溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下python3怎么實現常見的排序算法的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
冒泡排序是一種簡單的排序算法。它重復地走訪過要排序的數列,一次比較兩個元素,如果它們的順序錯誤就把它們交換過來。走訪數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端。
def mao(lst): for i in range(len(lst)): # 由于每一輪結束后,總一定有一個大的數排在后面 # 而且后面的數已經排好了 # 即i輪之后,就有i個數字被排好 # 所以其 len-1 -i到 len-1的位置是已經排好的了 # 只需要比較0到len -1 -i的位置即可 # flag 用于標記是否剛開始就是排好的數據 # 只有當flag狀態發生改變時(第一次循環就可以確定),繼續排序,否則返回 flag = False for j in range(len(lst) - i - 1): if lst[j] > lst[j + 1]: lst[j], lst[j + 1] = lst[j + 1], lst[j] flag = True # 非排好的數據,改變flag if not flag: return lst return lst print(mao([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
選擇排序是一種簡單直觀的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。

# 選擇排序是從前開始排的 # 選擇排序是從一個列表中找出一個最小的元素,然后放在第一位上。 # 冒泡排序類似 # 其 0 到 i的位置是排好的,只需要排i+1到len(lst)-1即可 def select_sort(lst): for i in range(len(lst)): min_index = i # 用于記錄最小的元素的索引 for j in range(i + 1, len(lst)): if lst[j] < lst[min_index]: min_index = j # 此時,已經確定,min_index為 i+1 到len(lst) - 1 這個區間最小值的索引 lst[i], lst[min_index] = lst[min_index], lst[i] return lst def select_sort2(lst): # 第二種選擇排序的方法 # 原理與第一種一樣 # 不過不需要引用中間變量min_index # 只需要找到索引i后面的i+1到len(lst)的元素即可 for i in range(len(lst)): for j in range(len(lst) - i): # lst[i + j]是一個i到len(lst)-1的一個數 # 因為j <= len(lst) -i 即 j + i <= len(lst) if lst[i] > lst[i + j]: # 說明后面的數更小,更換位置 lst[i], lst[i + j] = lst[i + j], lst[i] return lst print(select_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7])) print(select_sort2([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
快速排序是通過一趟排序將待排記錄分隔成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序。
# 原理 # 1. 任取列表中的一個元素i # 2. 把列表中大于i的元素放于其右邊,小于則放于其左邊 # 3. 如此重復 # 4. 直到不能在分,即只剩1個元素了 # 5. 然后將這些結果組合起來 def quicksort(lst): if len(lst) < 2: # lst有可能為空 return lst # ["p?v?t] 中心點 pivot = lst[0] less_lst = [i for i in lst[1:] if i <= pivot] greater_lst = [i for i in lst[1:] if i > pivot] # 最后的結果就是 # 左邊的結果 + 中間值 + 右邊的結果 # 然后細分 左+中+右 + 中間值 + 左 + 中+ 右 # ........... + 中間值 + ............ return quicksort(less_lst) + [pivot] + quicksort(greater_lst) print(quicksort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7])) print(quicksort([1, 5, 8, 62]))
插入排序的算法描述是一種簡單直觀的排序算法。它的工作原理是通過構建有序序列,對于未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入。

