溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎么分析Apache Flink框架,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Flink項目最早開始于2010年由柏林技術大學、柏林洪堡大學、哈索普拉特納研究所共同合作研發的"Stratosphere: Information Management on the Cloud"(平流層:云上的信息管理) 項目,Flink最開始是作為該項目一個分布式執行引擎的Fork,到2014年成為Apache基金會下的一個項目,2014年底成為Apache頂級項目。每年一次的Flink Forward是關于Apache Flink最盛大的年度會議。
Flink是原生的流處理系統,提供high level的API。Flink也提供 API來像Spark一樣進行批處理,但兩者處理的基礎是完全不同的。Flink把批處理當作流處理中的一種特殊情況。在Flink中,所有的數據都看作流,是一種很好的抽象,因為這更接近于現實世界。
cdn.nlark.com/lark/0/2018/png/108276/1542247457636-84d1bd8c-ad12-4c67-99a2-9cfde822141f.png">
Flink的基本架構圖
Flink 的主要架構與Spark接近,都基于Master-Slave 的主從模式,從執行順序上講:
1:集群啟動,啟動JobManager 和多個TaskManager;
2:Flink Program程序提交代碼,經由優化器/任務圖生成器,生成實際需執行的Job,傳遞至Client;
3:Client將submit提交任務(本質上是發送包含了任務信息的數據流)至JobManager;
4:JobManager分發任務到各個真正執行計算任務的Worker----TaskManager;
5:TaskManager開始執行計算任務,并且定時匯報心跳信息和統計信息給JobManager,TaskManager之間則以流的形式進行數據傳輸;
在以上步驟中,步驟2與Flink集群之間可以不存在歸屬關系,即我們可以在任何機器上提交作業,只要它與JobManager相通。Job提交之后,Client甚至可以直接結束進程,都不會影響任務在分布式集群的執行。
當用戶提交一個Flink程序時,會首先創建一個Client,該Client首先會對用戶提交的Flink程序進行預處理,并提交到Flink集群中處理,所以Client需要從用戶提交的Flink程序配置中獲取JobManager的地址,并建立到JobManager的連接,將Flink Job提交給JobManager。Client會將用戶提交的Flink程序組裝一個JobGraph, 并且是以JobGraph的形式提交的。一個JobGraph是一個Flink Dataflow,它由多個JobVertex組成的DAG。所以,一個JobGraph包含了一個Flink程序的如下信息:JobID、Job名稱、配置信息、一組JobVertex(實際的任務operators)等。
JobManager:
JobManager是Flink系統的協調者,它負責接收Flink Job,調度組成Job的多個Task的執行。同時,JobManager還負責收集Job的狀態信息,并管理Flink集群中從節點TaskManager。主要包括:
RegisterTaskManager——在Flink集群啟動的時候,TaskManager會向JobManager注冊,如果注冊成功,則JobManager會向TaskManager回復消息AcknowledgeRegistration;
