溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解TCP擁塞控制算法,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
?最近花了些時間在學習TCP/IP協議上,首要原因是由于本人長期以來對TCP/IP的認識就只限于三次握手四次分手上,所以希望深入了解一下。再者,TCP/IP和Linux系統層級的很多設計都可以用于中間件系統架構上,比如說TCP 擁塞控制算法也可以用在以響應時間來限流的中間件上。更深一層,像TCP/IP協議這種基礎知識和原理性的技術,都是經過長時間的考驗的,都是前人智慧的結晶,可以給大家很多啟示和幫助。
?文中會出現一些縮寫,因為篇幅問題,無法每個都進行解釋,如果你不明白它的含義,請自己去搜索了解,做一個主動尋求知識的人。
?TCP協議有兩個比較重要的控制算法,一個是流量控制,另一個就是阻塞控制。
?TCP協議通過滑動窗口來進行流量控制,它是控制發送方的發送速度從而使接受者來得及接收并處理。而擁塞控制作用于整體網絡,它是防止過多的包被發送到網絡中,避免出現網絡負載過大,網絡擁塞的情況。
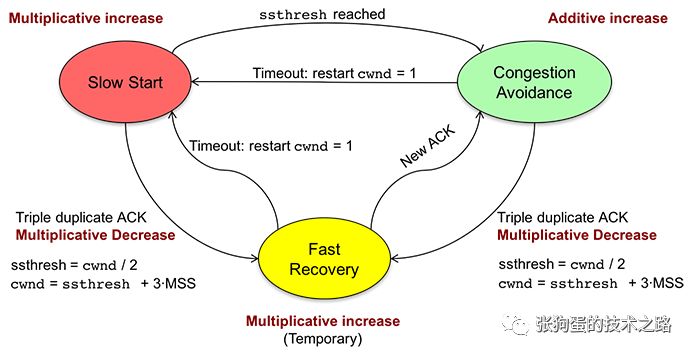
?擁塞算法需要掌握其狀態機和四種算法。擁塞控制狀態機的狀態有五種,分別是Open,Disorder,CWR,Recovery和Loss狀態。四個算法為慢啟動,擁塞避免,擁塞發生時算法和快速恢復。
?和TCP一樣,擁塞控制算法也有其狀態機。當發送方收到一個ACK時,Linux TCP通過狀態機的狀態來決定其接下來的行為,是應該降低擁塞窗口cwnd大小,或者保持cwnd不變,還是繼續增加cwnd。如果處理不當,可能會導致丟包或者超時。

?Open狀態是擁塞控制狀態機的默認狀態。這種狀態下,當ACK到達時,發送方根據擁塞窗口cwnd(Congestion Window)是小于還是大于慢啟動閾值ssthresh(slow start threshold),來按照慢啟動或者擁塞避免算法來調整擁塞窗口。
?當發送方檢測到DACK(重復確認)或者SACK(選擇性確認)時,狀態機將轉變為Disorder狀態。在此狀態下,發送方遵循飛行(in-flight)包守恒原則,即一個新包只有在一個老包離開網絡后才發送,也就是發送方收到老包的ACK后,才會再發送一個新包。
?發送方接收到一個顯示擁塞通知時,并不會立刻減少擁塞窗口cwnd,而是每收到兩個ACK就減少一個段,直到窗口的大小減半為止。當cwnd正在減小并且網絡中有沒有重傳包時,這個狀態就叫CWR(Congestion Window Reduced,擁塞窗口減少)狀態。CWR狀態可以轉變成Recovery或者Loss狀態。
?當發送方接收到足夠(推薦為三個)的DACK(重復確認)后,進入該狀態。在該狀態下,擁塞窗口cnwd每收到兩個ACK就減少一個段(segment),直到cwnd等于慢啟動閾值ssthresh,也就是剛進入Recover狀態時cwnd的一半大小。 ?發送方保持 Recovery 狀態直到所有進入 Recovery狀態時正在發送的數據段都成功地被確認,然后發送方恢復成Open狀態,重傳超時有可能中斷 Recovery 狀態,進入Loss狀態。
?當一個RTO(重傳超時時間)到期后,發送方進入Loss狀態。所有正在發送的數據標記為丟失,擁塞窗口cwnd設置為一個段(segment),發送方再次以慢啟動算法增大擁塞窗口cwnd。
?Loss 和 Recovery 狀態的區別是:Loss狀態下,擁塞窗口在發送方設置為一個段后增大,而 Recovery 狀態下,擁塞窗口只能被減小。Loss 狀態不能被其他的狀態中斷,因此,發送方只有在所有 Loss 開始時正在傳輸的數據都得到成功確認后,才能退到 Open 狀態。
?擁塞控制主要是四個算法:1)慢啟動,2)擁塞避免,3)擁塞發生,4)快速恢復。這四個算法不是一天都搞出來的,這個四算法的發展經歷了很多時間,到今天都還在優化中。
