溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前提:JDK1.8,無密互通,zookeeper,hadoop
使用服務器列表
| master | slave1 | slave2 |
|---|---|---|
| 192.168.3.58 | 192.168.3.54 | 192.168.3.31 |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| NameNode | ||
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| ResourceManager | ||
| NodeManager | NodeManager | NodeManager |
| DFSZKFailoverController | DFSZKFailoverController | |
| Master | ||
| Worker | Worker | Worker |
Scala是一門多范式的編程語言,一種類似java的編程語言[1] ,設計初衷是實現可伸縮的語言[2] 、并集成面向對象編程和函數式編程的各種特性。
官方下載地址:http://www.scala-lang.org/download/
下載
cd /data
wget https://downloads.lightbend.com/scala/2.12.4/scala-2.12.4.tgz
tar axf scala-2.12.4.tgz
添加環境變量
vim /etc/profile
#scala
export SCALA_HOME=/data/scala-2.12.4
export PATH=$PATH:${SCALA_HOME}/binsource /etc/profile
檢驗
scala -version
顯示版本信息說明安裝成功
官方說明:apache spark is a fast and general engine for large-scale data processing.
渣渣翻譯:spark是一個能夠快速處理并且通用的大數據計算引擎。
百度百科:Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。
繼續百度百科:
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
官網:http://spark.apache.org/
這里聽從了前輩的建議,使用較最新版本低一兩個版本的
cd /data
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.1.2/spark-2.1.2-bin-hadoop2.7.tgz
tar axf spark-2.1.2-bin-hadoop2.7.tgz
添加環境變量
vim /etc/profile
#spack
export SPARK_HOME=/data/spark-2.1.2-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/binsource /etc/profile
修改配置文件
cd ${SPARK_HOME}/conf
cp fairscheduler.xml.template fairscheduler.xml
cp log4j.properties.template log4j.properties
