溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python如何實現圖片文字識別”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python如何實現圖片文字識別”這篇文章吧。
什么是OCR?
光學字符識別(Optical Character Recognition, OCR),是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。簡而言之,檢測圖像中的文本資料,并且識別出文本的內容。
那么有哪些應用場景呢?
其實我們日常生活中處處都有ocr的影子,比如在疫情期間身份證識別錄入信息、車輛車牌號識別、自動駕駛等。我們的生活中,機器學習已經越來越多的扮演著重要角色,也不再是神秘的東西。
OCR的技術路線是什么呢?
ocr的運行方式如下圖,輸入->圖像預處理->文字檢測->文本識別->輸出。

我會按照剛接觸的狀態,梳理一下驗證使用該項目的過程。
首先我們看一下項目的構造。
發現項目有中文的介紹說明,這就很方便了,點開按照官方的說明開始操作。
點開README.md,,可以從文檔教程中看到第一步就是教你如何安裝環境。
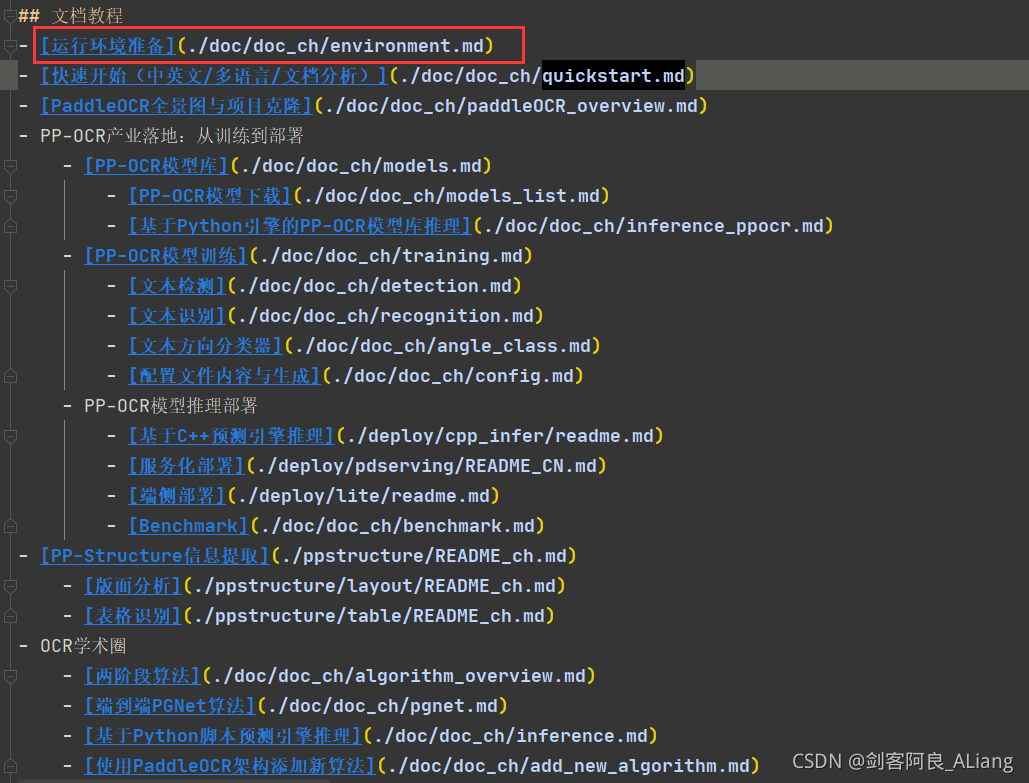
由于內容過多,我就做個概括,方便大家直接上手。
這里可以參考我的另一篇文章,里面很詳細:Python 機器學習第一章環境配置圖解流程
官方給的是python3.8的虛擬環境,我們也構造一個,打開Anaconda Prompt。
輸入命令:
conda create -n paddle_env python=3.8
激活環境:
conda activate paddle_env
paddlepaddle安裝
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
layoutparser安裝
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
Shapely安裝,這個需要下載,下載地址:Shapely下載地址
我選的是這個
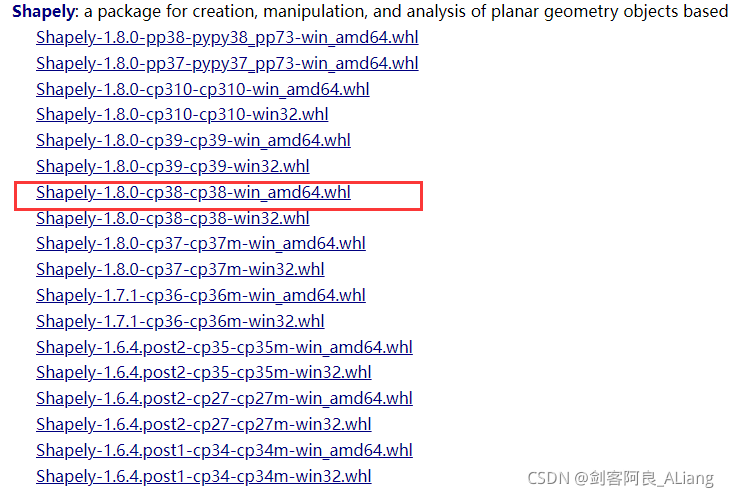
安裝命令:
pip install Shapely-1.8.0-cp38-cp38-win_amd64.whl
paddleocr安裝
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
好的,環境有點多,都安裝好了就開始上手使用吧。
