溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“R語言和Python中常見的排序函數應用”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“R語言和Python中常見的排序函數應用”吧!
排序可能是日常數據清洗過程中比較高頻的應用了,今天這一篇給大家介紹R語言和Python中最為常見的排序函數應用。
R語言:
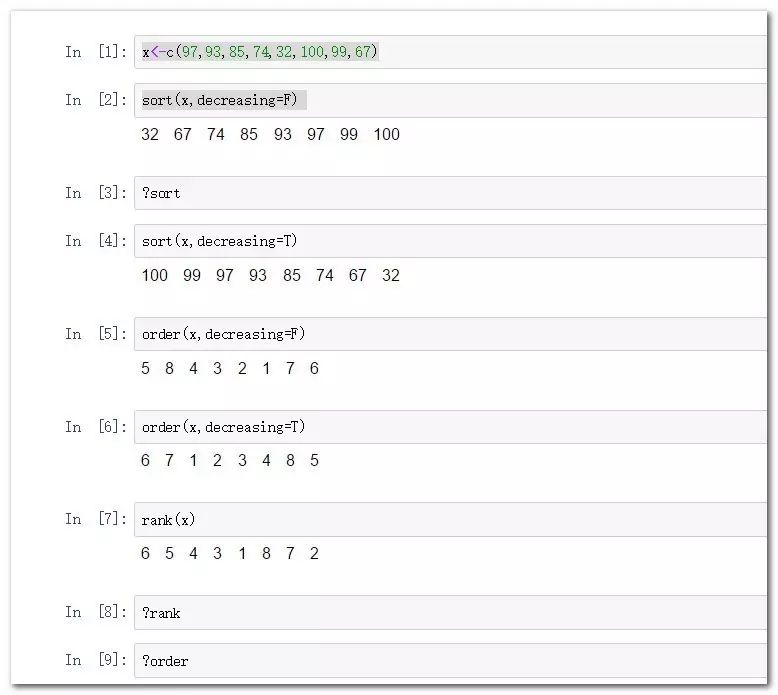
sort
order
rank
arrange
排序根據對向量排序和數據框的排序要使用不同的函數,以上四個函數中,前三個是針對向量的,最后一個是針對數據框的。
sort
x<-c(97,93,85,74,32,100,99,67)
sort(x,decreasing=F) #默認是生序排列,其中decreasing參數默認為FALSE。
sort(x,decreasing=T) #降序排列
order
order(x,decreasing=F) #變量由小到大在原始數據中的位次(默認升序可無需邏輯參數)
order(x,decreasing=T) #按照由大到小的順序對應元素在原始向量中的微詞。
