特點根據價值高的優先原則來進行劃分即可。例如可以根據是否是否是會員、是否是VIP會員等屬性進行劃分優先級。也可以根據是否是付費用戶進行劃分。在博客的業務中,也可以根據是否是大V的屬性進行優先級劃分。在互聯網廣告業務中,可以根據廣告位資源價值高低來劃分優先級。
在完整的優先級隊列中有四個角色,分別是優先級隊列、工作單元、消費者worker、通知channel。
工作單元Job:隊列里的元素。我們把每一次業務處理都封裝成一個工作單元,該工作單元會進入對應的優先級隊列進行排隊,然后等待消費者worker來消費執行。優先級隊列:按優先級劃分的隊列,用來暫存對應優先級的工作單元Job,相同優先級的工作單元會在同一個隊列里。noticeChan通道:當有工作單元進入優先級隊列排隊后,會在通道里發送一個消息,以通知消費者worker從隊列中獲取元素(工作單元)進行消費。消費者worker:監聽noticeChan,當監聽到noticeChan有消息時,說明隊列中有工作單元需要被處理,優先從高優先級隊列中獲取元素進行消費。
根據隊列個數和消費者個數,我們可以將隊列-消費者模式分為單隊列-單消費者模式、多隊列(優先級隊列)- 單消費者模式、多隊列(優先級隊列)- 多消費者模式。
我們先從最簡單的單隊列-單消費者模式實現,然后一步步演化成多隊列(優先級隊列)-多消費者模式。
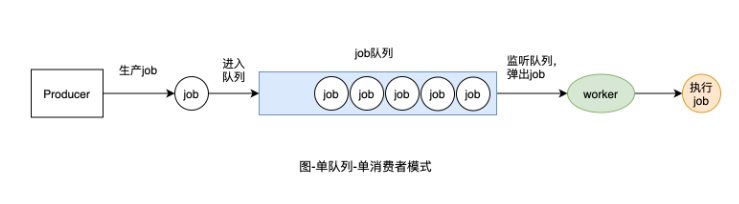
我們先來看下隊列的實現。這里我們用Golang中的List數據結果來實現,List數據結構是一個雙向鏈表,包含了將元素放到鏈表尾部、將頭部元素彈出的操作,符合隊列先進先出的特性。
好,我們看下具體的隊列的數據結構:
type JobQueue struct {
mu sync.Mutex //隊列的操作需要并發安全
jobList *list.List //List是golang庫的雙向隊列實現,每個元素都是一個job
noticeChan chan struct{} //入隊一個job就往該channel中放入一個消息,以供消費者消費
}入隊操作
/**
* 隊列的Push操作
*/
func (queue *JobQueue) PushJob(job Job) {
queue.jobList.PushBack(job) //將job加到隊尾
queue.noticeChan <- struct{}{}
}到這里有同學就會問了,為什么不直接將job推送到Channel中,然后讓消費者依次消費不就行了么?是的,單隊列這樣是可以的,因為我們最終目標是為了實現優先級的多隊列,所以這里即使是單隊列,我們也使用List數據結構,以便后續的演變。
還有一點,大家注意到了,這里入隊操作時有一個 這樣的操作:
queue.noticeChan <- struct{}{}消費者監聽的實際上不是隊列本身,而是通道noticeChan。當有一個元素入隊時,就往noticeChan通道中輸入一條消息,這里是一個空結構體,主要作用就是通知消費者worker,隊列里有要處理的元素了,可以從隊列中獲取了。 這個在后面演化成多隊列以及多消費者模式時會很有用。
