溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python中pytorch圖像識別的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
現在的深度學習對數據集量的需求越來越大了,也有了許多現成的數據集可供大家查找下載,但是如果你只是想要做一下深度學習的實例以此熟練一下或者找不到好的數據集,那么你也可以嘗試自己制作數據集——自己從網上爬取圖片,下面是通過百度圖片爬取數據的示例。
import os
import time
import requests
import re
def imgdata_set(save_path,word,epoch):
q=0 #停止爬取圖片條件
a=0 #圖片名稱
while(True):
time.sleep(1)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn={}&ct=&ic=0&lm=-1&width=0&height=0".format(word,q)
#word=需要搜索的名字
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
response=requests.get(url,headers=headers)
# print(response.request.headers)
html=response.text
# print(html)
urls=re.findall('"objURL":"(.*?)"',html)
# print(urls)
for url in urls:
print(a) #圖片的名字
response = requests.get(url, headers=headers)
image=response.content
with open(os.path.join(save_path,"{}.jpg".format(a)),'wb') as f:
f.write(image)
a=a+1
q=q+20
if (q/20)>=int(epoch):
break
if __name__=="__main__":
save_path = input('你想保存的路徑:')
word = input('你想要下載什么圖片?請輸入:')
epoch = input('你想要下載幾輪圖片?請輸入(一輪為60張左右圖片):') # 需要迭代幾次圖片
imgdata_set(save_path, word, epoch)通過上述的代碼可以自行選擇自己需要保存的圖片路徑、圖片種類和圖片數目。如我下面做的幾種常見的盆栽植物的圖片爬取,只需要執行六次代碼,改變相應的盆栽植物的名稱就可以了。下面是爬取盆栽蘆薈的輸入示例,輸入完成后按Enter執行即可,會自動爬取圖片保存到指定文件夾,

如圖即為爬取后的圖片。
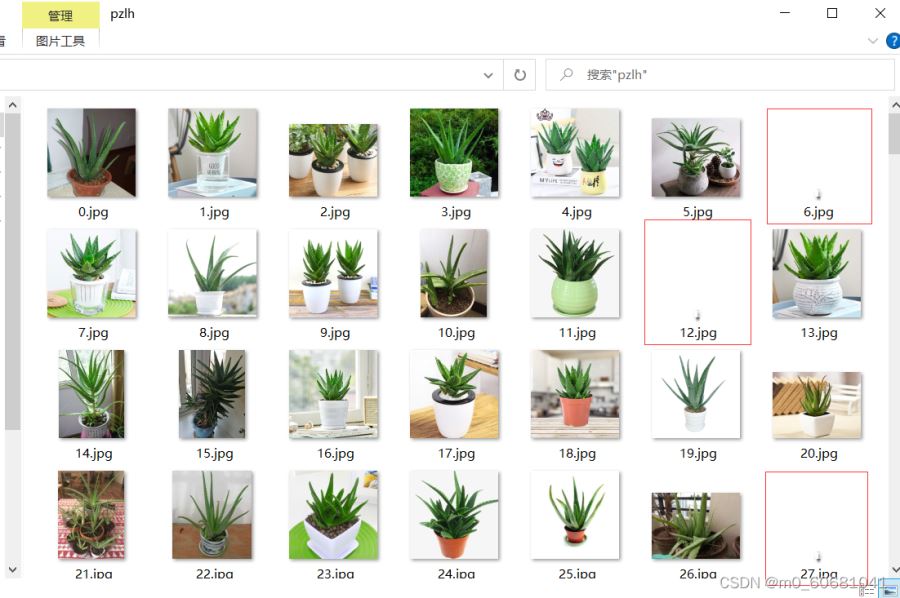
可以看到圖片中出現了一些無法打開的圖片,同時因為是直接爬取的網絡上的圖片,可能會出現一些相同的圖片,這些都需要進行刪除,這就需要我們進行第二步處理了。
由于上面直接爬取到的圖片有一些瑕疵,這就需要對圖片進行進一步的處理了,對圖片進行去重處理
通過重復圖片去重處理,將自己需要的數據集按照種類分別保存在各自的文件夾里。同樣,由于數據集可能存在無法打開的圖片,這就需要對數據集進行下一步處理了。
首先將上面去重處理后的文件夾統一保存在同一個文件夾里面,如下圖所示。
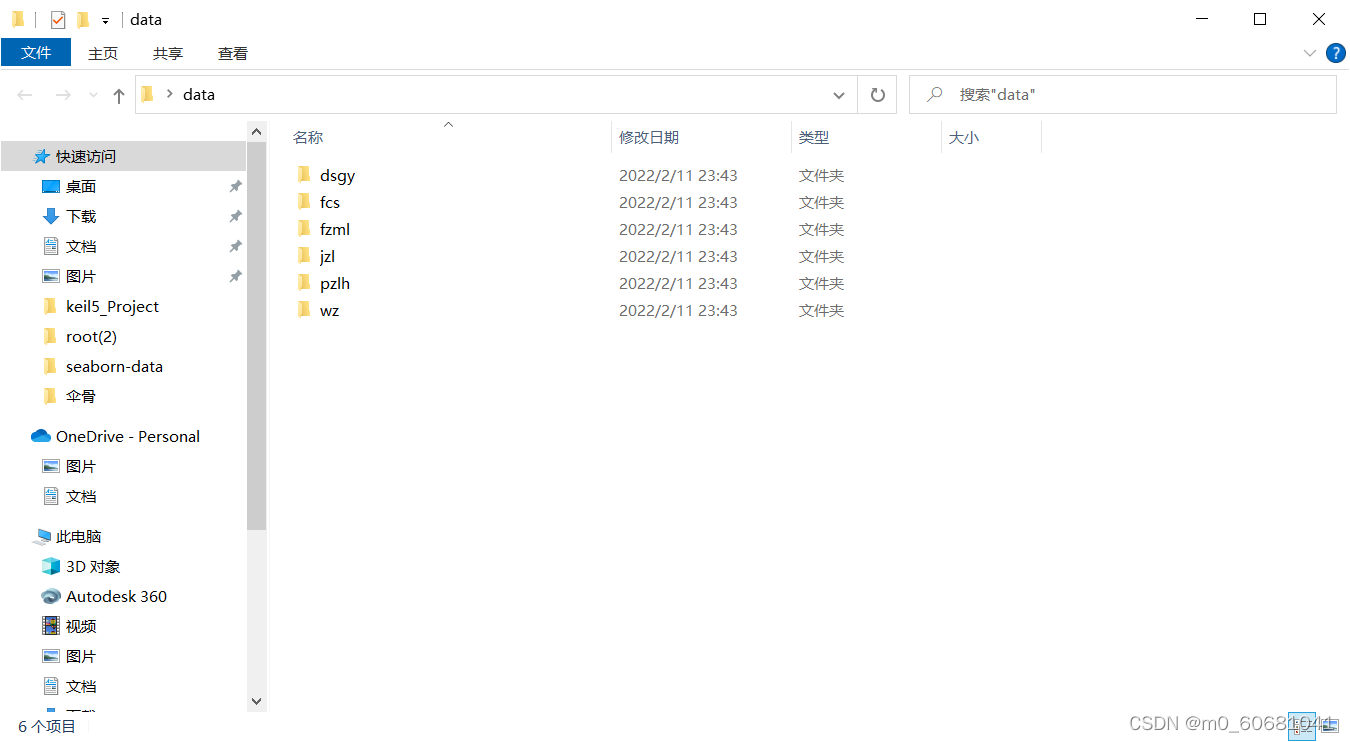
記住此文件夾路徑,我這里是‘C:\Users\Lenovo\Desktop\data’,將此路徑輸入到下面代碼中。
import os
from PIL import Image
root_path=r"C:\Users\Lenovo\Desktop\data" #待處理文件夾絕對路徑(可按‘Ctrl+Shift+c'復制)
root_names=os.listdir(root_path)
for root_name in root_names:
path=os.path.join(root_path,root_name)
print("正在刪除文件夾:",path)
names=os.listdir(path)
names_path=[]
for name in names:
# print(name)
img=Image.open(os.path.join(path,name))
name_path=os.path.join(path,name)
if img==None: #篩選無法打開的圖片
names_path.append(name_path)
