溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Redis中的LRU算法有什么用的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Redis是基于內存存儲的key-value數據庫,我們知道內存雖然快但空間小,當物理內存達到上限時,系統就會跑的很慢,這是因為swap機制會將部分內存的數據轉移到swap分區中,通過與swap的交換保證系統繼續運行;但是swap屬于硬盤存儲,速度遠遠比不上內存,尤其是對于Redis這種QPS非常高的服務,發生這種情況是無法接收的。(注意如果swap分區內存也滿了,系統就會發生錯誤!)【相關推薦:Redis視頻教程】
Linux操作系統可以通過free -m查看swap大小:\

因此如何防止Redis發生這種情況非常重要(面試官問到Redis幾乎沒有不問這個知識點的)。
Redis針對上述問題提供了maxmemory配置,這個配置可以指定Redis存儲器的最大數據集,通常情況都是在redis.conf文件中進行配置,也可以運行時使用CONFIG SET命令進行一次性配置。
redis.conf文件中的配置項示意圖:\
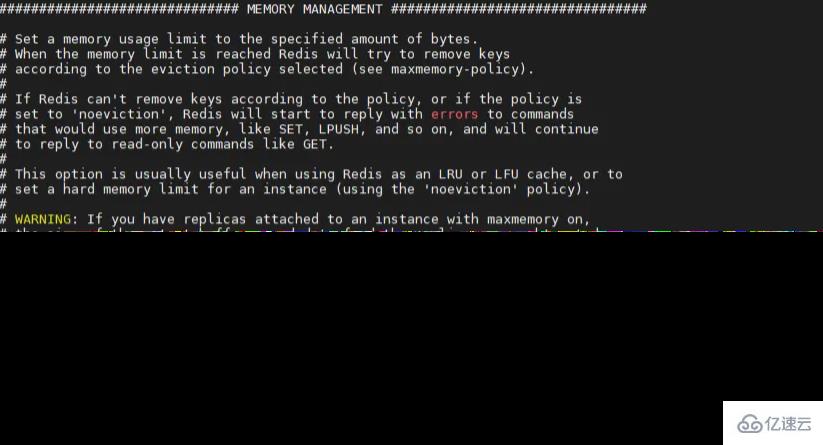
默認情況maxmemory配置項并未啟用,Redis官方介紹64位操作系統默認無內存限制,32位操作系統默認3GB隱式內存配置,如果maxmemory 為0,代表內存不受限。
因此我們在做緩存架構時,要根據硬件資源+業務需求做合適的maxmemory配置。
很顯然配置了最大內存,當maxmemory達到了最大上限之后Redis不可能不干活了,那么Redis是怎么來處理這個問題的呢?這就是本文的重點,Redis 提供了maxmemory-policy淘汰策略(本文只講述LRU不涉及LFU,LFU在下一篇文章講述),對滿足條件的key進行刪除,辭舊迎新。
maxmemory-policy淘汰策略:
noeviction: 當達到內存限制并且客戶端嘗試執行可能導致使用更多內存的命令時返回錯誤,簡單來說讀操作仍然允許,但是不準寫入新的數據,del(刪除)請求可以。
allkeys-lru: 從全體key中,通過lru(Least Recently Used - 最近最少使用)算法進行淘汰
allkeys-random: 從全體key中,隨機進行淘汰
volatile-lru: 從設置了過期時間的全部key中,通過lru(Least Recently Used - 最近最少使用)算法進行淘汰,這樣可以保證未設置過期時間需要被持久化的數據,不會被選中淘汰
volatile-random: 從設置了過期時間的全部key中,隨機進行淘汰
volatile-ttl: 從設置了過期時間的全部key中,通過比較key的剩余過期時間TTL的值,TTL越小越先被淘汰
還有volatile-lfu/allkeys-lfu這個留到下文一起探討,兩個算法不一樣!
random隨機淘汰只需要隨機取一些key進行刪除,釋放內存空間即可;ttl過期時間小先淘汰也可以通過比較ttl的大小,將ttl值小的key進行刪除,釋放內存空間即可。
那么LRU是怎么實現的呢?Redis又是如何知道哪個key最近被使用了,哪個key最近沒有被使用呢?
我們先用Java的容器實現一個簡單的LRU算法,我們使用ConcurrentHashMap做key-value結果存儲元素的映射關系,使用ConcurrentLinkedDeque來維持key的訪問順序。
LRU實現代碼:
package com.lizba.redis.lru;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedDeque;
/**
* <p>
* LRU簡單實現
* </p>
*
* @Author: Liziba
* @Date: 2021/9/17 23:47
*/
public class SimpleLru {
/** 數據緩存 */
private ConcurrentHashMap<String, Object> cacheData;
/** 訪問順序記錄 */
private ConcurrentLinkedDeque<String> sequence;
/** 緩存容量 */
private int capacity;
public SimpleLru(int capacity) {
this.capacity = capacity;
cacheData = new ConcurrentHashMap(capacity);
sequence = new ConcurrentLinkedDeque();
}
/**
* 設置值
*
* @param key
* @param value
* @return
*/
public Object setValue(String key, Object value) {
// 判斷是否需要進行LRU淘汰
this.maxMemoryHandle();
// 包含則移除元素,新訪問的元素一直保存在隊列最前面
if (sequence.contains(key)) {
sequence.remove();
}
sequence.addFirst(key);
cacheData.put(key, value);
return value;
}
/**
* 達到最大內存,淘汰最近最少使用的key
*/
private void maxMemoryHandle() {
while (sequence.size() >= capacity) {
String lruKey = sequence.removeLast();
cacheData.remove(lruKey);
System.out.println("key: " + lruKey + "被淘汰!");
}
}
/**
* 獲取訪問LRU順序
*
* @return
*/
public List<String> getAll() {
return Arrays.asList(sequence.toArray(new String[] {}));
}
}復制代碼測試代碼:
package com.lizba.redis.lru;
/**
* <p>
* 測試最近最少使用
* </p>
*
* @Author: Liziba
* @Date: 2021/9/18 0:00
*/
public class TestSimpleLru {
public static void main(String[] args) {
SimpleLru lru = new SimpleLru(8);
for (int i = 0; i < 10; i++) {
lru.setValue(i+"", i);
}
System.out.println(lru.getAll());
}
}復制代碼測試結果:\

