溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Apache Flink 誤用的是示例分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
1. 項目開始
a) 從一個具有挑戰性的用例開始(端對端的 Exactly-once、大狀態、復雜的業務邏輯、強實時SLA的組合) b) 之前沒有流處理經驗 c) 不對團隊做相關的培訓 d) 不利用社區
郵件列表:
user@flink.apache.com/user-zh@flink.apache.org
Stack Overflow:
www.stackoverflow.com
2. 設計分析
a) 不考慮數據一致性和交付保證 b) 不考慮業務升級和應用改進 c) 不考慮業務規模問題 d) 不深入思考實際業務需求
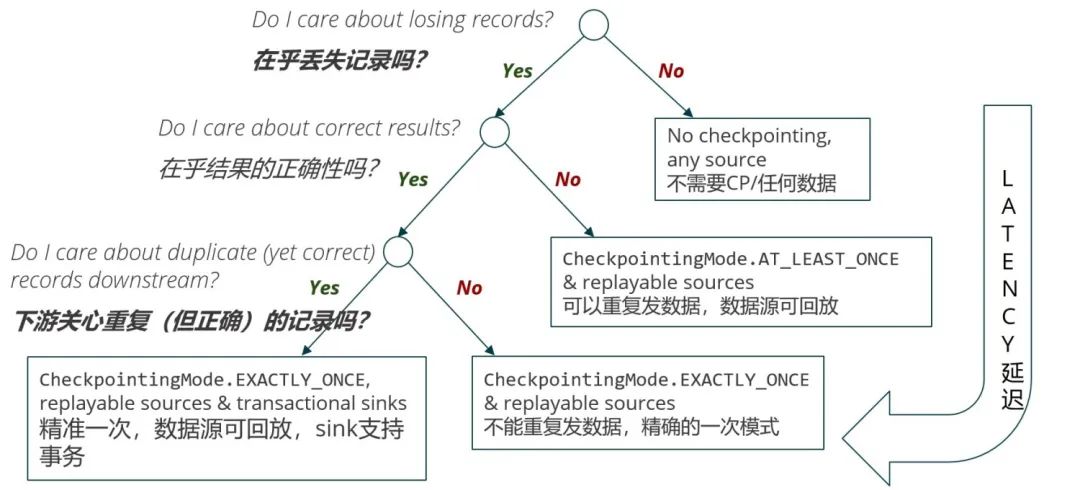
a 升級集群版本 b 業務 bug 的修復 c 業務邏輯(拓撲)的變更
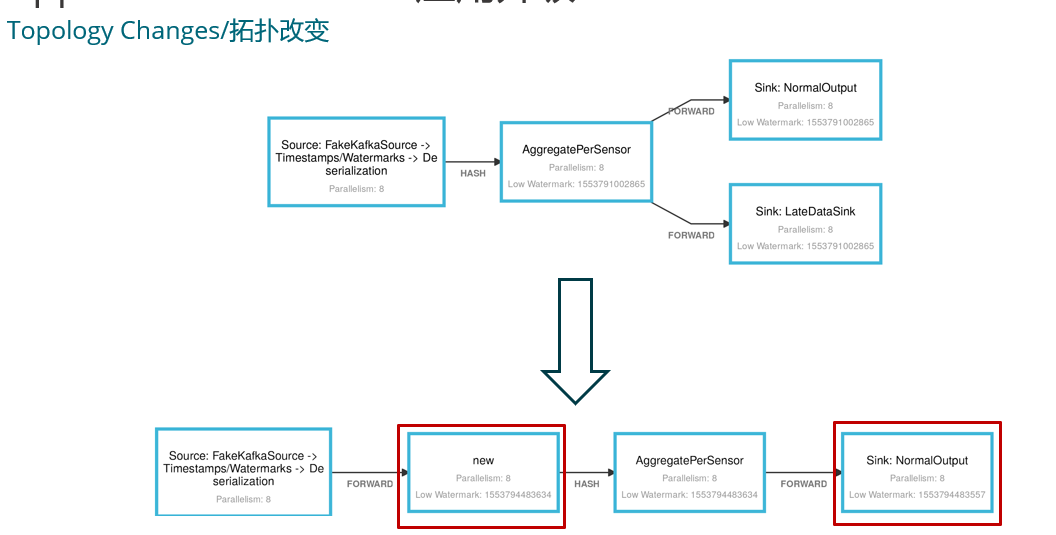
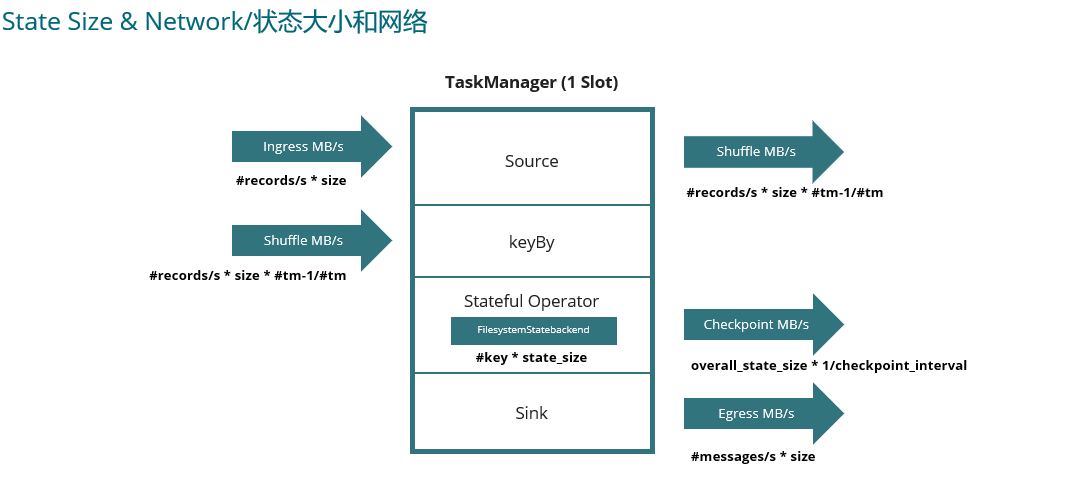