rank:
#rank函數返回向量的秩,即對應元素在原始向量中排名。
rank(x)
基于數據框自身的排序:
當針對數據框進行排序時,如同對數據框進行條件索引一樣,也可以基于數據框自身的方法來實現。
(mydata<-data.frame(name=LETTERS[1:10],class=sample(letters[1:4],10,replace=TRUE),value=runif(10,0,5)))
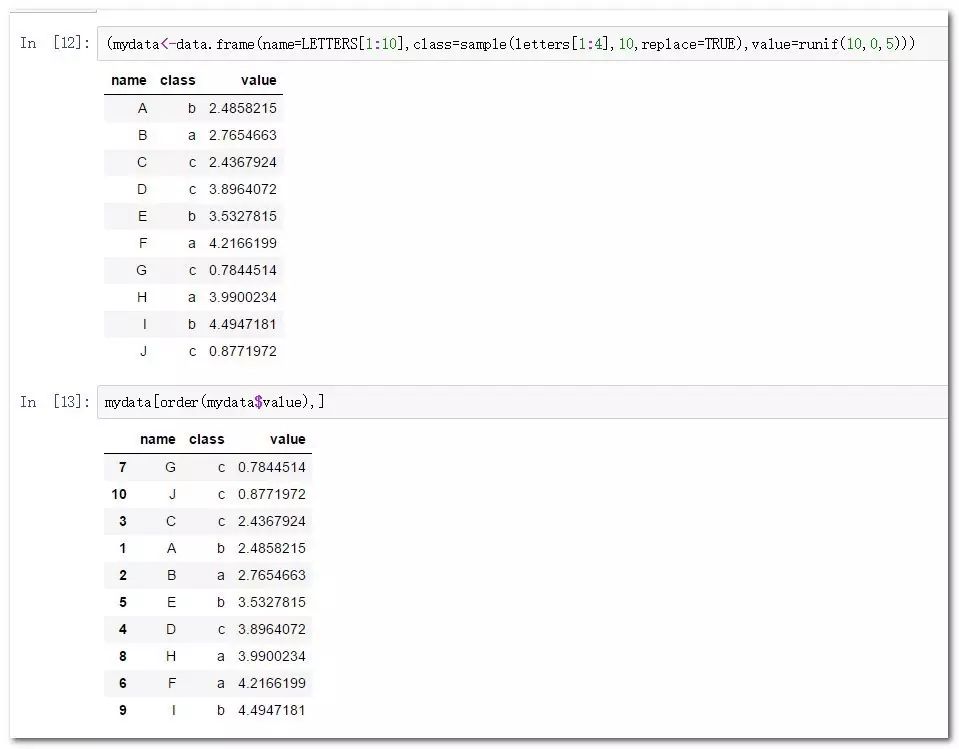
mydata[order(mydata$value),] #默認生序排列
mydata[order(mydata$value,decreasing=T),] #根據value降序排列
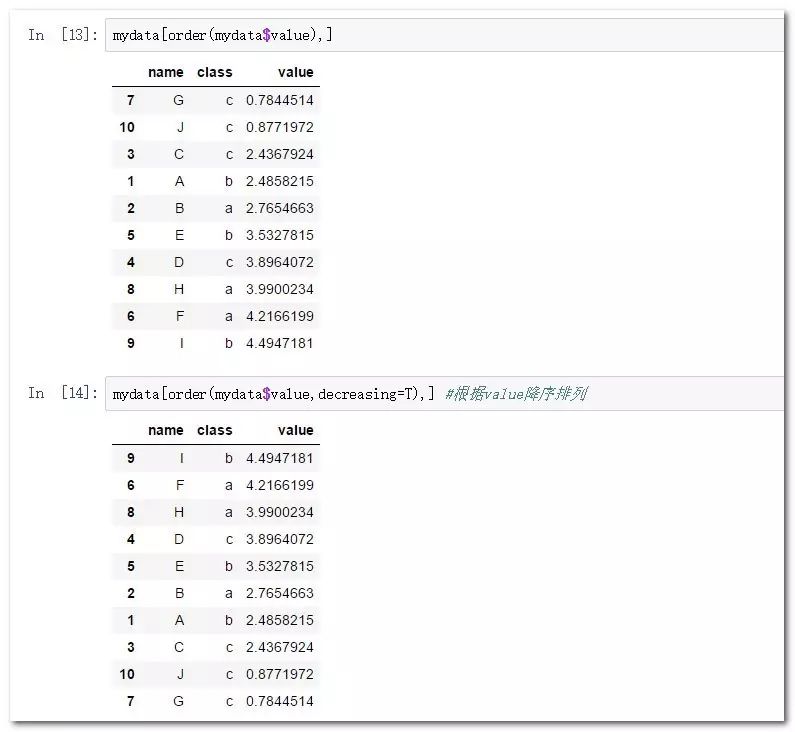
以上這種方式通過基于數據框自身的規則,完成了排序工作(實際上是一種布爾索引),但是不夠優雅,寫了繁瑣的變量名,而且只能根據一個字段來排序。
數據框排序-arrange
arrange函數的存在實在是R語言排序大殺器。
library(dplyr)