從上數的測試結果可以看出,先加入的key0,key1被淘汰了,最后加入的key也是最新的key保存在sequence的隊頭。
通過這種方案,可以很簡單的實現LRU算法;但缺點也十分明顯,方案需要使用額外的數據結構來保存key的訪問順序,這樣會使Redis內存消耗增加,本身用來優化內存的方案,卻要消耗不少內存,顯然是不行的。
針對這種情況,Redis使用了近似LRU算法,并不是完完全全準確的淘汰掉最近最不經常使用的key,但是總體的準確度也可以得到保證。
近似LRU算法非常簡單,在Redis的key對象中,增加24bit用于存儲最近一次訪問的系統時間戳,當客戶端對Redis服務端發送key的寫入相關請求時,發現內存達到maxmemory,此時觸發惰性刪除;Redis服務通過隨機采樣,選擇5個滿足條件的key(注意這個隨機采樣allkeys-lru是從所有的key中隨機采樣,volatile-lru是從設置了過期時間的所有key中隨機采樣),通過key對象中記錄的最近訪問時間戳進行比較,淘汰掉這5個key中最舊的key;如果內存仍然不夠,就繼續重復這個步驟。
注意,5是Redis默認的隨機采樣數值大小,它可以通過redis.conf中的maxmemory_samples進行配置:\

針對上述的隨機LRU算法,Redis官方給出了一張測試準確性的數據圖:
最上層淺灰色表示被淘汰的key,圖一是標準的LRU算法淘汰的示意圖
中間深灰色層表示未被淘汰的舊key
最下層淺綠色表示最近被訪問的key
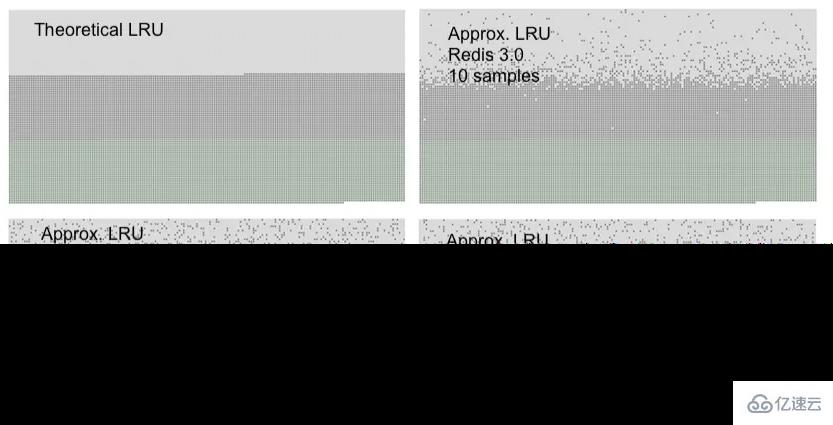
在Redis 3.0 maxmemory_samples設置為10的時候,Redis的近似LRU算法已經非常的接近真實LRU算法了,但是顯然maxmemory_samples設置為10比maxmemory_samples 設置為5要更加消耗CPU計算時間,因為每次采樣的樣本數據增大,計算時間也會增加。
Redis3.0的LRU比Redis2.8的LRU算法更加準確,是因為Redis3.0增加了一個與maxmemory_samples相同大小的淘汰池,每次淘汰key的時候,先與淘汰池中等待被淘汰的key進行比較,最后淘汰掉最老舊的key,其實就是被選中淘汰的key放到一起再比較一下,淘汰其中最舊的。
LRU算法看似比較好用,但是也存在不合理的地方,比如A和B兩個key,在發生淘汰時的前一個小時前同一時刻添加到Redis,A在前49分鐘被訪問了1000次,但是后11分鐘沒有被訪問;B在這一個小時內僅僅第59分鐘被訪問了1次;此時如果使用LRU算法,如果A、B均被Redis采樣選中,A將會被淘汰很顯然這個是不合理的。
針對這種情況Redis 4.0添加了LFU算法,(Least frequently used) 最不經常使用,這種算法比LRU更加合理。
感謝各位的閱讀!關于“Redis中的LRU算法有什么用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