# lst的[0, i) 項是有序的,因為已經排過了 # 那么只需要比對第i項的lst[i]和lst[0 : i]的元素大小即可 # 假如,lst[i]大,則不用改變位置 # 否則,lst[i]改變位置,插到j的位置,而lst[j]自然往后挪一位 # 然后再刪除lst[i+1]即可(lst[i+1]是原來的lst[i]) # # 重復上面步驟即可,排序完成 def insert_sort(lst: list): # 外層開始的位置從1開始,因為從0開始都沒得排 # 只有兩個元素以上才能排序 for i in range(1, len(lst)): # 內層需要從0開始,因為lst[0]的位置不一定是最小的 for j in range(i): if lst[i] < lst[j]: lst.insert(j, lst[i]) # lst[i]已經插入到j的位置了,j之后的元素都往后+1位,所以刪除lst[i+1] del lst[i + 1] return lst print(insert_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
希爾排序是1959年Shell發明的,第一個突破O(n2)的排序算法,是簡單插入排序的改進版。它與插入排序的不同之處在于,它會優先比較距離較遠的元素。希爾排序又叫縮小增量排序。
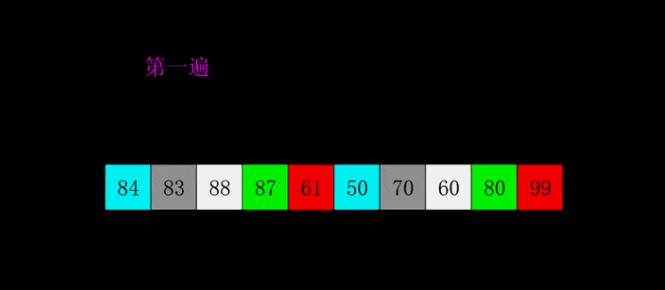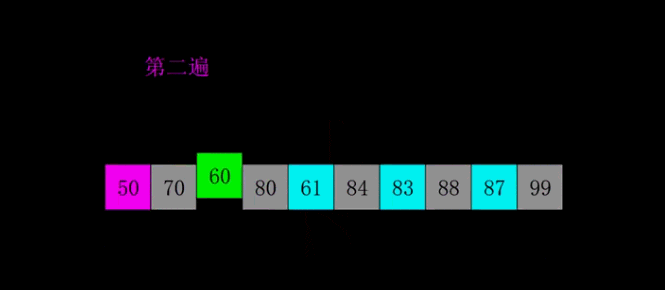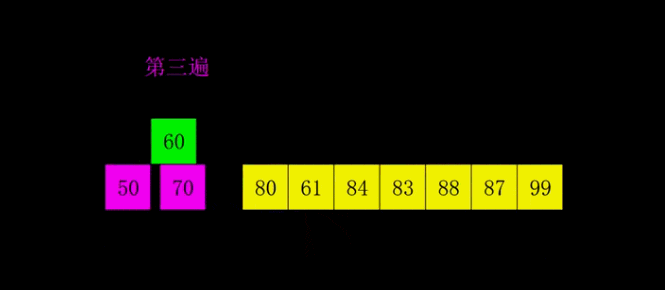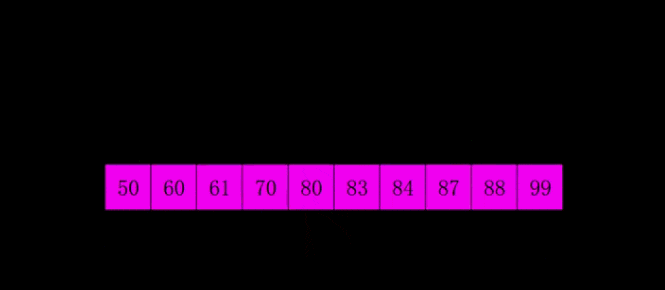
# 希爾排序是對直接插入排序的優化版本 # 1. 分組: # 每間隔一段距離取一個元素為一組 # 間隔自己確定,一般為lst的一半 # 2. 根據插入排序,把每一組排序好 # 3. 繼續分組: # 同樣沒間隔一段距離取一個元素為一組 # 間隔要求比 之前的間隔少一半 # 4. 再每組插入排序 # 5. 直到間隔為1,則排序完成 # def shell_sort(lst): lst_len = len(lst) gap = lst_len // 2 # 整除2,取間隔 while gap >= 1: # 間隔為0時結束 for i in range(gap, lst_len): temp = lst[i] j = i # 插入排序 while j - gap >= 0 and lst[j - gap] > temp: lst[j] = lst[j - gap] j -= gap lst[j] = temp gap //= 2 return lst print(shell_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7])) # 奇數 # gap = 2 # [5, 2, 4, 3, 1] # [5, 4, 1] [2, 3] # [1, 4, 5, 2, 3] # gap = 1 # [1, 2, 3, 4, 5] # 偶數 # gap = 3 # [5, 2, 4, 3, 1, 6] # [5, 3] [2, 1] [4,6] # [3, 5, 1, 2, 4 , 6] # gap = 1 # [1, 2, 3, 4, 5, 6]
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為2-路歸并。
并歸排序
# 利用分治法 # 不斷將lst分為左右兩個分 # 直到不能再分 # 然后返回 # 將兩邊的列表的元素進行比對,排序然后返回 # 不斷重復上面這一步驟 # 直到排序完成,即兩個大的列表比對完成 def merge(left, right): # left 可能為只有一個元素的列表,或已經排好序的多個元素列表(之前調用過merge) # right 也一樣 res = [] while left and right: item = left.pop(0) if left[0] < right[0] else right.pop(0) res.append(item) # 此時,left或right已經有一個為空,直接extend插入 # 而且,left和right是之前已經排好序的列表,不需要再操作了 res.extend(left) res.extend(right) return res def merge_sort(lst): lst_len = len(lst) if lst_len <= 1: return lst mid = lst_len // 2 lst_right = merge_sort(lst[mid:len(lst)]) # 返回的時lst_len <= 1時的 lst 或 merge中進行排序后的列表 lst_left = merge_sort(lst[:mid]) # 返回的是lst_len <= 1時的 lst 或 merge中進行排序后的列表 return merge(lst_left, lst_right) # 進行排序,lst_left lst_right 的元素會不斷增加 print(merge_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
堆排序是指利用堆這種數據結構所設計的一種排序算法。堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點。然后進行排序。