mydata%>%plyr::arrange(class,value)
mydata%>%plyr::arrange(class,-value)
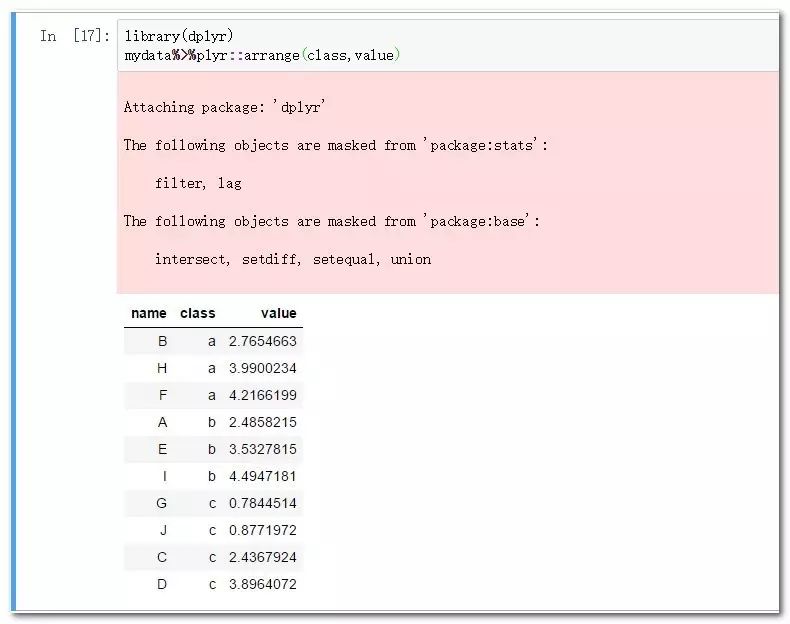
arrange函數不僅可以實現多變量規則排序,而且可以僅以負號指定降序,語法簡潔,功能強大,其中多變量時,一般是分類變量在前,連續變量在后,粒度粗的維度排在最前面,分類變量排序粒度依次遞減。最后是連續變量。
-------------
Python:
-------------
sort
sorted
.sort_index
.sort_value
列表排序方法:
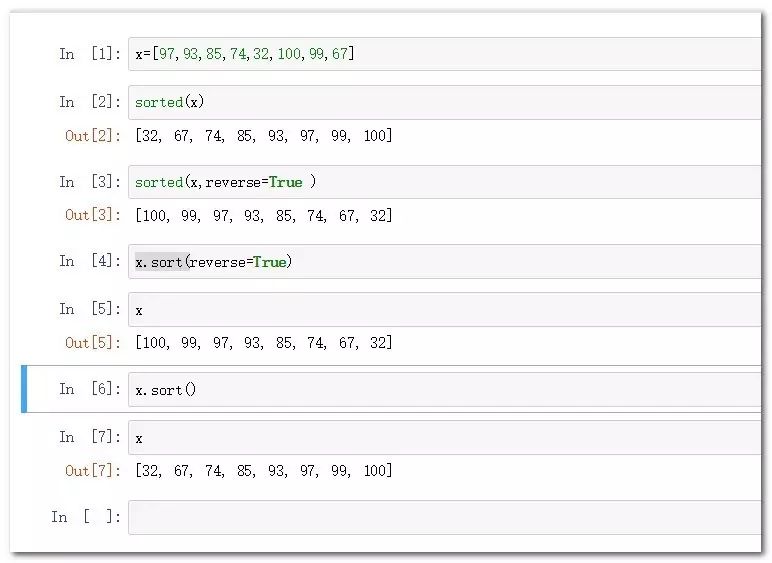
x=[97,93,85,74,32,100,99,67]
針對list的排序,Python提供有全局的sorted函數以及list自身的sort函數可以完成排序功能。
sorted(x) #默認生序
sorted(x,reverse=True) #指定降序
x.sort() #默認生序
x.sort(reverse=True) #指定降序
字典排序方法:
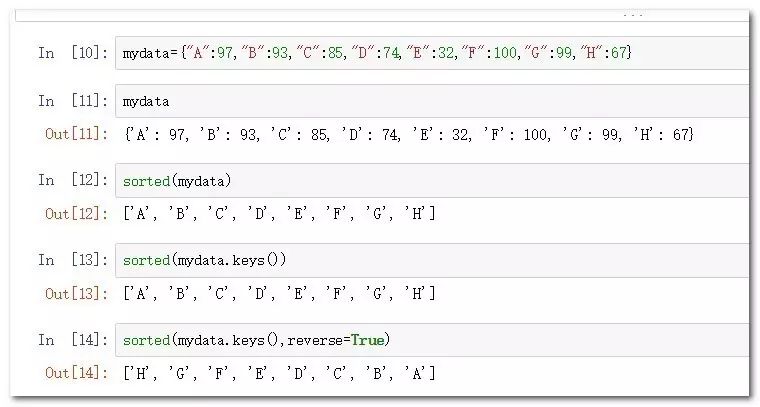