出隊操作
根據隊列的先進先出原則,是要獲取隊列的最先進入的元素。Golang中List結構體的Front()函數是獲取鏈表的第一個元素,然后通過Remove函數將該元素從鏈表中移出,即得到了隊列中的第一個元素。這里的Job結構體先不用關心,我們后面實現工作單元Job時,會詳細講解。
/**
* 彈出隊列的第一個元素
*/
func (queue *JobQueue) PopJob() Job {
queue.mu.Lock()
defer queue.mu.Unlock()
/**
* 說明在隊列中沒有元素了
*/
if queue.jobList.Len() == 0 {
return nil
}
elements := queue.jobList.Front() //獲取隊里的第一個元素
return queue.jobList.Remove(elements).(Job) //將元素從隊列中移除并返回
}等待通知操作
上面我們提到,消費者監聽的是noticeChan通道。當有元素入隊時,會往noticeChan中輸入一條消息,以便通知消費者進行消費。如果隊列中沒有要消費的元素,那么消費者就會阻塞在該通道上。
func (queue *JobQueue) WaitJob() <-chan struct{} {
return queue.noticeChan
}一個工作單元就是一個要執行的任務。在系統中往往需要執行不同的任務,就是需要有不同類型的工作單元,但這些工作單元都有一組共同的執行流程。我們看下工作單元的類圖。
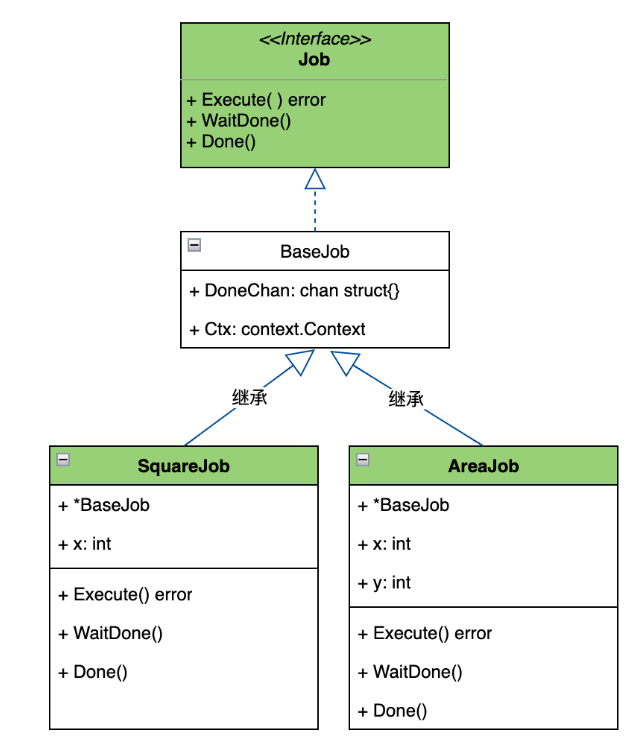
圖-job類圖
我們看下類圖中的幾個角色:
Job接口:定義了所有Job要實現的方法。
BaseJob類(結構體):定義了具體Job的基類。因為具體Job類中的有共同的屬性和方法。所以抽象出一個基類,避免重復實現。但該基類對Execute方法沒有實現,因為不同的工作單元有具體的執行邏輯。
SquareJob和AreaJob類(結構體):是我們要具體實現的業務工作Job。主要是實現Execute的具體執行邏輯。根據業務的需要定義自己的工作Job和對應的Execute方法即可。
接下來,我們以計算一個int類型數字的平方的SquareJob為例來看下具體的實現。
BaseJob結構體
首先看下該結構體的定義
type BaseJob struct {
Err error
DoneChan chan struct{} //當作業完成時,或者作業被取消時,通知調用者
Ctx context.Context
cancelFunc context.CancelFunc
}在該結構體中,我們主要關注DoneChan字段就行,該字段是當具體的Job的Execute執行完成后,來通知調用者的。
再來看Done函數,該函數就是在Execute函數完成后,要關閉DoneChan通道,以解除Job的阻塞而繼續執行其他邏輯。
/**