print('成功保存錯誤圖片路徑:{}'.format(name))
else:
w,h=img.size
if w<50 or h<50: #篩選錯誤圖片
names_path.append(name_path)
print('成功保存特小圖片路徑:{}'.format(name))
print("開始刪除需刪除的圖片")
for r in names_path:
os.remove(r)
print("已刪除:",r)經過上述處理即完成了圖片數據集的處理。最后,也可以對圖片數據集進行圖片名稱的處理,使圖片的名稱重新從零開始依次排列,方便計數(注意下面代碼中的rename將會刪除掉原文件夾中的圖片)。
import os root_dir=r"C:\Users\Lenovo\Desktop\pzlh" #原文件夾路徑 save_path=r"C:\Users\Lenovo\Desktop\pzlh3" #新建文件夾路徑 img_path=os.listdir(root_dir) a=0 for i in img_path: a+=1 i= os.path.join(os.path.abspath(root_dir), i) new_name=os.path.join(os.path.abspath(save_path), str(a) + '_pzlh.jpg') #此處可以修改圖片名稱 os.rename(i,new_name) #特別注意:rename會刪除原圖
最后,我們可以得到一個將完整的常見盆栽植物的數據集。如果此時數據集的圖片數量不多,我們還可以采用數據增強的方法,如旋轉,加噪等步驟,都可以在網上找到相應的教程。最后,我們可以得到數據集如下圖所示。

首先,先為上面的圖片數據集生成對應的標簽文件,運行下面代碼可以自動生成對應的標簽文件。
import os
root_path=r"C:\Users\Lenovo\Desktop\data"
save_path=r"C:\Users\Lenovo\Desktop\data_label" #對應的label文件夾下也要建好相應的空子文件夾
names=os.listdir(root_path) #得到images文件夾下的子文件夾的名稱
for name in names:
path=os.path.join(root_path,name)
img_names=os.listdir(path) #得到子文件夾下的圖片的名稱
for img_name in img_names:
save_name = img_name.split(".jpg")[0]+'.txt' #得到相應的lable名稱
txt_path=os.path.join(save_path,name) #得到label的子文件夾的路徑
with open(os.path.join(txt_path,save_name), "w") as f: #結合子文件夾路徑和相應子文件夾下圖片的名稱生成相應的子文件夾txt文件
f.write(name) #將label寫入對應txt文件夾
print(f.name)然后,將上面已經準備好的數據集按照7:3(其他比例也可以)分為訓練數據集和驗證數據集(圖片和標簽一定要完全對應即對應圖片和標簽應該都處于訓練集或者數據集),并如下圖所示放置。

最后,數據集準備好后,即可導入到模型開始訓練,運行下列代碼
import time
from torch.utils.tensorboard import SummaryWriter
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision.models as models
import torch.nn as nn
import torch
print("是否使用GPU訓練:{}".format(torch.cuda.is_available())) #打印是否采用gpu訓練
if torch.cuda.is_available:
print("GPU名稱為:{}".format(torch.cuda.get_device_name())) #打印相應的gpu信息
#數據增強太多也可能造成訓練出不好的結果,而且耗時長,宜增強兩三倍即可。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]) #規范化
transform=transforms.Compose([ #數據處理
transforms.Resize((64,64)),
transforms.ToTensor(),
normalize
])
dataset_train=ImageFolder('data/train',transform=transform) #訓練數據集