SubmitJob——Flink程序內部通過Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息;
CancelJob——請求取消一個Flink Job的執行,CancelJob消息中包含了Job的ID,如果成功則返回消息CancellationSuccess,失敗則返回消息CancellationFailure;
UpdateTaskExecutionState——TaskManager會向JobManager請求更新ExecutionGraph中的ExecutionVertex的狀態信息,即向JobManager匯報operator具體的執行狀態,更新成功則返回true;
其他還包括RequestNextInputSplit、JobStatusChanged;
TaskManager也是一個Actor(掌管者),它是實際負責執行計算的Worker,在其上執行Flink Job的一組Task。它在啟動的時候就設置好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為線程。TaskManager從 JobManager 處接收需要部署的 Task,部署啟動后,與自己的上游(任務上存在依賴關系的上游處理節點)建立 Netty 連接,接收數據并處理。每個TaskManager負責管理其所在節點上的資源信息,如內存、磁盤、網絡,在啟動的時候將資源的狀態向JobManager匯報。
TaskManager端可以分成兩個階段:
注冊階段——TaskManager會向JobManager注冊,發送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然后TaskManager就可以進行初始化過程;
可操作階段——該階段TaskManager可以接收并處理與Task有關的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager無法連接到JobManager,這是TaskManager就失去了與JobManager的聯系,會自動進入“注冊階段”,只有完成注冊才能繼續處理Task相關的消息。
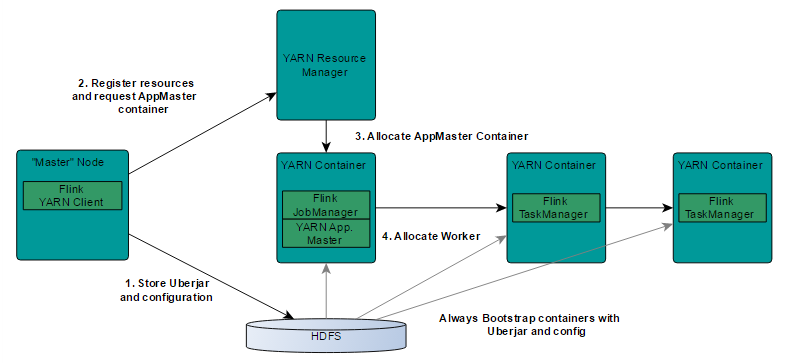
1: Clinet 客戶端上傳包含Flink和HDFS配置的jars至HDFS,因為YARN客戶端需要訪問Hadoop的配置以連接YARN資源管理器和HDFS;2: Clinet客戶端請求一個YARN容器作為資源管理器-Resource Manager,作用是啟動ApplicationMaster;
3: RM分配第一個container去運行AM--AppplicationMaster;
4: AM啟動,開始負責資源的監督和管理;
5: Job Manager和AM運行在同一個容器里,都成功啟動后,AM知道job管理器(它擁有的主機)的地址;
6: Job Manager為Task Manager生成一個新的Flink配置, 這樣task可連接Job Manager;
7: AM容器可以作為Flink的web接口服務,YARN代碼的所有端口是分配的臨時端口, 這可讓用戶并行執行多個yarn會話;
8: AM啟動分配到的容器,這些容器作為Flink的Task Manager,將會從HDFS下載jar和更新配置,集群Run,可接收Job;
