溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么利用Tensorflow2進行貓狗分類識別”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么利用Tensorflow2進行貓狗分類識別”吧!
使用tf.keras.utils.get_file()能夠從指定的URL當中直接獲取數據集,我們在已知網站當中獲取到貓狗分類所需圖片,為壓縮包格式,將其命名為cats_and_dogs_filtered.zip,為該操作設置一個變量path,該變量指向的便是該數據集下載之后存儲的路徑。
import tensorflow as tf
path=tf.keras.utils.get_file('cats_and_dogs_filtered.zip',origin='https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip')
print(path)#會輸出其路徑,和當前notebook文件路徑相同使用第三方庫zipfile進行文件的解壓,下列代碼將其解壓到了指定的文件夾當中。
import zipfile
local_zip = path
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('C:\\Users\\lenovo\\.keras\\datasets')
zip_ref.close()文件夾當中又有兩個文件夾,分別用于訓練以及驗證神經網絡模型,每個文件夾當中又包含著兩個文件,代表著不同類別的貓與狗的圖片所處位置路徑。
我們在一個神經網絡模型的構建當中,需要訓練集(train data)與驗證集(validation data)。通俗而言,這里的訓練集就是告訴模型貓與狗的外表。而驗證集可以檢查模型的好壞,評估模型的效果。
使用os庫找到貓狗數據的文件夾的路徑,將其根據文件夾劃分為數據集。
import os base_dir = 'C:/Users/lenovo/.keras/datasets/cats_and_dogs_filtered' train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
下面來看一看train文件夾當中的cats文件夾和dogs文件夾當中的文件數據。
train_cat_fnames = os.listdir( train_cats_dir ) train_dog_fnames = os.listdir( train_dogs_dir ) print(train_cat_fnames[:10]) print(train_dog_fnames[:10])
['cat.0.jpg', 'cat.1.jpg', 'cat.10.jpg', 'cat.100.jpg', 'cat.101.jpg', 'cat.102.jpg', 'cat.103.jpg', 'cat.104.jpg', 'cat.105.jpg', 'cat.106.jpg'] ['dog.0.jpg', 'dog.1.jpg', 'dog.10.jpg', 'dog.100.jpg', 'dog.101.jpg', 'dog.102.jpg', 'dog.103.jpg', 'dog.104.jpg', 'dog.105.jpg', 'dog.106.jpg']
同時查看文件當中包含圖片數據數量的大小。
print('total training cat images :', len(os.listdir(train_cats_dir)))
print('total training dog images :', len(os.listdir(train_dogs_dir)))
print('total validation cat images :', len(os.listdir(validation_cats_dir)))
print('total validation dog images :', len(os.listdir(validation_dogs_dir)))total training cat images : 1000 total training dog images : 1000 total validation cat images : 500 total validation dog images : 500
我們了解到對于貓和狗的數據集,我們都有1000張圖片用于訓練模型,500張圖片用于驗證模型效果。
下面對貓狗分類數據集圖片進行輸出,直觀地觀察不同圖片的異同。
#設置畫布大小以及子圖個數 %matplotlib inline import matplotlib.image as mpimg import matplotlib.pyplot as plt nrows = 4 ncols = 4 pic_index = 0
繪制八只貓與八只狗圖片,觀看數據集中圖片有哪些特征。
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off')
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
通過觀察輸出圖片我們發現圖片形狀比例各不相同。與簡單的手寫數字集識別不同的是,手寫數字集都是統一的28*28大小的灰度圖片,而貓狗數據集是長寬各不同的彩色圖片。
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(32, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ])
我們考慮將圖片全部轉化為150*150形狀的圖片,然后添加一系列的卷積層以及池化層,最后展平再進入DNN.