# print(dataset_tran[0])
dataset_valid=ImageFolder('data/valid',transform=transform) #驗證或測試數據集
# print(dataset_train.classer)#返回類別
print(dataset_train.class_to_idx) #返回類別及其索引
# print(dataset_train.imgs)#返回圖片路徑
print(dataset_valid.class_to_idx)
train_data_size=len(dataset_train) #放回數據集長度
test_data_size=len(dataset_valid)
print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))
#torch自帶的標準數據集加載函數
dataloader_train=DataLoader(dataset_train,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
dataloader_test=DataLoader(dataset_valid,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
#2.模型加載
model_ft=models.resnet18(pretrained=True)#使用遷移學習,加載預訓練權重
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6))#將最后的全連接改為(36,6),使輸出為六個小數,對應六種植物的置信度
#凍結卷積層函數
# for i,para in enumerate(model_ft.parameters()):
# if i<18:
# para.requires_grad=False
# print(model_ft)
# model_ft.half()#可改為半精度,加快訓練速度,在這里不適用
model_ft=model_ft.cuda()#將模型遷移到gpu
#3.優化器
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda() #將loss遷移到gpu
learn_rate=0.01 #設置學習率
optimizer=torch.optim.SGD(model_ft.parameters(),lr=learn_rate,momentum=0.01)#可調超參數
total_train_step=0
total_test_step=0
epoch=50 #迭代次數
writer=SummaryWriter("logs_train_yaopian")
best_acc=-1
ss_time=time.time()
for i in range(epoch):
start_time = time.time()
print("--------第{}輪訓練開始---------".format(i+1))
model_ft.train()
for data in dataloader_train:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()#為上述改為半精度操作,在這里不適用
imgs=imgs.cuda()
targets=targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
optimizer.zero_grad() #梯度歸零
loss.backward() #反向傳播計算梯度
optimizer.step() #梯度優化
total_train_step=total_train_step+1
if total_train_step%100==0:#一輪時間過長可以考慮加一個
end_time=time.time()
print("使用GPU訓練100次的時間為:{}".format(end_time-start_time))
print("訓練次數:{},loss:{}".format(total_train_step,loss.item()))
# writer.add_scalar("valid_loss",loss.item(),total_train_step)
model_ft.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #驗證數據集時禁止反向傳播優化權重
for data in dataloader_test:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()