在Flink的基本架構圖中,我們發現這一Master-Slave模式存在單點問題,即:JobManager這個點萬一down掉,整個集群也就全完了。Flink一共提供了三種部署模式:Local、Standalone、YARN,除第一種為本地單機模式外,后兩者都為集群模式。對于Standalone和YARN,Flink提供了HA機制避免上述單點失敗問題,使得集群能夠從失敗中恢復。
YARN模式:
上段中介紹到Yarn層面的機構,注意到Flink的JobManager與YARN的Application Master(簡稱AM)是在同一個進程下的。YARN的ResourceManager對AM有監控,當AM異常時,YARN會將AM重新啟動,啟動后,所有JobManager的元數據從HDFS恢復。但恢復期間,舊的業務不能運行,新的業務不能提交。ZooKeeper( Apache ZooKeeper?)上還是存有JobManager的元數據,比如運行Job的信息,會提供給新的JobManager使用。對于TaskManager的失敗,由JobManager上Akka的DeathWatch機制監聽處理。當TaskManager失敗后,重新向YARN申請容器,創建TaskManager。
Standalone模式:
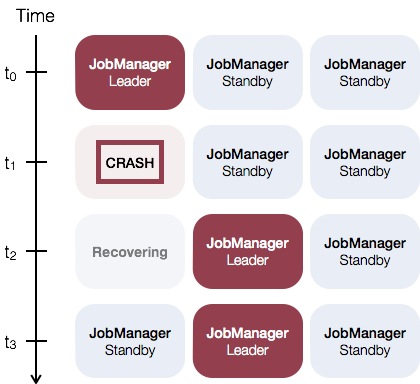
對于Standalone模式的集群,可以啟動多個JobManager,然后通過ZooKeeper選舉出leader作為實際使用的JobManager。該模式下可以配置一個主JobManager(Leader JobManager)和多個備JobManager(Standby JobManager),這能夠保證當主JobManager失敗后,備的某個JobManager可以承擔主的職責。下圖為主備JobManager的恢復過程。
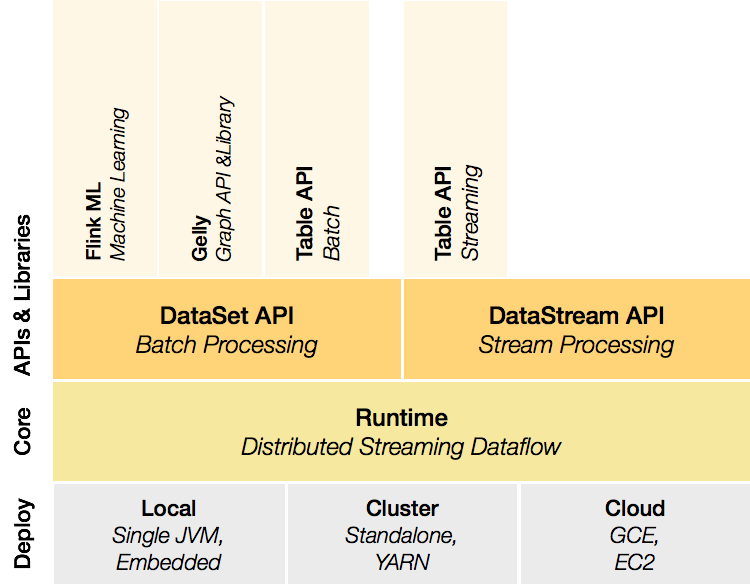
Deployment層:
本地、集群,以及商用的云模式,不再贅述;
runtime層:
Runtime層提供了支持Flink計算的全部核心實現,比如:支持分布式Stream處理、JobGraph到ExecutionGraph的映射、調度等等,為上層API層提供基礎服務;
API層:
API層主要實現了面向無界Stream的流處理和面向Batch的批處理API,其中面向流處理對應DataStream API,面向批處理對應DataSet API. 簡單來說,DataSet和DataStream都是包含了重復項數據的immutable集合,不同的是,在DataSet里,數據是有限的,而對于DataStream,元素的數量可以是無限的。對程序而言,最初的數據集合來源是Flink program 中的源數據,如雙11支付數據大屏的線上實時數據來源;然后通過filter、map、flatmap等API,可以對它們進行轉換,從而由初始數據集合派生出新集合。注意,集合是immutable的,只可派生出新的,不能修改原有的;
Libraries層:
Flink應用框架層,根據API層的劃分,在API層之上構建的滿足特定應用的實現計算框架,也分別對應于面向流處理和面向批處理兩類。面向流處理支持:CEP(復雜事件處理)、基于SQL-like的操作(基于Table的關系操作);面向批處理支持:FlinkML(機器學習庫)、Gelly(圖處理)。
簡單來說,Flink在流式計算上相比于Spark Streaming & Storm,突出的優勢主要是高吞吐&低延遲,如下圖所示:
Flink 支持了流處理和 Event Time 語義的窗口機制。 在討論解決消息亂序問題之前,需先定義時間和順序。在流處理中,時間的概念有兩個:
Event time :Event time是事件發生的時間,經常以時間戳表示,并和數據一起發送。帶時間戳的數據流有,Web服務日志、監控agent的日志、移動端日志等;
Processing time :Processing time是處理事件數據的服務器時間,一般是運行流處理應用的服務器時鐘。
許多流處理場景中,事件發生的時間和事件到達待處理的消息隊列時間有各種延遲:
各種網絡延遲;
數據流消費者導致的隊列阻塞和反壓影響;
數據流毛刺,即,數據波動;
事件生產者(移動設備、傳感器等)離線;
上述諸多原因會導致隊列中的消息頻繁亂序。事件發生的時間和事件到達待處理的消息隊列時間的不同隨著時間在不斷變化,這常被稱為時間偏移( event time skew),表示成: “processing time – event time”。
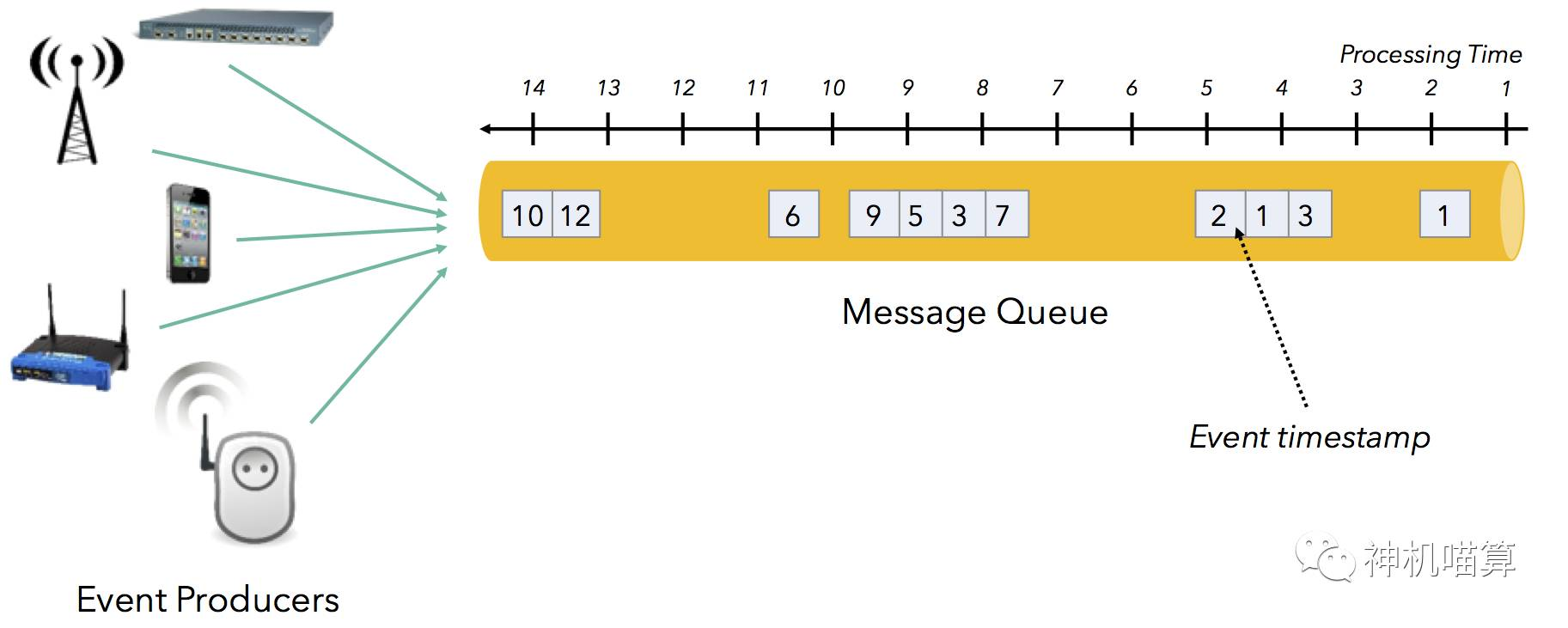
對大部分應用來講,基于事件的創建時間分析數據比基于事件的處理時間分析數據要更有意義。Flink允許用戶定義基于事件時間(event time)的窗口,而不是處理時間。
Flink使用 事件時間 clock來跟蹤事件時間,其是以 watermarks來實現的。 watermarks是Flink 源流基于事件時間點生成的特殊事件。 T 時間點的 watermarks意味著,小于 T 的時間戳的事件不會再到達。Flink的所有操作都基于 watermarks來跟蹤事件時間。
流程序可以在計算過程中維護自定義狀態。
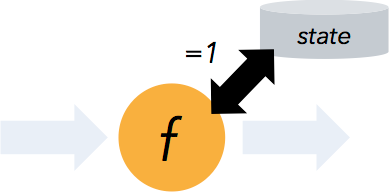
Apache Flink 提供了可以恢復數據流應用到一致狀態的容錯機制。確保在發生故障時,程序的每條記錄只會作用于狀態一次(exactly-once),不過也可以降級為至少一次(at-least-once)。這一容錯機制通過持續創建分布式數據流的快照來實現。對于狀態占用空間小的流應用,這些快照非常輕量,可以高頻率創建而對性能影響很小。流計算應用的狀態保存在一個可配置的環境,如:master 節點或者 HDFS上。
在遇到程序故障時(如機器、網絡、軟件等故障),Flink 停止分布式數據流。系統重啟所有 operator ,重置其到最近成功的 checkpoint。輸入重置到相應的狀態快照位置。保證被重啟的并行數據流中處理的任何一個 record 都不是 checkpoint 狀態之前的一部分。
為了能保證容錯機制生效,數據源(例如消息隊列或者broker)需要能重放數據流。Apache Kafka 有這個特性,Flink 中 Kafka 的 connector 利用了這個功能。集團的TT系統也有同樣功能。
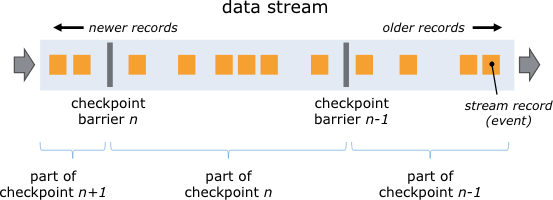
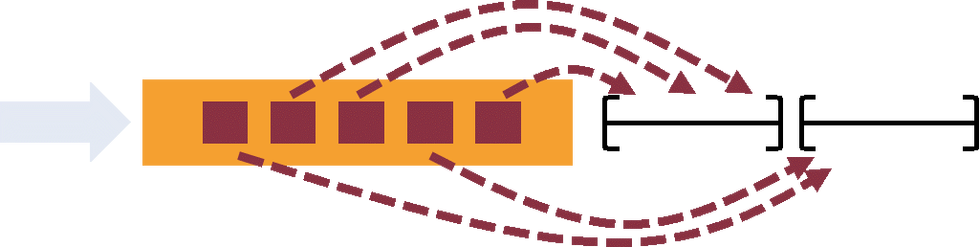
Flink 分布式快照的核心概念之一就是數據柵欄(barrier)。如上圖所示,這些 barrier 被插入到數據流中,作為數據流的一部分和數據一起向下流動。Barrier 不會干擾正常數據,數據流嚴格有序。一個 barrier 把數據流分割成兩部分:一部分進入到當前快照,另一部分進入下一個快照。每一個 barrier 都帶有快照 ID,并且 barrier 之前的數據都進入了此快照。Barrier 不會干擾數據流處理,所以非常輕量。多個不同快照的多個 barrier 會在流中同時出現,即多個快照可能同時創建。
