溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么理解TCP的SYN隊列和Accept隊列”,在日常操作中,相信很多人在怎么理解TCP的SYN隊列和Accept隊列問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么理解TCP的SYN隊列和Accept隊列”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
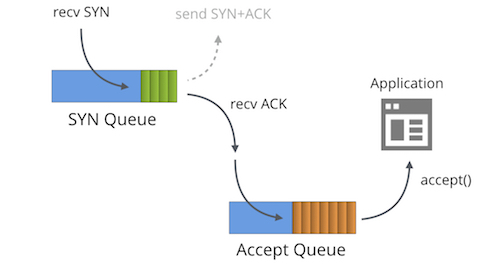
首先我們必須明白,處于“LISTENING”狀態的TCP socket,有兩個獨立的隊列:
SYN隊列(SYN Queue)
Accept隊列(Accept Queue)
這兩個術語有時也被稱為“reqsk_queue”,“ACK backlog”,“listen backlog”,甚至“TCP backlog”,但是這篇文章中我們使用上面兩個術語以免造成混淆。
<!-- more -->
SYN隊列存儲了收到SYN包的連接(對應內核代碼的結構體:struct inet_request_sock)。它的職責是回復SYN+ACK包,并且在沒有收到ACK包時重傳,直到超時。在Linux下,重傳的次數為:
$ sysctl net.ipv4.tcp_synack_retries net.ipv4.tcp_synack_retries = 5
文檔中對tcp_synack_retries的描述如下:
tcp_synack_retries - int整型 對于一個被動TCP連接,重傳SYNACKs的次數。該值不能超過255。 默認值為5,如果初始RTO是1秒,那么對應的最后一次重傳是31秒。 對應的最后一次超時是63秒之后。
發送完SYN+ACK之后,SYN隊列等待從客戶端發出的ACK包(也即三次握手的最后一個包)。當收到ACK包時,首先找到對應的SYN隊列,再在對應的SYN隊列中檢查相關的數據看是否匹配,如果匹配,內核將該連接相關的數據從SYN隊列中移除,創建一個完整的連接(對應內核代碼的結構體:struct inet_sock),并將這個連接加入Accept隊列。
Accept隊列中存放的是已建立好的連接,也即等待被上層應用程序取走的連接。當進程調用accept(),這個socket從隊列中取出,傳遞給上層應用程序。
這就是Linux處理SYN包的一個簡單描述。順便一提,當socket開啟了TCP_DEFER_ACCEPT和TCP_FASTOPEN時,工作方式將會有細微不同,本文不做介紹。
應用程序通過調用系統調用listen(2),傳入backlog參數,來設置SYN隊列和Accept隊列的最大大小。比如下面這樣,將SYN隊列和Accept隊列的最大大小同時設置為1024:
listen(sfd, 1024)
注意,在4.3版本之前的內核,SYN隊列的大小是用另一種方式計算。
SYN隊列的最大大小以前是用net.ipv4.tcp_max_syn_backlog來配置,但是現在已經不再使用了。現在用net.core.somaxconn來同時表示SYN隊列和Accept隊列的最大大小。在我們的服務器上,我們將它設置為16k:
$ sysctl net.core.somaxconn net.core.somaxconn = 16384
知道了上面這些信息后,你可能會問,隊列設置為多大合適?
答案是:看情況。對于大多數的TCP服務來說,這并不太重要。比如,Go語言1.11版本之前,并沒有提供設置隊列大小的方法。
盡管如此,也存在一些合理的原因,需要增大隊列的大小:
當建立連接的請求速度確實很大時,即使是對于一個高性能的服務來說,SYN隊列也可能需要設置的大一些。
SYN隊列的大小,換言之就是等待ACK包的連接數。也即與客戶端的平均往返時間越大,堆積在SYN隊列中的連接就越多。對于那些大部分客戶端都距離服務器很遠的場景,比如說往返時間幾百毫秒以上,可以將隊列大小設置的大一些。
TCP_DEFER_ACCEPT選項如果打開了,會導致socket在SYN-RECV狀態下維持更長的時間,也即增大了處于SYN隊列中的時間。
但是,將backlog設置的過大也會帶來不好的影響:
SYN隊列中的每一個槽位都需要占用一些內存。當遇到SYN Flood攻擊時,我們沒有必要為這些發起攻擊的包浪費資源。SYN隊列中的inet_request_sock結構體,在4.14內核下,每個將占用256字節的內存。
linux下,如果想查看SYN隊列的當前狀態,我們可以使用ss命令來查詢SYN-RECV狀態的socket。比如如下執行結果,表示80端口的SYN隊列中當前有119個元素,443端口則為78。
$ ss -n state syn-recv sport = :80 | wc -l 119 $ ss -n state syn-recv sport = :443 | wc -l 78
還可以通過我們的SystemTap腳本來觀察這個數據:resq.stp
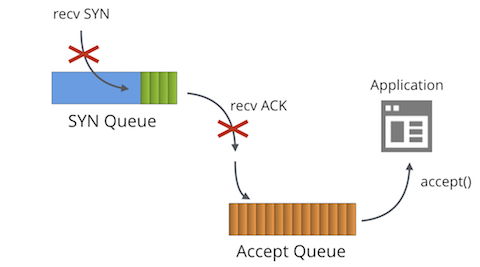
如果程序調用accept()不夠快會發生什么呢?
后續收到的SYN包,不會被SYN隊列處理
后續收到的(用于建立連接的)ACK包,不會被SYN隊列處理
TcpExtListenOverflows / LINUX_MIB_LISTENOVERFLOWS計數增加
TcpExtListenDrops / LINUX_MIB_LISTENDROPS計數增加
發生這種情況時,我們只能寄希望于程序的處理性能稍后能恢復正常,客戶端重新發送被服務端丟棄的包。
內核的這種表現對于大部分服務來說是可接受的。順便一提,可以通過調整net.ipv4.tcp_abort_on_overflow這個全局參數來修改這種表現,但是最好還是不要改這個參數。
可以通過查看nstat的計數來觀察Accept隊列溢出的狀態:
$ nstat -az TcpExtListenDrops TcpExtListenDrops 49199 0.0
但是這是一個全局的計數。觀察起來不夠直觀,比如有時我們觀察到它在增長,但是所有的服務程序看起來都是正常的。此時我們可以使用ss命令來觀察單個監聽端口的Accept隊列大小:
$ ss -plnt sport = :6443|cat State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 1024 *:6443 *:*
Recv-Q這一列顯示的是處于Accept隊列中的socket數量,Send-Q顯示的是隊列的最大大小。在上面的例子中,我們發現并沒有未被程序accept()的socket,但是我們依然發現ListenDrops計數在增長。
這是因為我們的程序只是周期性的短暫卡住不處理新的連接,而非永久性的不處理,過段時間程序又恢復了正常。這種情況下,用ss命令比較難觀察這種現象,因此我們寫了一個SystemTap腳本,它會hook進內核,把被丟棄的SYN包打印出來:
$ sudo stap -v acceptq.stp time (us) acceptq qmax local addr remote_addr 1495634198449075 1025 1024 0.0.0.0:6443 10.0.1.92:28585 1495634198449253 1025 1024 0.0.0.0:6443 10.0.1.92:50500 1495634198450062 1025 1024 0.0.0.0:6443 10.0.1.92:65434 ...
通過上面的操作,可以觀察到哪些SYN包被ListenDrops影響了。從而我們也就可以知道哪些程序在丟失連接。
到此,關于“怎么理解TCP的SYN隊列和Accept隊列”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