mydata={"A":97,"B":93,"C":85,"D":74,"E":32,"F":100,"G":99,"H":67}
sorted(mydata.keys()) #根據字典的鍵排序
sorted(mydata.keys(),reverse=True) #根據字典的鍵逆排序
排序時按照鍵值對:
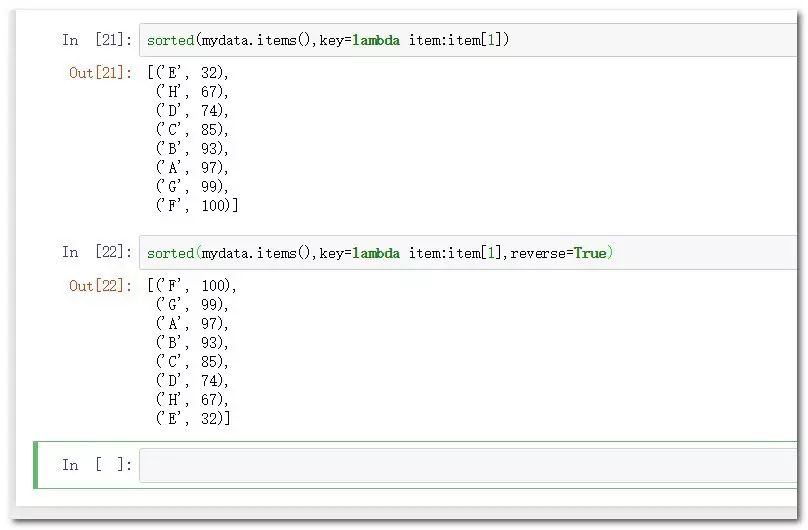
sorted(mydata.items(),key=lambda item:item[1]) #根據值字段生序排列
sorted(mydata.items(),key=lambda item:item[1],reverse=True) #根據值字段逆序排列
數據框排序:
import pandas as pd
import numpy as np
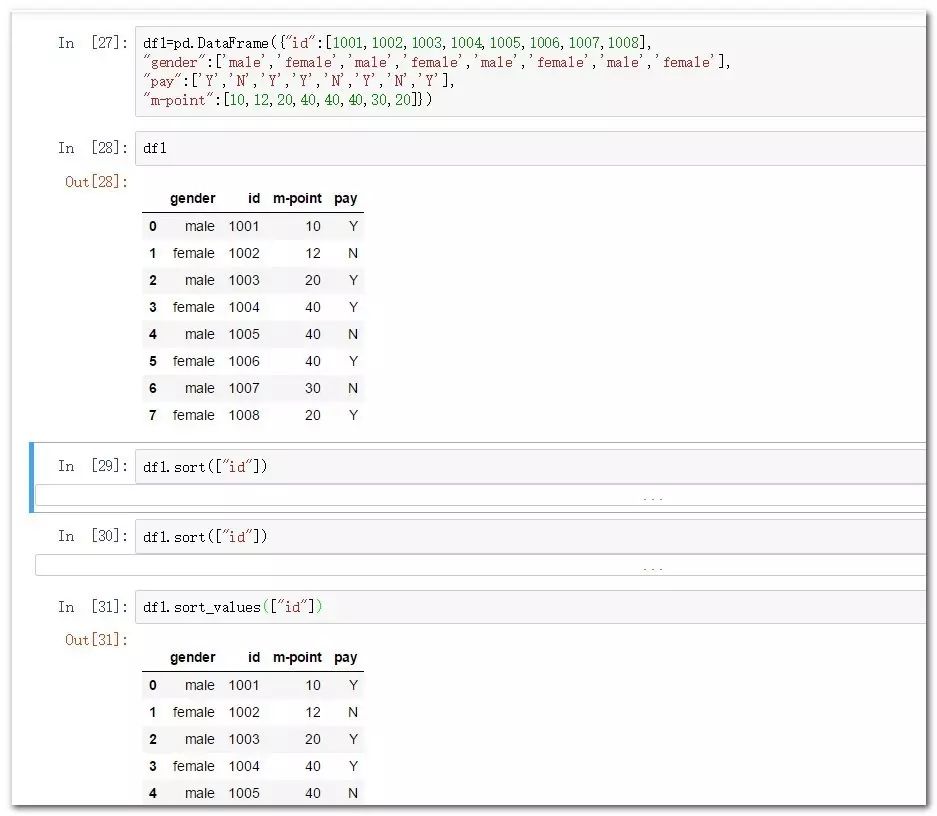
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y'],
"m-point":[10,12,20,40,40,40,30,20]})
pandas所生成的數據框同樣有sort方法。