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-site.conf
vim slaves
#刪除localhost,添加worker節點信息
master
slave1
slave2vim spark-env.sh
#添加如下信息:JAVA_HOME、SCALA_HOME、SPARK_MASTER_IP、SPARK_WORKER_MEMORY、HADOOP_CONF_DIR
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/data/scala-2.12.4
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop/vim spark-site.conf
spark.master spark://master:7077將文件拷貝到其他節點
scp -r /data/scala-2.12.4 slave1:/data
scp -r /data/scala-2.12.4 slave2:/data
scp -r /data/spark-2.1.2-bin-hadoop2.7 slave1:/data
scp -r /data/spark-2.1.2-bin-hadoop2.7 slave2:/data
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
啟動集群
cd ${SPARK_HOME}/sbin
./start-all.sh
單節點啟動master
cd ${SPARK_HOME}/sbin
./start-master.sh
單節點啟動slave
./start-slave.sh
所有節點進行修改
修改spark-site.conf
vim spark-site.conf
spark.master spark://master:7077,slave1:7077,slave2:7077修改spark-env.sh指定zookeeper集群
vim spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/data/spark-2.1.2-bin-hadoop2.7"啟動集群
master節點
cd ${SPARK_HOME}/sbin
./start-all.sh
slave1節點
cd ${SPARK_HOME}/sbin
./start-master.sh
slave2節點
cd ${SPARK_HOME}/sbin
./start-master.sh
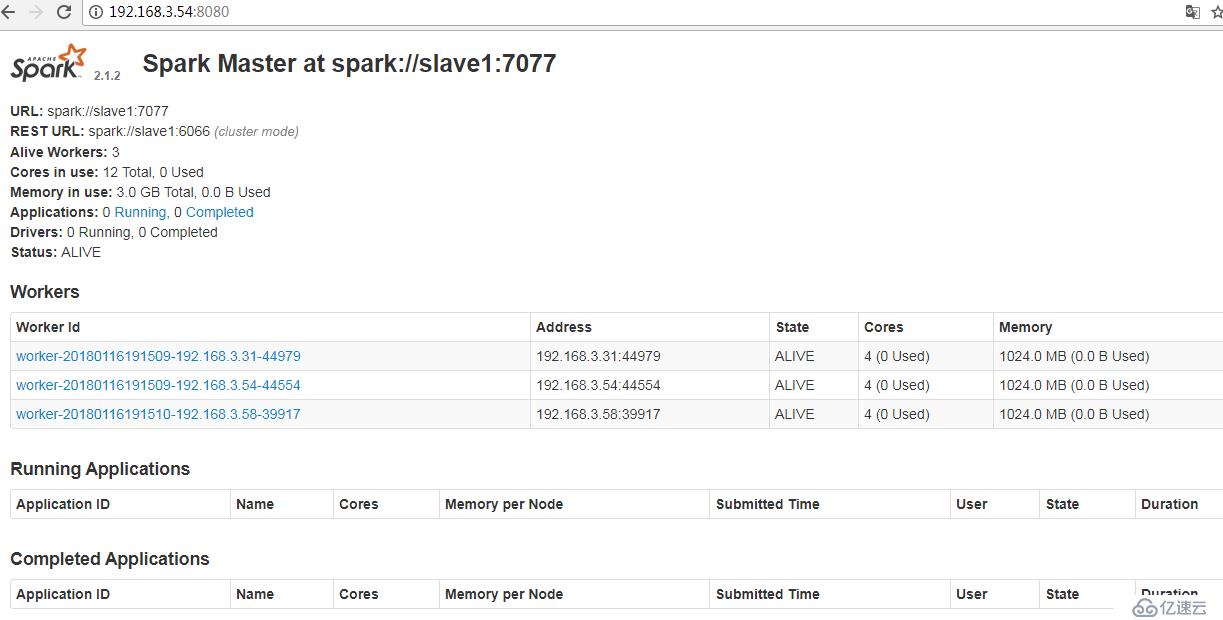
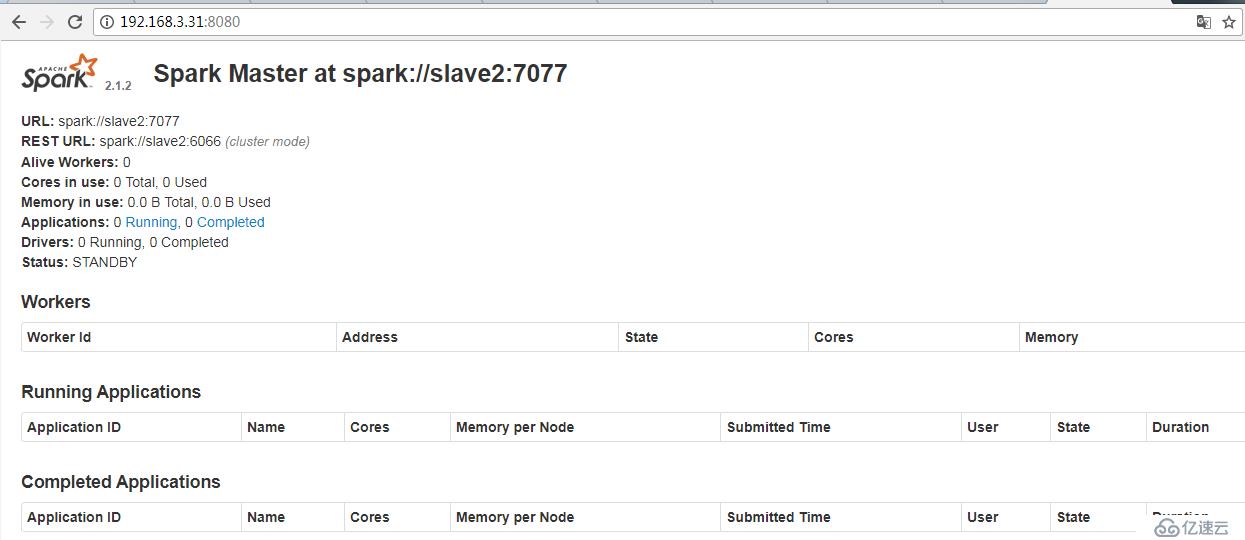
查看狀態
IP:8080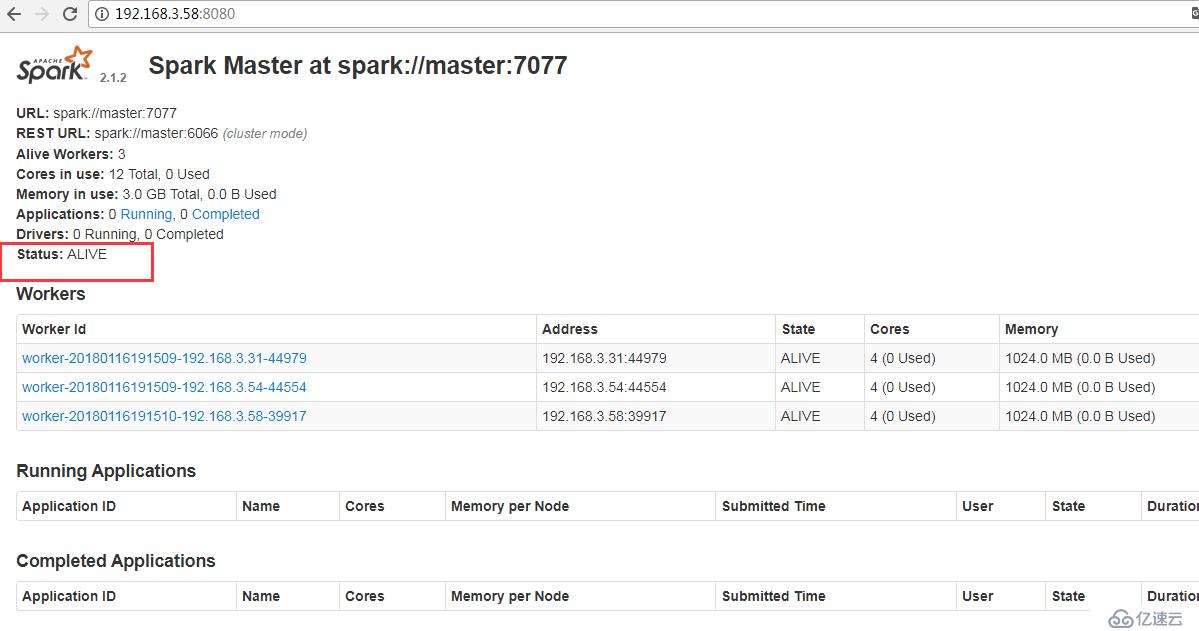
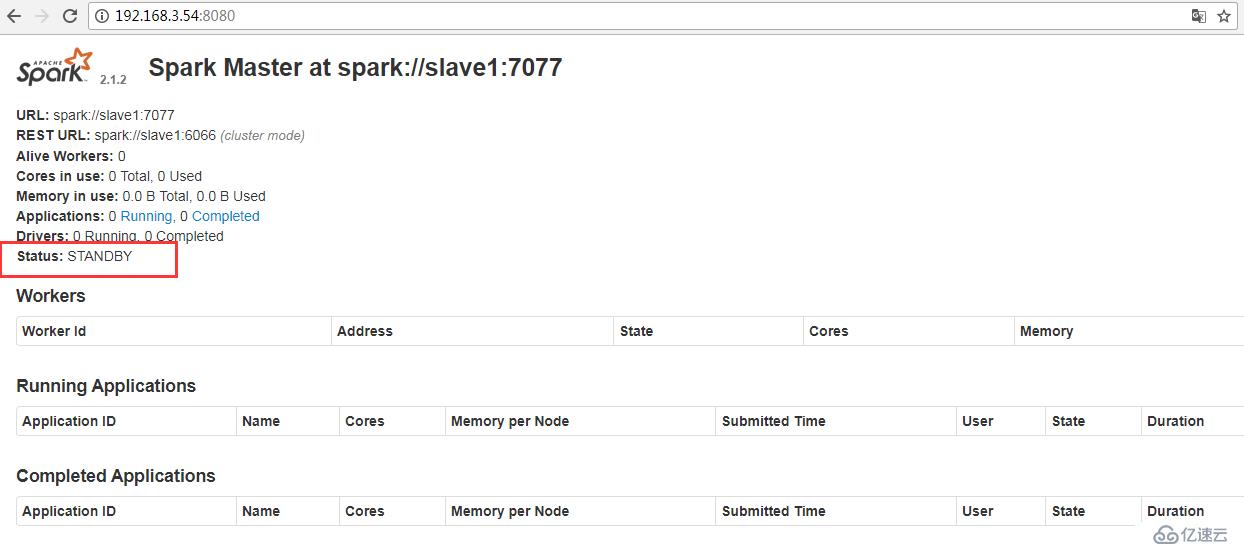
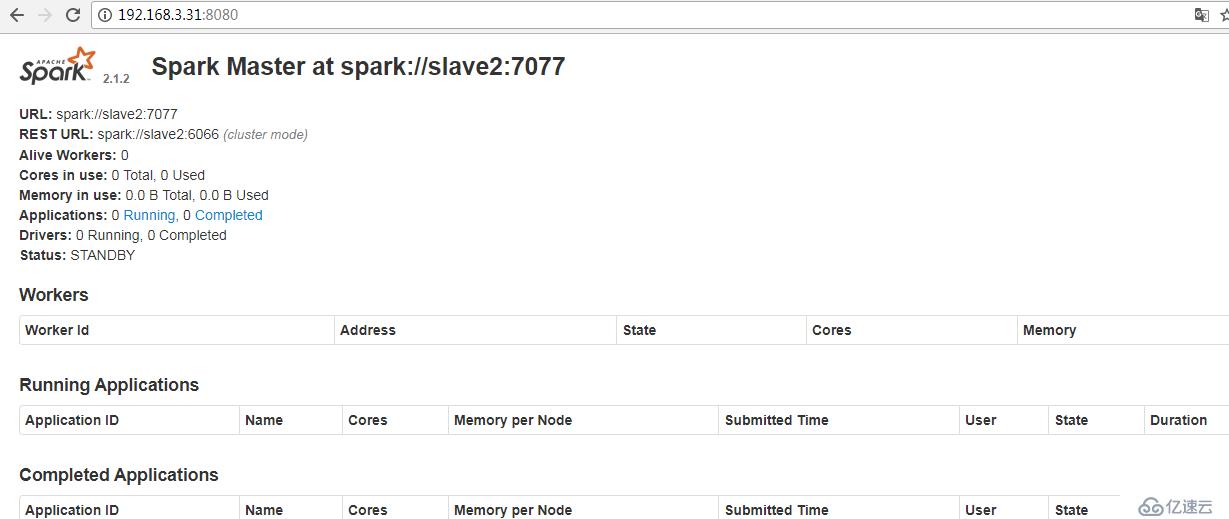
故障轉移測試
kill掉master上的Master進程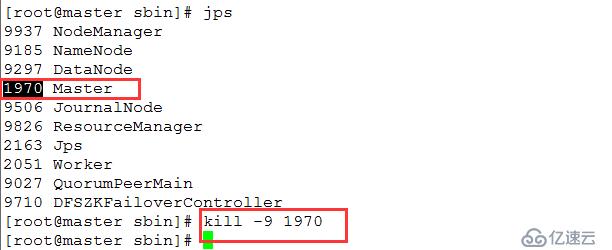
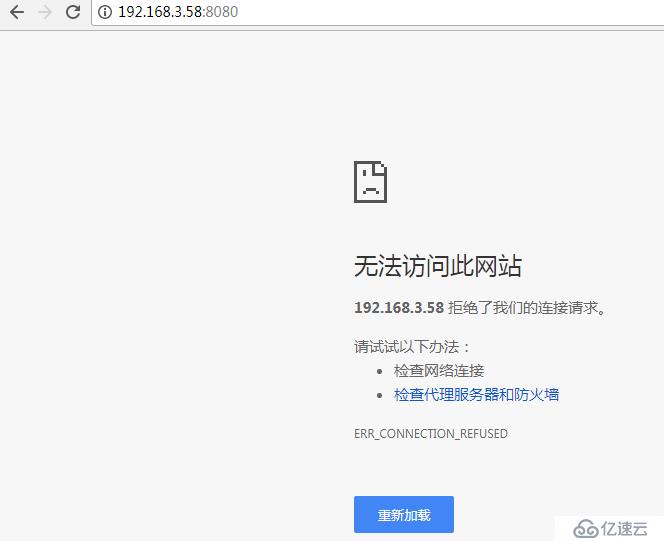
參考:https://www.cnblogs.com/liugh/p/6624923.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