官方給出了兩種模式,一是命令行執行,一是代碼執行。為了直觀的看到配置,我這里使用的是代碼模式。
準備一張帶文字的圖片

測試代碼如下
#!/user/bin/env python
# coding=utf-8
"""
@project : ocr_paddle
@author : huyi
@file : test.py
@ide : PyCharm
@time : 2021-11-15 14:56:20
"""
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多語言語種可以通過修改lang參數進行切換
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False,
lang="ch") # need to run only once to download and load model into memory
img_path = './data/2.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
# print(line[-1][0], line[-1][1])
print(line)
# 顯示結果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')代碼說明
1、因為我的電腦沒有顯卡,所以設置了use_gpu=False。
2、顯示結果部分會將識別的文字用框標出來,并且展示識別的結果。
驗證一下
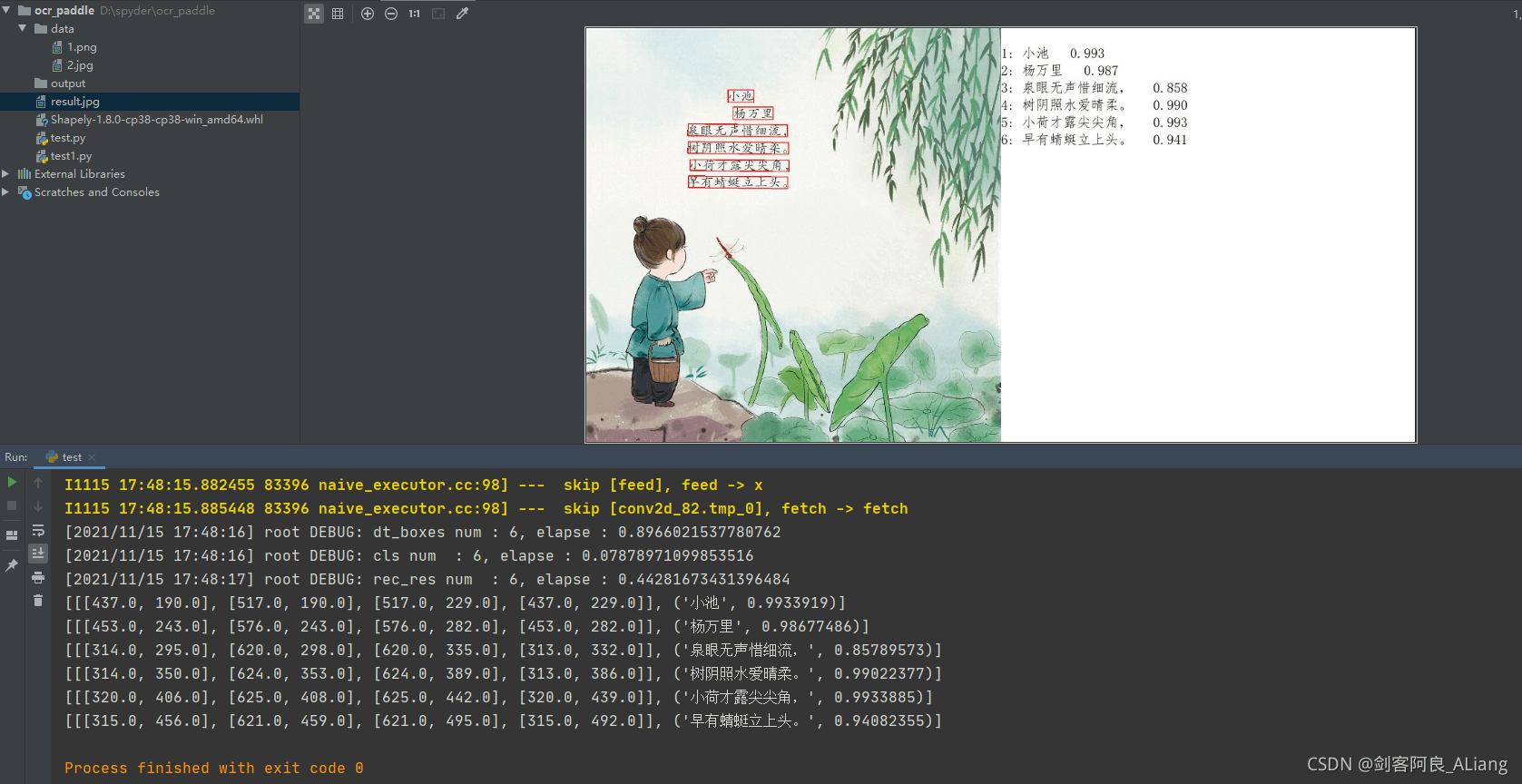
我們看到,打印的內容有識別出來的每句話所在的圖片位置,以及識別結果和可信度。而上面的結果圖中,將每句話對應的文字都框了出來。效果很不錯!
官方還給出了一些參數,可以調整輸出的內容。可以參看quickstart.md文件。參數補充:
- 單獨使用檢測:設置`--rec`為`false`
- 單獨使用識別:設置`--det`為`false`
官方還提供一個標準的json結構輸出數據
PP-Structure的返回結果為一個dict組成的list,示例如下
```shell
[{ 'type': 'Text',
'bbox': [34, 432, 345, 462],
'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
}
]
```
以上是“Python如何實現圖片文字識別”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





