溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“R語言與Python數據聚合功能的用法介紹”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
R語言與Python的Pandas中具有非常豐富的數據聚合功能,今天就跟大家盤點一下這些函數的用法。
R語言:
transform
mutate
aggregate
grouy_by+summarize
ddply
Python:
groupby
pivot.table
在R語言中,新建變量最為快捷的方式是通過transform(當然你可以選擇使用自定義函數),該函數支持基于同一個數據框新建多個變量。
這里仍然使用經典的鶯尾花數據集演示:
iris1<-iris
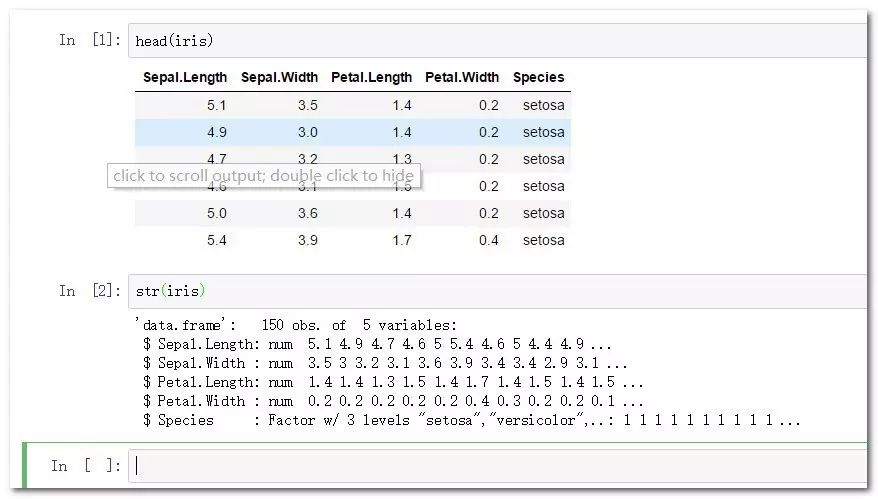
transform與mutate兩個函數都是新建變量,但是前者僅能基于所提供的數據框內變量進行新建,而后者則可以直接在新建變量基礎上進行操作。
(iris1<-transform(iris1,dek=Sepal.Length/Sepal.Width,pek=Petal.Length+Petal.Width))
(iris1<-dplyr::mutate(iris1,dek=Sepal.Length+Sepal.Width,jek=sqrt(dek)))