堆排序
# 把列表創成一個大根堆或小根堆 # 然后根據大(小)根堆的特點:根節點最大(小),逐一取值 # # 升序----使用大頂堆 # # 降序----使用小頂堆 # 本例以小根堆為例 # 列表lst = [1, 22 ,11, 8, 12, 4, 9] # 1. 建成一個普通的堆: # 1 # / # 22 11 # / / # 8 12 4 9 # # 2. 進行調整,從子開始調整位置,要求: 父節點<= 字節點 # # 1 1 1 # / 13和22調換位置 / 4和11調換位置 / # 22 11 ==============> 13 11 ==============> 13 4 # / / / / / / # 13 14 4 9 22 14 4 9 22 14 11 9 # # 3. 取出樹上根節點,即最小值,把換上葉子節點的最大值 # # 1 # / # ~~~~/ # 22 # / # 8 4 # / # 12 11 9 # # 4. 按照同樣的道理,繼續形成小根堆,然后取出根節點,。。。。重復這個過程 # # 1 1 1 4 1 4 1 4 8 1 4 8 # / / / / / / # ~~~/ ~~~/ ~~~/ ~~~/ ~~~/ ~~~/ # 22 4 22 8 22 9 # / / / / / / # 8 4 8 9 8 9 12 9 12 9 12 11 # / / / / / / # 12 11 9 12 11 22 12 11 22 11 11 22 # # 續上: # 1 4 8 9 1 4 8 9 1 4 8 9 11 1 4 8 9 11 1 4 8 9 11 12 ==> 1 4 8 9 11 12 22 # / / / / / # ~~~/ ~~~/ ~~~/ ~~~/ ~~~/ # 22 11 22 12 22 # / / / / # 12 11 12 22 12 22 # # 代碼實現 def heapify(lst, lst_len, i): """創建一個堆""" less = i # largest為最大元素的索引 left_node_index = 2 * i + 1 # 左子節點索引 right_node_index = 2 * i + 2 # 右子節點索引 # lst[i] 就是父節點(假如有子節點的話): # # lst[i] # / # lst[2*i + 1] lst[ 2*i + 2] # # 想要大根堆,即升序, 將判斷左右子節點大小的 ‘>" 改為 ‘<" 即可 # if left_node_index < lst_len and lst[less] > lst[left_node_index]: less = left_node_index if right_node_index < lst_len and lst[less] > lst[right_node_index]: # 右邊節點最小的時候 less = right_node_index if less != i: # 此時,是字節點大于父節點,所以相互交換位置 lst[i], lst[less] = lst[less], lst[i] # 交換 heapify(lst, lst_len, less) # 節點變動了,需要再檢查一下 def heap_sort(lst): res = [] i = len(lst) lst_len = len(lst) for i in range(lst_len, -1, -1): # 要從葉節點開始比較,所以倒著來 heapify(lst, lst_len, i) # 此時,已經建好了一個小根樹 # 所以,交換元素,將根節點(最小值)放在后面,重復這個過程 for j in range(lst_len - 1, 0, -1): lst[0], lst[j] = lst[j], lst[0] # 交換,最小的放在j的位置 heapify(lst, j, 0) # 再次構建一個[0: j)小根堆 [j: lst_len-1]已經倒序排好了 return lst arr = [1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7] print(heap_sort(arr))
以上就是“python3怎么實現常見的排序算法”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