imgs = imgs.cuda()
targets = targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整體測試集上的loss:{}(越小越好,與上面的loss無關此為測試集的總loss)".format(total_test_loss))
print("整體測試集上的正確率:{}(越大越好)".format(total_accuracy / len(dataset_valid)))
writer.add_scalar("valid_loss",(total_accuracy/len(dataset_valid)),(i+1))#選擇性使用哪一個
total_test_step = total_test_step + 1
if total_accuracy > best_acc: #保存迭代次數中最好的模型
print("已修改模型")
best_acc = total_accuracy
torch.save(model_ft, "best_model_yaopian.pth")
ee_time=time.time()
zong_time=ee_time-ss_time
print("訓練總共用時:{}h:{}m:{}s".format(int(zong_time//3600),int((zong_time%3600)//60),int(zong_time%60))) #打印訓練總耗時
writer.close()上述采用的遷移學習直接使用resnet18的模型進行訓練,只對全連接的輸出進行修改,是一種十分方便且實用的方法,同樣,你也可以自己編寫模型,然后使用自己的模型進行訓練,但是這種方法顯然需要訓練更長的時間才能達到擬合。如圖所示,只需要修改矩形框內部分,將‘model_ft=models.resnet18(pretrained=True)'改為自己的模型‘model_ft=model’即可。

經過上述的步驟后,我們將會得到一個‘best_model_yaopian.pth’的模型權重文件,最后運行下列代碼就可以對圖片進行識別了
import os
import torch
import torchvision
from PIL import Image
from torch import nn
i=0 #識別圖片計數
root_path="測試_data" #待測試文件夾
names=os.listdir(root_path)
for name in names:
print(name)
i=i+1
data_class=['滴水觀音','發財樹','非洲茉莉','君子蘭','盆栽蘆薈','文竹'] #按文件索引順序排列
image_path=os.path.join(root_path,name)
image=Image.open(image_path)
print(image)
transforms=torchvision.transforms.Compose([torchvision.transforms.Resize((64,64)),
torchvision.transforms.ToTensor()])
image=transforms(image)
print(image.shape)
model_ft=torchvision.models.resnet18() #需要使用訓練時的相同模型
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6)) #此處也要與訓練模型一致
model=torch.load("best_model_yaopian.pth",map_location=torch.device("cpu")) #選擇訓練后得到的模型文件
# print(model)
image=torch.reshape(image,(1,3,64,64)) #修改待預測圖片尺寸,需要與訓練時一致
model.eval()
with torch.no_grad():
output=model(image)
print(output) #輸出預測結果
# print(int(output.argmax(1)))
print("第{}張圖片預測為:{}".format(i,data_class[int(output.argmax(1))])) #對結果進行處理,使直接顯示出預測的植物種類最后,通過上述步驟我們可以得到一個簡單的盆栽植物智能識別程序,對盆栽植物進行識別,如下圖是識別結果說明。

關于“python中pytorch圖像識別的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