* 作業執行完畢,關閉DoneChan,所有監聽DoneChan的接收者都能收到關閉的信號
*/
func (job *BaseJob) Done() {
close(job.DoneChan)
}再來看WaitDone函數,該函數是當Job執行后,要等待Job執行完成,在未完成之前,DoneChan里沒有消息,通過該函數就能將job阻塞,直到Execute中調用了Done(),以便解除阻塞。
/**
* 等待job執行完成
*/
func (job *BaseJob) WaitDone() {
select {
case <-job.DoneChan:
return
}
}SquareJob結構體
type SquareJob struct {
*BaseJob
x int
}從結構體的定義中可知,SquareJob嵌套了BaseJob,所以該結構體擁有BaseJob的所有字段和方法。在該結構體主要實現了Execute的邏輯:對x求平方。
func (s *SquareJob) Execute() error {
result := s.x * s.x
fmt.Println("the result is ", result)
return nil
}Worker主要功能是通過監聽隊列里的noticeChan是否有需要處理的元素,如果有元素的話從隊列里獲取到要處理的元素job,然后執行job的Execute方法。
我們將該結構體定位為WorkerManager,因為在后面我們講解多Worker模式時,會需要一個Worker的管理者,因此定義成了WorkerManager。
type WorkerManager struct {
queue *JobQueue
closeChan chan struct{}
}StartWorker函數,只有一個for循環,不斷的從隊列中獲取Job。獲取到Job后,進行消費Job,即ConsumeJob。
func (m *WorkerManager) StartWork() error {
fmt.Println("Start to Work")
for {
select {
case <-m.closeChan:
return nil
case <-m.queue.noticeChan:
job := m.queue.PopJob()
m.ConsumeJob(job)
}
}
return nil
}
func (m *WorkerManager) ConsumeJob(job Job) {
defer func() {
job.Done()
}()
job.Execute()
}到這里,單隊列-單消費者模式中各角色的實現就講解完了。我們通過main函數將其關聯起來。
func main() {
//初始化一個隊列
queue := &JobQueue{
jobList: list.New(),
noticeChan: make(chan struct{}, 10),
}
//初始化一個消費worker
workerManger := NewWorkerManager(queue)