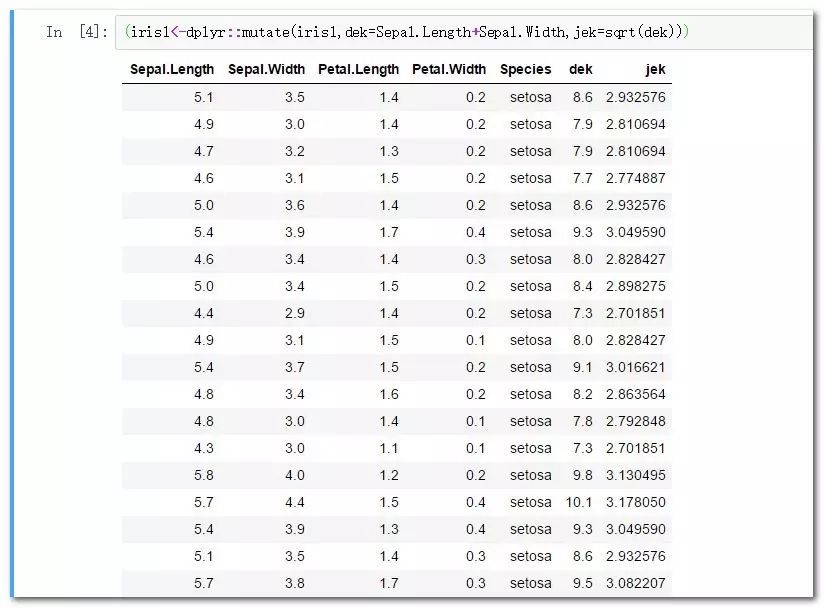
aggregate是專門用于分組聚合的函數:
aggregate(value~class,data,fun)
#表達式左側是要聚合的目標度量,右側是分組依據,緊接著是數據框名稱,最后是聚合函數。
aggregate(Sepal.Length~Species,iris,mean)
aggregate(Sepal.Length~Species,iris,sum)
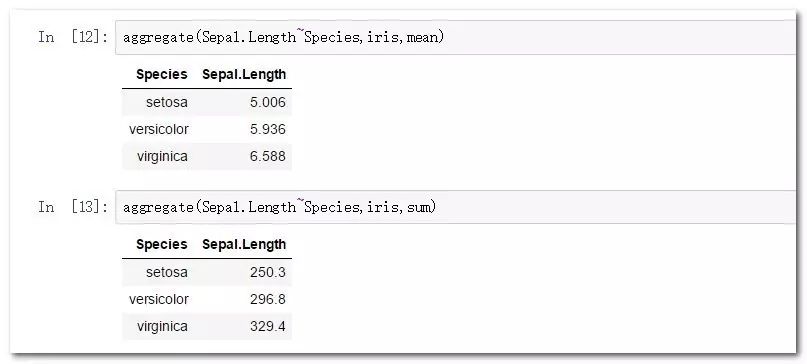
library(dplyr)
使用group_by函數結合summarize可以方便的完成分組聚合功能。
iris%>%group_by(Species)%>%summarize(means=mean(Sepal.Length))
iris%>%group_by(Species)%>%summarize(sums=sum(Sepal.Length))
R語言中的分組聚合如果使用矢量函數來進行操作,會大大提升其執行效率:
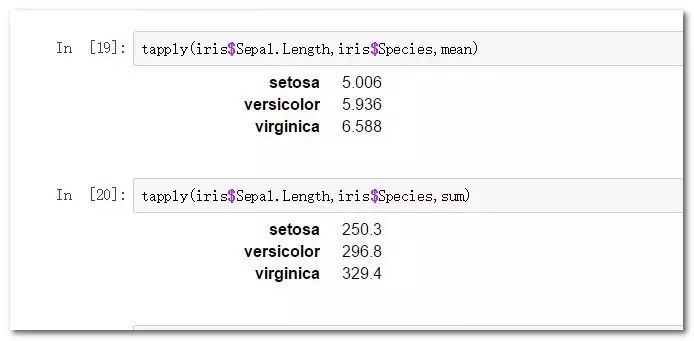
tapply(iris$Sepal.Length,iris$Species,mean)
tapply(iris$Sepal.Length,iris$Species,sum)
tapply(X, INDEX, FUN = NULL, …, simplify = TRUE)