model.summary()#觀察神經網絡的參數
輸出結果:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 18496) 0
_________________________________________________________________
dense (Dense) (None, 512) 9470464
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 9,494,561
Trainable params: 9,494,561
Non-trainable params: 0
_________________________________________________________________
Outshape顯示了圖片在神經網絡中的尺寸變化情況,可以看到在連續的神經網絡層當中,卷積層將圖片尺寸不斷縮小,而池化層一直讓圖片的尺寸減半。
接下來我們將進行模型的編譯。 我們將使用二值交叉熵binary_crossentropy損失訓練我們的模型,因為這是一個二元分類問題,我們的最后一層的激活函數設置為sigmoid,我們將使用學習率為0.001的rmsprop優化器。在訓練期間,我們將要監控分類的準確性。
在這種情況下,使用 RMSprop 優化算法比隨機梯度下降 (SGD) 更可取,因為 RMSprop 為我們自動調整學習率。 (其他優化器例如Adam和Adagrad,也會在訓練期間自動調整學習率,在這里也同樣適用。)
from tensorflow.keras.optimizers import RMSprop model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics = ['acc'])
讓我們設置數據生成器,它將讀取我們源文件夾中的圖片,將它們轉換為張量,并將它們以及它們的標簽提供給神經網絡。我們將得到一個用于訓練圖像的生成器和一個用于驗證圖像的生成器。我們的生成器將批量生成 20 張大小為 150*150 的圖像及其標簽。
進入神經網絡的數據通常應該以某種方式標準化,以使其更易于被神經網絡處理。在我們的例子中,我們將通過將像素值歸一化為 [0,1] 范圍內(最初所有值都在 [0,255] 范圍內)來預處理我們的圖像。
在 Keras 中,這可以通過使用rescale參數的keras.preprocessing.image.ImageDataGenerator類來完成。ImageDataGenerator 通過.flow(data, labels)或.flow_from_directory(directory)得到數據。然后,這些生成器可以與接受數據生成器作為輸入的 Keras 模型方法一起使用:fit_generator、evaluate_generator 和 predict_generator。
from tensorflow.keras.preprocessing.image import ImageDataGenerator #標準化到[0,1] train_datagen = ImageDataGenerator( rescale = 1.0/255. ) test_datagen = ImageDataGenerator( rescale = 1.0/255. ) #批量生成20個大小為大小為 150x150 的圖像及其標簽用于訓練 train_generator = train_datagen.flow_from_directory(train_dir, batch_size=20, class_mode='binary', target_size=(150, 150)) #批量生成20個大小為大小為 150x150 的圖像及其標簽用于驗證 validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=20, class_mode = 'binary', target_size = (150, 150))
Found 2000 images belonging to 2 classes. Found 1000 images belonging to 2 classes.
我們讓所有2000張可用圖像訓練15次,并在所有1000張測試圖像上進行驗證。
我們持續觀察每次訓練的值。在每個時期看到4個值——損失、準確度、驗證損失和驗證準確度。
Loss 和 Accuracy 是訓練進度的一個很好的指標。 它對訓練數據的分類進行猜測,然后根據訓練好的模型對其進行計算結果。 準確度是正確猜測的部分。 驗證準確度是對未在訓練中使用的數據進行的計算。
history = model.fit_generator(train_generator, validation_data=validation_generator, steps_per_epoch=100, epochs=15, validation_steps=50, verbose=2)
結果:
Epoch 1/15
100/100 - 26s - loss: 0.8107 - acc: 0.5465 - val_loss: 0.7072 - val_acc: 0.5040
Epoch 2/15
100/100 - 30s - loss: 0.6420 - acc: 0.6555 - val_loss: 0.6493 - val_acc: 0.5780
Epoch 3/15
100/100 - 31s - loss: 0.5361 - acc: 0.7350 - val_loss: 0.6060 - val_acc: 0.7020
Epoch 4/15
100/100 - 29s - loss: 0.4432 - acc: 0.7865 - val_loss: 0.6289 - val_acc: 0.6870
Epoch 5/15
100/100 - 29s - loss: 0.3451 - acc: 0.8560 - val_loss: 0.8342 - val_acc: 0.6740
Epoch 6/15
100/100 - 29s - loss: 0.2777 - acc: 0.8825 - val_loss: 0.6812 - val_acc: 0.7130
Epoch 7/15
100/100 - 30s - loss: 0.1748 - acc: 0.9285 - val_loss: 0.9056 - val_acc: 0.7110
Epoch 8/15
100/100 - 30s - loss: 0.1373 - acc: 0.9490 - val_loss: 0.8875 - val_acc: 0.7000
Epoch 9/15
100/100 - 29s - loss: 0.0794 - acc: 0.9715 - val_loss: 1.0687 - val_acc: 0.7190
Epoch 10/15
100/100 - 30s - loss: 0.0747 - acc: 0.9765 - val_loss: 1.1952 - val_acc: 0.7420
Epoch 11/15
100/100 - 30s - loss: 0.0430 - acc: 0.9890 - val_loss: 5.6920 - val_acc: 0.5680
Epoch 12/15