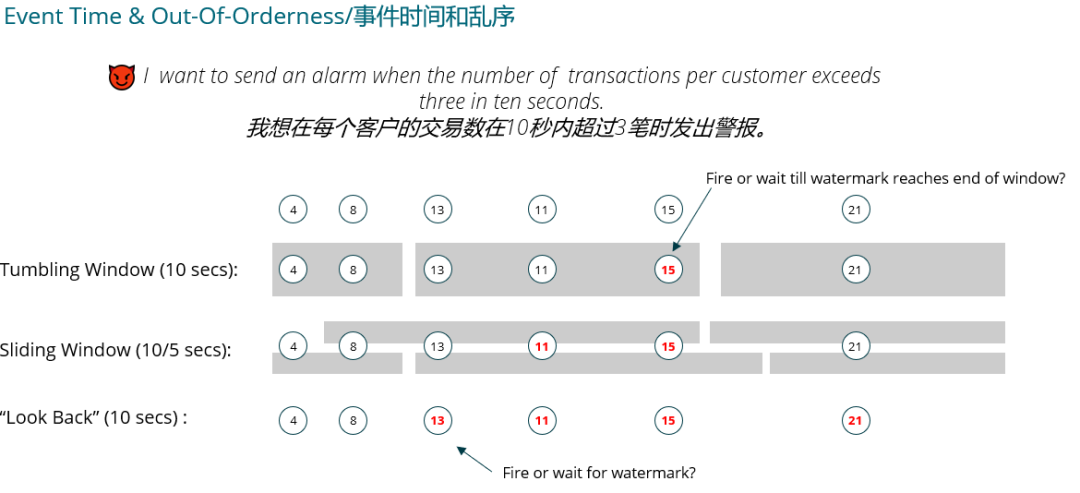
3. 開發
a) 在升級過程中要改變狀態 b) 不能丟失遲到的數據 c) 在運行時更改程序的行為
3.2 數據類型
3.3 序列化

3.4 并發性
任務之間共享靜態變量
在用戶函數中生成線程
3.5 窗口




4. 測試
5. 上線
6. 維護
7.PyFlink/SQL/TableAPI 的補充
使用 TableEnvironment 還是 StreamTableEnvironment?推薦 TableEnvironment 。(分段優化)
State TTL 未設置,導致 State 無限增長,或者 State TTL 設置不結合業務需求,導致數據正確性問題。
不支持作業升級,例如增加一個 COUNT SUM 會導致作業 state 不兼容。
解析 JSON 時,重復調度 UDF,嚴重影響性能,建議替換成 UDTF。
多流 JOIN 的時候,先做小表 JOIN,再做大表 JOIN。目前,Flink 還沒有表的 meta 信息,沒法在 plan 優化時自動做 join reorder。
關于Apache Flink 誤用的是示例分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