// worker開始監聽隊列
go workerManger.StartWork()
// 構造SquareJob
job := &SquareJob{
BaseJob: &BaseJob{
DoneChan: make(chan struct{}, 1),
},
x: 5,
}
//壓入隊列尾部
queue.PushJob(job)
//等待job執行完成
job.WaitDone()
print("The End")
}有了單隊列-單消費者的基礎,我們如何實現多隊列-單消費者模式。也就是優先級隊列。
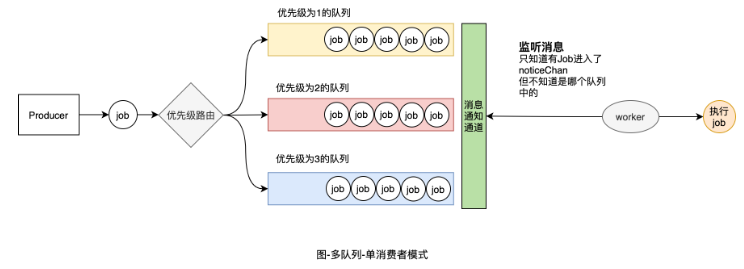
優先級的隊列,實質上就是根據工作單元Job的優先級屬性,將其放到對應的優先級隊列中,以便worker可以根據優先級進行消費。我們要在Job結構體中增加一個Priority屬性。因為該屬性是所有Job都共有的,因此定義在BaseJob上更合適.
type BaseJob struct {
Err error
DoneChan chan struct{} //當作業完成時,或者作業被取消時,通知調用者
Ctx context.Context
cancelFunc context.CancelFunc
priority int //工作單元的優先級
}我們再來看看多隊列如何實現。實際上就是用一個切片來存儲各個隊列,切片的每個元素存儲一個JobQueue隊列元素即可。
var queues = make([]*JobQueue, 10, 100)
那各優先級的隊列在切片中是如何存儲的呢?切片索引順序只代表優先級的高于低,不代表具體是哪個優先級。
什么意思呢?假設我們現在對目前的工作單元定義了1、4、7三個優先級。這3個優先級在切片中是按優先級從小到到依次存儲在queues切片中的,如下圖:
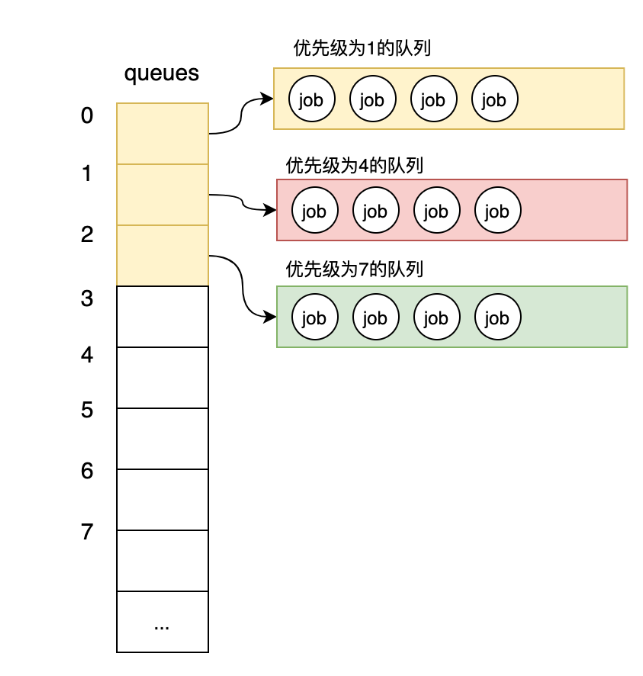
圖-正確的切片存儲的優先級
那為什么不讓切片的索引就代表優先級,讓優先級為1的隊列存儲在索引1處,優先級4的隊列存儲在索引4處,優先級7的隊列存儲在索引7處呢?如果這樣存儲的話,就會變成如下這樣:
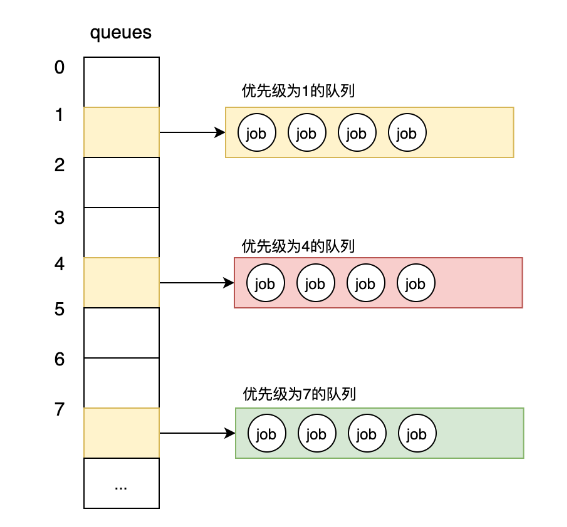
圖4-直接使用索引作為優先級缺點
可見如果我們設定的優先級不是連續的,那么就會造成空間的浪費。所以,我們是將隊列按優先級高低依次存放到了切片中。
那既然這樣,當一個優先級的job來了之后,我該怎么知道該優先級的隊列是存儲在哪個索引中呢?我們用一個map來映射優先級和切片索引之間的關系。這樣當一個工作單元Job入隊的時候,以優先級為key,就可以查找到對應優先級的隊列存儲在切片的哪個位置了。如下圖所示:
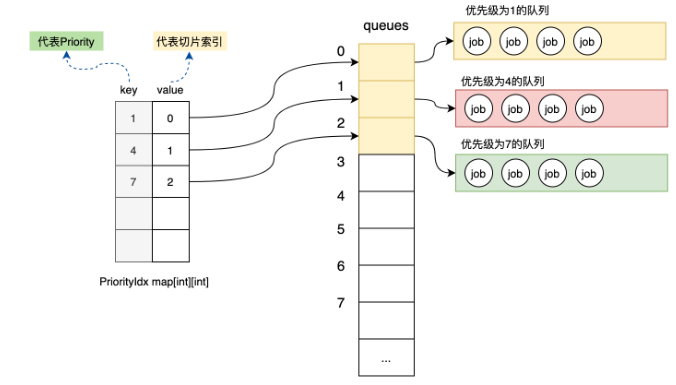
圖-優先級和索引映射
代碼定義:
var priorityIdx map[int][int]//該map的key是優先級,value代表的是queues切片的索引
好了,我們重新定義一下隊列的結構體:
type PriorityQueue struct {
mu sync.Mutex
noticeChan chan struct{}
queues []*JobQueue
priorityIdx map[int]int
}
//原來的JobQueue會變成如下這樣:
type JobQueue struct {
priority int //代表該隊列是哪種優先級的隊列
jobList *list.List //List是golang庫的雙向隊列實現,每個元素都是一個job
}這里我們注意到有以下幾個變化:
JobQueue里多了一個Priority屬性,代表該隊列是哪個優先級別。noticeChan屬性從JobQueue中移動到了PriorityQueue中。因為現在有多個隊列,只要任意一個隊列里有元素就需要通知消費者worker進行消費,因此消費者worker監聽的是PriorityQueue中是否有元素,而在監聽階段不關心具體哪個優先級隊列中有元素。
好了,數據結構定義完了,我們看看將工作單元Job推入隊列和從隊列中彈出Job又有什么變化。
優先級隊列的入隊操作
優先級隊列的入隊操作,就需要根據入隊Job的優先級屬性放到對應的優先級隊列中,入隊流程圖如下:
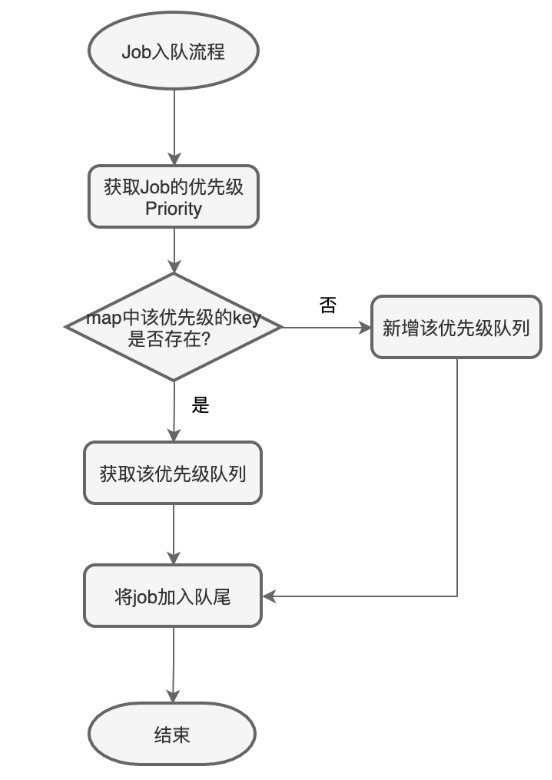
圖-優先級隊列入隊流程
當一個Job加入隊列的時候,有兩種場景,一種是該優先級的隊列已經存在,則直接Push到隊尾即可。一種是該優先級的隊列還不存在,則需要先創建該優先級的隊列,然后再將該工作單元Push到隊尾。如下是兩種場景。
隊列已經存在的場景
這種場景會比較簡單。假設我們要插入優先級為7的工作單元,首先從映射表中查找7是否存在,發現對應關系是2,則直接找到切片中索引2的元素,即優先級為7的隊列,將job加入即可。如下圖。
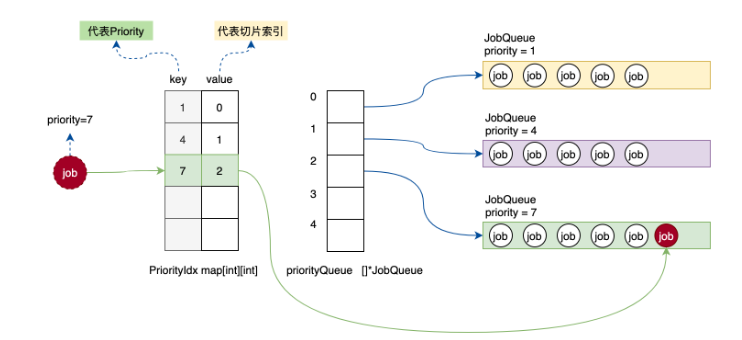
圖-已存在隊列插入
隊列不存在的場景
這種場景稍微復雜些,在映射表中找不到要插入優先級的隊列的話,則需要在切片中插入一個優先級隊列,而為了優先級隊列在切片中也保持有序(保持有序就可以知道隊列的優先級的高低了),則需要移動相關的元素。我們以插入優先級為6的工作單元為例來講解。
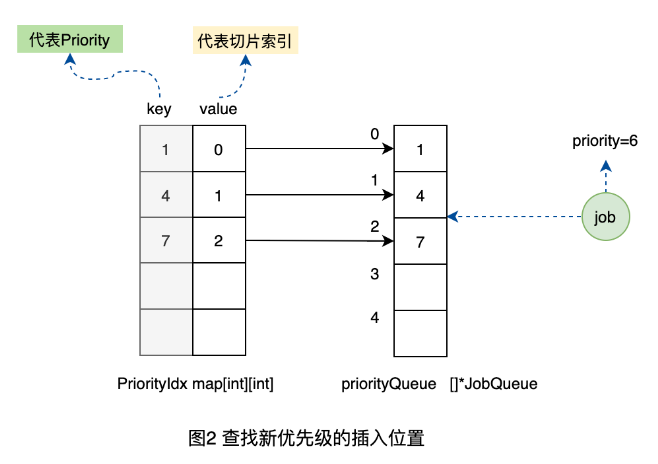
1、首先,我們的隊列有一個初始化的狀態,存儲了優先級1、4、7的隊列。如下圖。

2、當插入優先級為6的工作單元時,發現在映射表中沒有優先級6的映射關系,說明在切片中還沒有優先級為6的隊列的元素。所以需要在切片中依次查找到優先級6應該插入的位置在4和7之間,也就是需要存儲在切片2的位置。
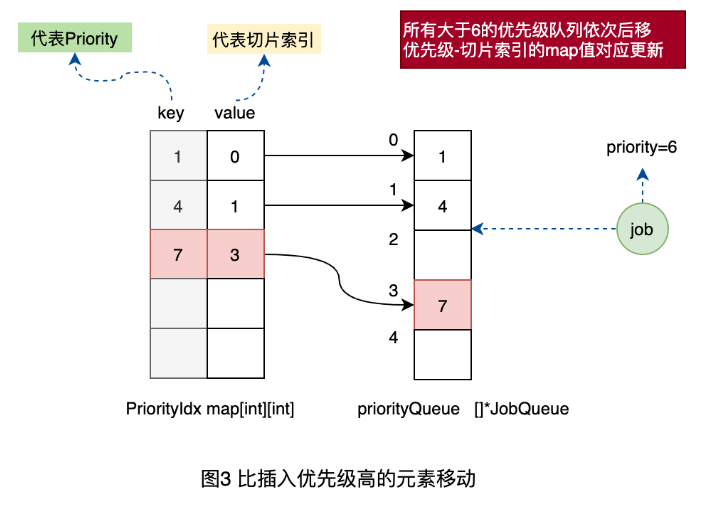
3、將原來索引2位置的優先級為7的隊列往后移動到3,同時更新映射表中的對應關系。
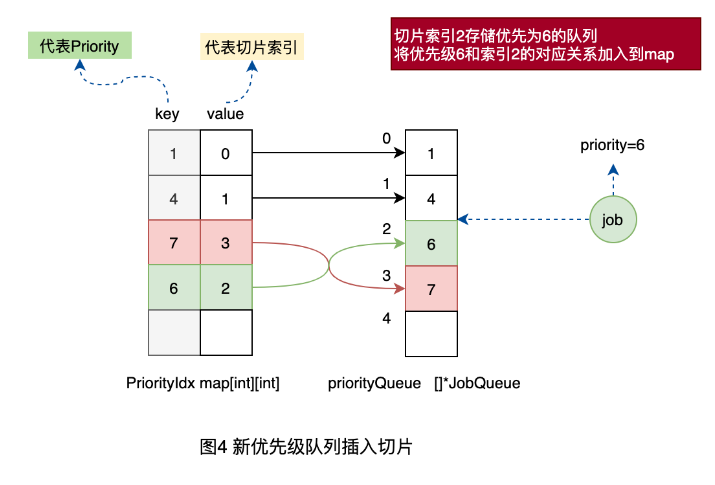
4、將優先級為6的工作單元插入到索引2的隊列中,同時更新映射表中的優先級和索引的關系。