根據值排序:
df1.sort_values(["id"]) #使用值進行排序
df1.sort_values(["id"],ascending=False) #降序排列
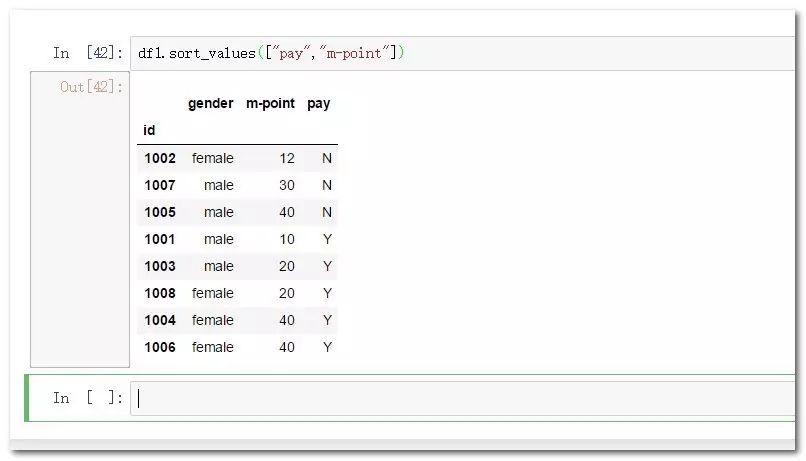
df1.sort_values(["pay","m-point"]) #排序多個字段
索引排序:
df1=df1.set_index('id') #設置索引列
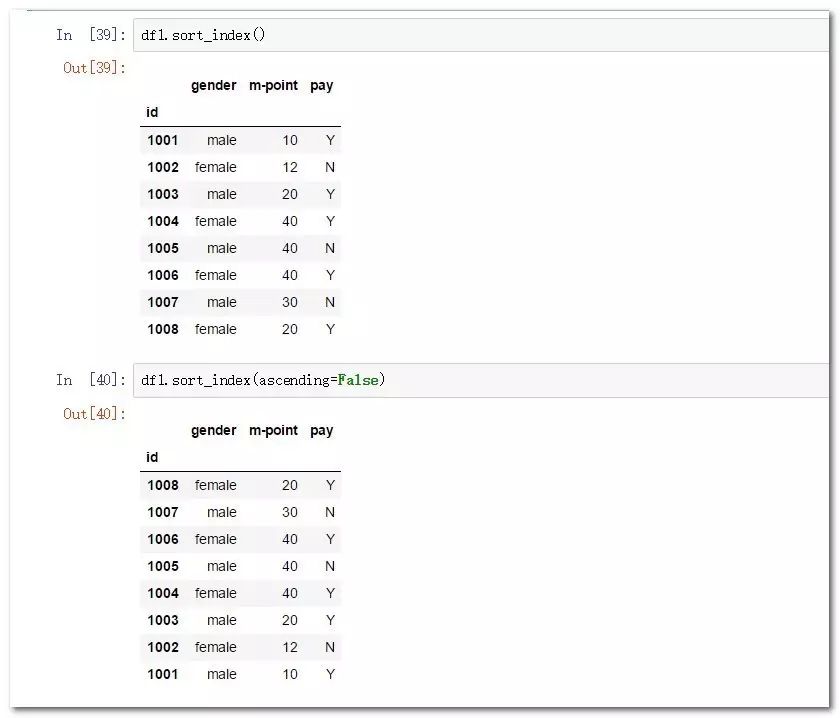
df1.sort_index() #使用索引進行排序
df1.sort_index(ascending=False) #使用索引列降序排列
--------------
本節小結:
-----------
排序函數:
R語言:
向量:
sort
order
rank
數據框:
arrange
Python:
列表與字典:
sort
sorted
數據框:
.sort_index
.sort_value
到此,相信大家對“R語言和Python中常見的排序函數應用”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