tapply是一個快捷的分組聚合函數,其參數簡單易懂,通過提供一個度量,一個分類別字段,一個聚合函數即可完成簡答的數據聚合功能。
library(plyr)
ddply(iris,.(Species),summarize,means=mean(Sepal.Length))
ddply(iris,.(Species),summarize,means=sum(Sepal.Length))
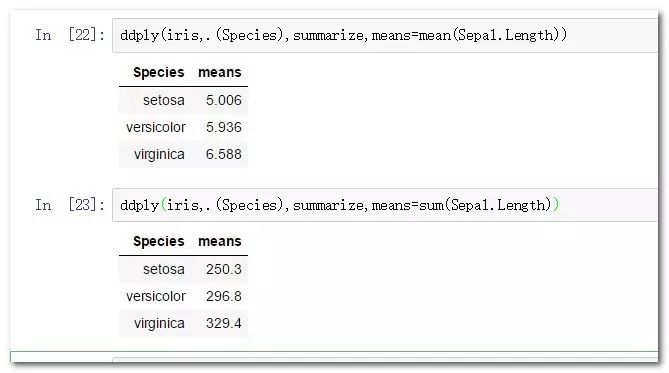
ddply(.data, .variables, .fun =) #一般只需提供數據框,帶聚合分類字段,以及最終的聚合函數與聚合變量公式。它的用法與內置的tpply用法如出一轍。
----------
Python:
----------
import pandas as pd
import numpy as np
Python中長用到的數據聚合工具主要包括groupby函數,agg函數以及povit_table等。
groupby
agg
povit_table
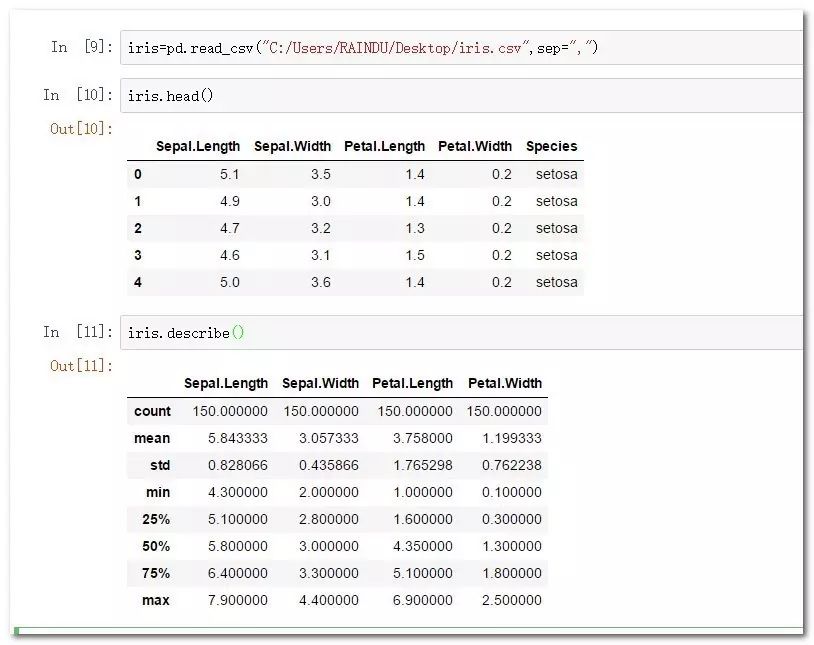
iris=pd.read_csv("C:/Users/RAINDU/Desktop/iris.csv",sep=",")
iris.head()
iris.describe()