我們看下代碼實現:
func (priorityQueue *PriorityQueue) Push(job Job) {
priorityQueue.mu.Lock()
defer priorityQueue.mu.Unlock()
//先根據job的優先級找要入隊的隊列
var idx int
var ok bool
//從優先級-切片索引的map中查找該優先級的隊列是否存在
if idx, ok = priorityQueue.priorityIdx[job.Priority()]; !ok {
//如果不存在該優先級的隊列,則需要初始化一個隊列,并返回該隊列在切片中的索引位置
idx = priorityQueue.addPriorityQueue(job.Priority)
}
//根據獲取到的切片索引idx,找到具體的隊列
queue := priority.queues[idx]
//將job推送到隊列的隊尾
queue.JobList.PushBack(job)
//隊列job個數+1
priorityQueue.Size++
//如果隊列job個數超過隊列的最大容量,則從優先級最低的隊列中移除工作單元
if priorityQueue.size > priorityQueue.capacity {
priorityQueue.RemoveLeastPriorityJob()
}else {
//通知新進來一個job
priorityQueue.noticeChan <- struct{}{}
}
}代碼中大部分也都做了注釋,不難理解。這里我們來看下addPriorityQueue的具體實現:
func (priorityQueue *PriorityQueue) addPriorityQueue(priority int) int {
n := len(priorityQueue.queues)
//通過二分查找找到priority應插入的切片索引
pos := sort.Search(n, func(i int) bool {
return priority < priorityQueue.priority
})
//更新映射表中優先級和切片索引的對應關系
for i := pos; i < n; i++ {
priorityQueue.priorityIdx[priorityQueue.queues[i].priority] = i + 1
}
tail := make([]*jobQueue, n-pos)
copy(tail, priorityQueue.queues[pos:])
//初始化一個新的優先級隊列,并將該元素放到切片的pos位置中
priorityQueue.queues = append(priorityQueue.queues[0:pos], newJobQueue(priority))
//將高于priority優先級的元素也拼接到切片后面
priorityQueue.queues = append(priorityQueue.queues, tail...)