100/100 - 31s - loss: 0.0737 - acc: 0.9825 - val_loss: 1.5368 - val_acc: 0.7110
Epoch 13/15
100/100 - 30s - loss: 0.0418 - acc: 0.9880 - val_loss: 1.4780 - val_acc: 0.7250
Epoch 14/15
100/100 - 30s - loss: 0.0990 - acc: 0.9885 - val_loss: 1.7837 - val_acc: 0.7130
Epoch 15/15
100/100 - 31s - loss: 0.0340 - acc: 0.9910 - val_loss: 1.6921 - val_acc: 0.7200
接下來使用模型進行實際運行預測。下面的代碼將判斷指定陌生圖片是狗還是貓。
選擇圖片文件進行預測:
import tkinter as tk from tkinter import filedialog '''打開選擇文件夾對話框''' root = tk.Tk() root.withdraw() Filepath = filedialog.askopenfilename() #獲得選擇好的文件
import numpy as np
from keras.preprocessing import image
path=Filepath
img=image.load_img(path,target_size=(150, 150))
x=image.img_to_array(img)
x=np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0:
print("This is a dog")
else:
print("This is a cat")這樣會彈出一個文件選擇框,選擇文件就可以得到預測的結果。
為了解在神經網絡模型當中學習了什么樣的特征,可以通過可視化輸入在通過神將網絡時如何轉換。
我們從訓練集中隨機選擇一張貓或狗的圖像,然后生成一個圖形,其中每一行是一個層的輸出,而行中的每個圖像都是該輸出特征圖中的特定過濾器。
import numpy as np
import random
from tensorflow.keras.preprocessing.image import img_to_array, load_img
#輸入層
successive_outputs = [layer.output for layer in model.layers[1:]]
#可視化模型
visualization_model = tf.keras.models.Model(inputs = model.input, outputs = successive_outputs)
#隨機選擇一張貓或狗的圖片
cat_img_files = [os.path.join(train_cats_dir, f) for f in train_cat_fnames]
dog_img_files = [os.path.join(train_dogs_dir, f) for f in train_dog_fnames]
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150))
x = img_to_array(img) #轉換為150*150*3的數組
x = x.reshape((1,) + x.shape) #轉換為1*150*150*3的數組
#標準化
x /= 255.0
successive_feature_maps = visualization_model.predict(x)
layer_names = [layer.name for layer in model.layers]
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
if len(feature_map.shape) == 4:
n_features = feature_map.shape[-1]
size = feature_map.shape[ 1]
display_grid = np.zeros((size, size * n_features))
for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std ()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')
display_grid[:, i * size : (i + 1) * size] = x
scale = 20. / n_features
plt.figure( figsize=(scale * n_features, scale) )
plt.title ( layer_name )
plt.grid ( False )
plt.imshow( display_grid, aspect='auto', cmap='viridis' )




如上圖片所示,我們得到從圖像的原始像素到越來越抽象和緊湊的表示。下面的圖像表示開始突出神經網絡關注的內容,并且它們顯示越來越少的特征被“激活”。
這些表示攜帶越來越少的關于圖像原始像素的信息,但越來越精細的關于圖像類別的信息。可以將神將網絡模型視為圖片信息的蒸餾管道,這樣通過一層層的遞進就得到了圖像的較顯著的特征。
輸出訓練過程中隨訓練次數變化的精度與損失值的變化圖
acc = history.history[ 'acc' ]
val_acc = history.history[ 'val_acc' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc))
plt.plot ( epochs, acc ,label='acc')
plt.plot ( epochs, val_acc ,label='val_acc')
plt.legend(loc='best')
plt.title ('Training and validation accuracy')
plt.figure()
plt.plot ( epochs, loss ,label='loss')
plt.plot ( epochs, val_loss ,label='val_loss')
plt.legend(loc='best')
plt.title ('Training and validation loss')通過觀察圖線發現出現了過擬合的現象,我們的訓練準確度接近 100%,而我們的驗證準確度停滯在大概70%。我們的驗證損失值僅在五個epoch后就達到了最小值。
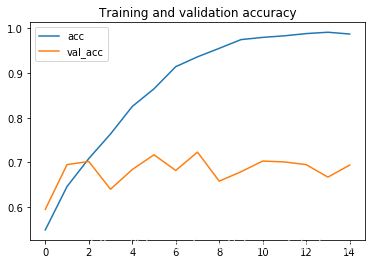
accuracy變化
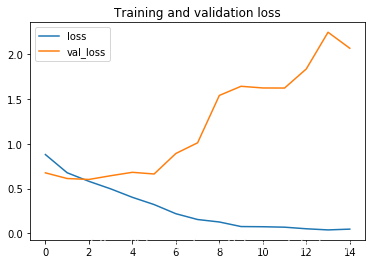
loss值變化
由于我們的訓練樣本數量相對較少,防止過度擬合應該是我們首要關注的問題。當訓練數據過少,模型學習無法推廣到新數據時,即當模型開始使用不相關的特征進行預測時,就會發生過度擬合。
感謝各位的閱讀,以上就是“怎么利用Tensorflow2進行貓狗分類識別”的內容了,經過本文的學習后,相信大家對怎么利用Tensorflow2進行貓狗分類識別這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