Barrier 在數據源端插入,當 snapshot N 的 barrier 插入后,系統會記錄當前 snapshot 位置值N (用Sn表示)。例如,在 Apache Kafka 中,這個變量表示某個分區中最后一條數據的偏移量。這個位置值 Sn 會被發送到一個稱為 Checkpoint Coordinator 的模塊(即 Flink 的 JobManager).
然后 barrier 繼續往下流動,當一個 operator 從其輸入流接收到所有標識 snapshot N 的 barrier 時,它會向其所有輸出流插入一個標識 snapshot N 的 barrier。當 sink operator(DAG 流的終點)從其輸入流接收到所有 barrier N 時,它向Checkpoint Coordinator 確認 snapshot N 已完成。當所有 sink 都確認了這個快照,快照就被標識為完成。
Flink支持在時間窗口,統計窗口,session 窗口,以及數據驅動的窗口,窗口(Window)可以通過靈活的觸發條件來定制,以支持復雜的流計算模式。
來自云邪的描述 ——:“在流處理應用中,數據是連續不斷的,因此我們不可能等到所有數據都到了才開始處理。當然我們可以每來一個消息就處理一次,但是有時我們需要做一些聚合類的處理,例如:在過去的1分鐘內有多少用戶點擊了我們的網頁。在這種情況下,我們必須定義一個窗口,用來收集最近一分鐘內的數據,并對這個窗口內的數據進行計算。”
窗口可以是時間驅動的(Time Window,例如:每30秒鐘),也可以是數據驅動的(Count Window,例如:每一百個元素)。一種經典的窗口分類可以分成:翻滾窗口(Tumbling Window),滾動窗口(Sliding Window),和會話窗口(Session Window)。
數據流應用執行的是不間斷的(常駐)operators。
Flink streaming 在運行時有著天然的流控:慢的數據 sink 節點會反壓(backpressure)快的數據源(sources)。

反壓通常產生于這樣的場景:短時負載高峰導致系統接收數據的速率遠高于它處理數據的速率。許多日常問題都會導致反壓,例如,垃圾回收停頓可能會導致流入的數據快速堆積,或者遇到大促或秒殺活動導致流量陡增。反壓如果不能得到正確的處理,可能會導致資源耗盡甚至系統崩潰。
Flink的反壓:
如果你看到一個task的back pressure告警(比如,high),這意味著生產數據比下游操作算子消費的速度快。Record的在你工作流的傳輸方向是向下游,比如從source到sink,而back pressure正好是沿著反方向,往上游傳播。
舉個簡單的例子,一個工作流,只有source到sink兩個步驟。假如你看到source端有個告警,這意味著sink消費數據速率慢于生產者的生產數據速率。Sink正在向上游進行back pressure。
絕妙的是,在Spark Streaming和Storm是棘手問題的BackPressure,在Flink中并不成問題。簡單來說,Flink無需進行反壓,因為 系統接收數據的速率和處理數據的速率是自然匹配的。系統接收數據的前提是接收數據的Task必須有空閑可用的Buffer,該數據被繼續處理的前提是下游Task也有空閑可用的Buffer。因此,不存在系統接受了過多的數據,導致超過了系統處理的能力。這有點像Java線程中的通用阻塞隊列: 一個較慢的接受者會降低發送者的發送速率,因為一旦隊列滿了(有界隊列)發送者會被阻塞。
看完上述內容,你們對怎么分析Apache Flink框架有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