return pos
}最后,我們再來看一個實際的調用例子:
func main() {
//初始化一個隊列
queue := &PriorityQueue{
noticeChan: make(chan struct{}, cap),
capacity: cap,
priorityIdx: make(map[int]int),
size: 0,
}
//初始化一個消費worker
workerManger := NewWorkerManager(queue)
// worker開始監聽隊列
go workerManger.StartWork()
// 構造SquareJob
job := &SquareJob{
BaseJob: &BaseJob{
DoneChan: make(chan struct{}, 1),
},
x: 5,
priority: 10,
}
//壓入隊列尾部
queue.PushJob(job)
//等待job執行完成
job.WaitDone()
print("The End")
}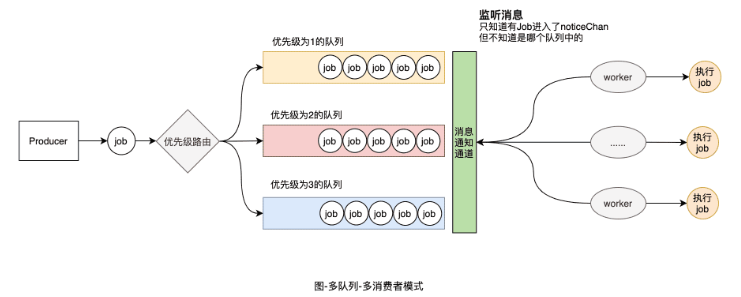
我們在多隊列-單消費者的基礎上,再來看看多消費者模式。也就是增加worker的數量,提高Job的處理速度。
我們再來看下worker的定義:
type WorkerManager struct {
queue *PriorityQueue
closeChans []chan struct{}
}這里需要注意,closeChans變成了切片數組。因為我們每啟動一個worker,就需要有一個關閉通道。
然后看StartWorker函數的實現:
func (m *WorkerManager) StartWork(n int) error {
fmt.Println("Start to Work")
for i := 0; i < n; i++ {
m.createWorker();
}
return nil
}
func (m *WorkerManager) createWorker() {
closeChan := make(chan struct{})
//每個協程,就是一個worker
go func(closeChan chan struct{}) {
var job Job
for {
select {
case <-m.closeChan:
return nil
case <-m.queue.noticeChan:
job := m.queue.PopJob()
m.ConsumeJob(job)
}
}
}(closeChan)
m.closeChanMu.Lock()
defer m.closeChanMu.Unlock()
m.closeChans = append(m.closeChans, closeChan)
return nil
}
func (m *WorkerManager) ConsumeJob(job Job) {
defer func() {
job.Done()
}()
job.Execute()
}這里需要注意的是,所有的worker都需要監聽隊列的noticeChan通道。測試的例子就留給讀者自己了。
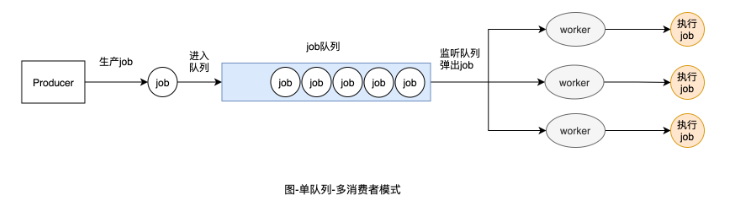
另外如下圖的單隊列-多消費者模式是多隊列-多消費者模式的一個特例,這里就不再進行實現了。
以上就是“Go單隊列到優先級隊列如何實現”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