?所謂慢啟動,也就是TCP連接剛建立,一點一點地提速,試探一下網絡的承受能力,以免直接擾亂了網絡通道的秩序。
?慢啟動算法:
1) 連接建好的開始先初始化擁塞窗口cwnd大小為1,表明可以傳一個MSS大小的數據。 2) 每當收到一個ACK,cwnd大小加一,呈線性上升。 3) 每當過了一個往返延遲時間RTT(Round-Trip Time),cwnd大小直接翻倍,乘以2,呈指數讓升。 4) 還有一個ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入“擁塞避免算法”(后面會說這個算法)
?如同前邊說的,當擁塞窗口大小cwnd大于等于慢啟動閾值ssthresh后,就進入擁塞避免算法。算法如下:
1) 收到一個ACK,則cwnd = cwnd + 1 / cwnd 2) 每當過了一個往返延遲時間RTT,cwnd大小加一。
?過了慢啟動閾值后,擁塞避免算法可以避免窗口增長過快導致窗口擁塞,而是緩慢的增加調整到網絡的最佳值。
?一般來說,TCP擁塞控制默認認為網絡丟包是由于網絡擁塞導致的,所以一般的TCP擁塞控制算法以丟包為網絡進入擁塞狀態的信號。對于丟包有兩種判定方式,一種是超時重傳RTO[Retransmission Timeout]超時,另一個是收到三個重復確認ACK。
?超時重傳是TCP協議保證數據可靠性的一個重要機制,其原理是在發送一個數據以后就開啟一個計時器,在一定時間內如果沒有得到發送數據報的ACK報文,那么就重新發送數據,直到發送成功為止。
?但是如果發送端接收到3個以上的重復ACK,TCP就意識到數據發生丟失,需要重傳。這個機制不需要等到重傳定時器超時,所以叫做快速重傳,而快速重傳后沒有使用慢啟動算法,而是擁塞避免算法,所以這又叫做快速恢復算法。
?超時重傳RTO[Retransmission Timeout]超時,TCP會重傳數據包。TCP認為這種情況比較糟糕,反應也比較強烈:
由于發生丟包,將慢啟動閾值ssthresh設置為當前cwnd的一半,即ssthresh = cwnd / 2.
cwnd重置為1
進入慢啟動過程
?最為早期的TCP Tahoe算法就使用上述處理辦法,但是由于一丟包就一切重來,導致cwnd重置為1,十分不利于網絡數據的穩定傳遞。
?所以,TCP Reno算法進行了優化。當收到三個重復確認ACK時,TCP開啟快速重傳Fast Retransmit算法,而不用等到RTO超時再進行重傳:
cwnd大小縮小為當前的一半
ssthresh設置為縮小后的cwnd大小
然后進入快速恢復算法Fast Recovery。
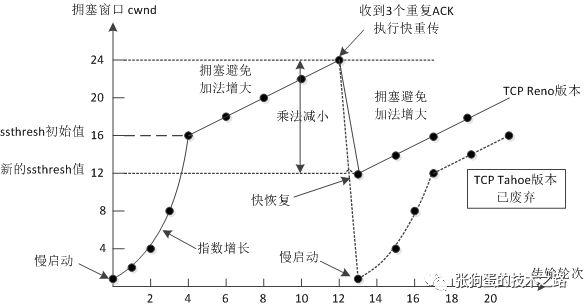
?TCP Tahoe是早期的算法,所以沒有快速恢復算法,而Reno算法有。在進入快速恢復之前,cwnd和ssthresh已經被更改為原有cwnd的一半。快速恢復算法的邏輯如下:
cwnd = cwnd + 3 * MSS,加3 * MSS的原因是因為收到3個重復的ACK。
重傳DACKs指定的數據包。
如果再收到DACKs,那么cwnd大小增加一。
如果收到新的ACK,表明重傳的包成功了,那么退出快速恢復算法。將cwnd設置為ssthresh,然后進入擁塞避免算法。
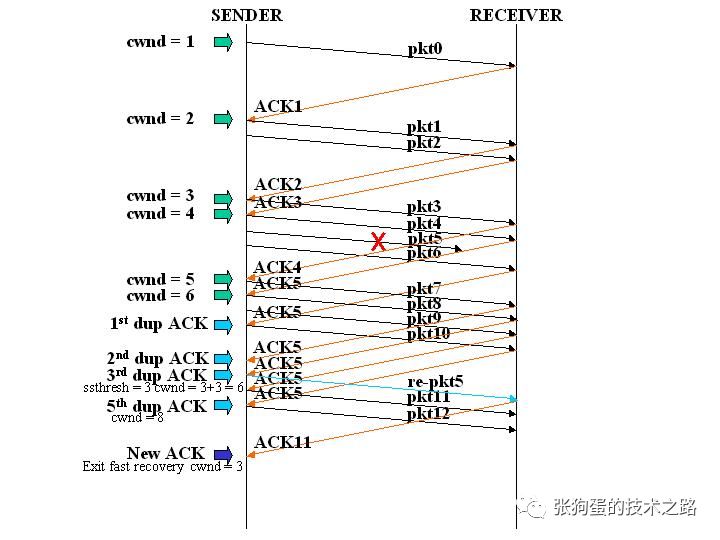
?如圖所示,第五個包發生了丟失,所以導致接收方接收到三次重復ACK,也就是ACK5。所以將ssthresh設置為當時cwnd的一半,也就是6/2 = 3,cwnd設置為3 + 3 = 6。然后重傳第五個包。當收到新的ACK時,也就是ACK11,則退出快速恢復階段,將cwnd重新設置為當前的ssthresh,也就是3,然后進入擁塞避免算法階段。
?本文為大家大致描述了TCP擁塞控制的一些機制,但是這些擁塞控制還是有很多缺陷和待優化的地方,業界也在不斷推出新的擁塞控制算法,比如說谷歌的BBR。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