使用pandas中的groupby方法可以很快捷的進行分組數據聚合。
iris.groupby('Species')['Sepal.Length'].mean()
iris.groupby('Species')['Sepal.Length'].sum()
iris.groupby('Species')['Sepal.Length'].agg([len,np.sum,np.mean])
iris.groupby('Species')['Sepal.Length'].agg({'count':len,'sum':np.sum,'mean':np.mean})
#對輸出進行自定義命名:
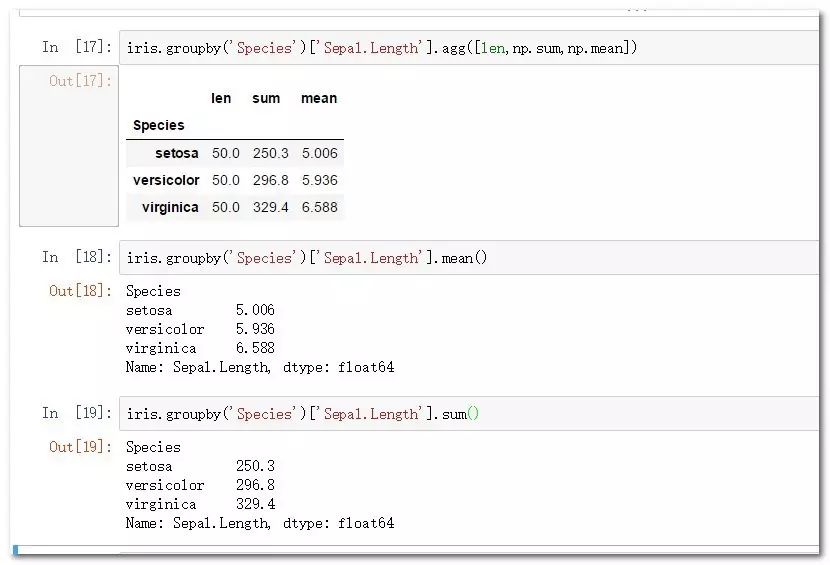
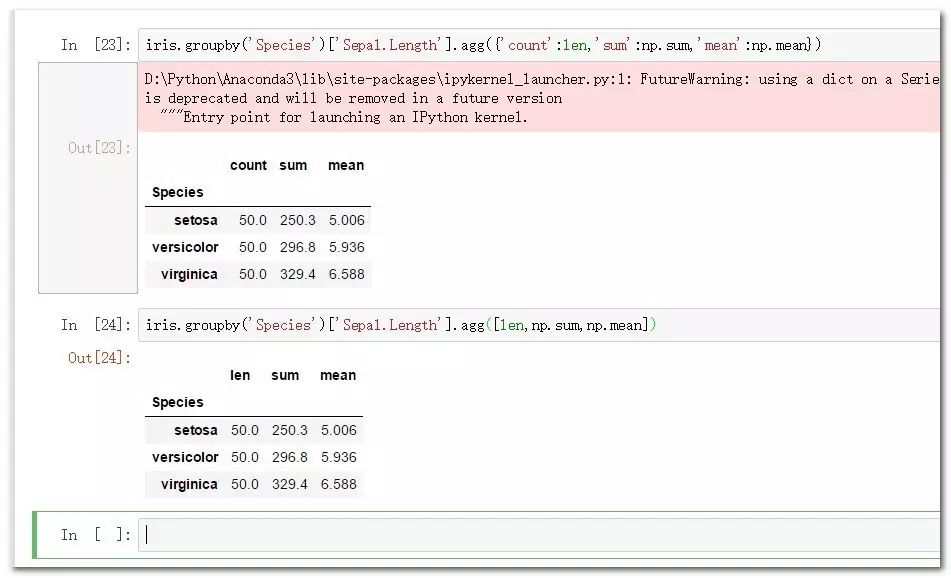
只聚合一個變量可以直接使用對應聚合函數,需要聚合多個變量則可以 借助agg函數完成。
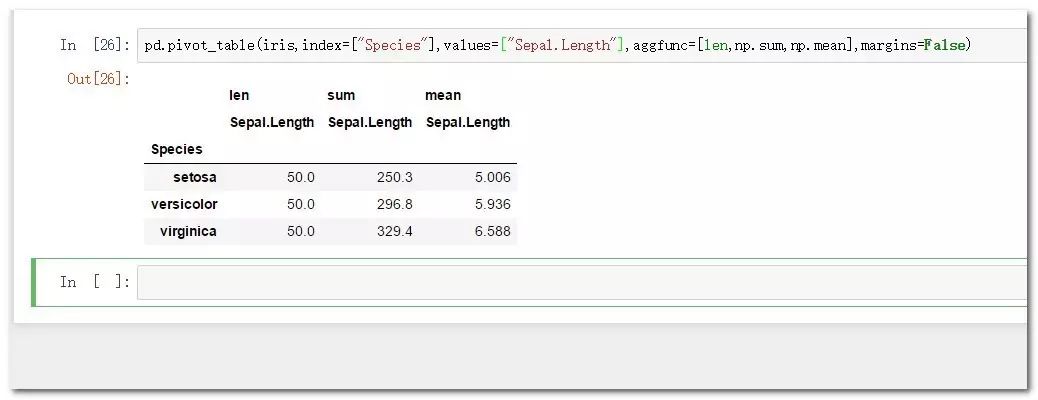
pd.pivot_table(iris,index=["Species"],values=["Sepal.Length"],aggfunc=[len,np.sum,np.mean],margins=False)
“R語言與Python數據聚合功能的用法介紹”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





