溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“python爬蟲如何爬取抖音熱門音樂”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“python爬蟲如何爬取抖音熱門音樂”這篇文章吧。
爬取抖音的熱門音樂
這個就相對來說簡單一點,這是代碼運行的結果
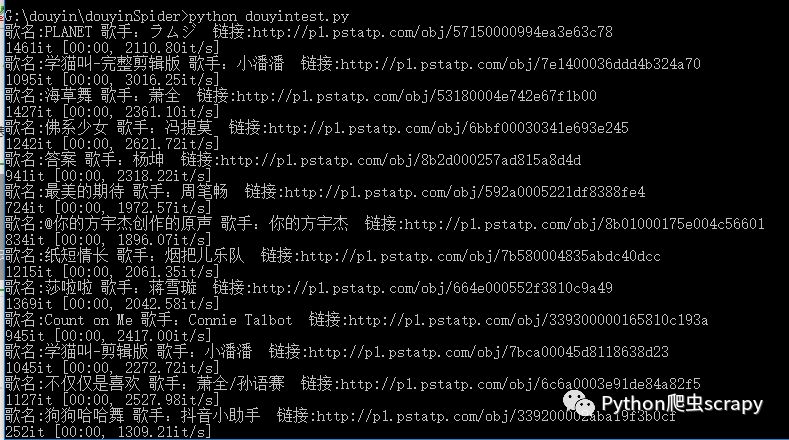
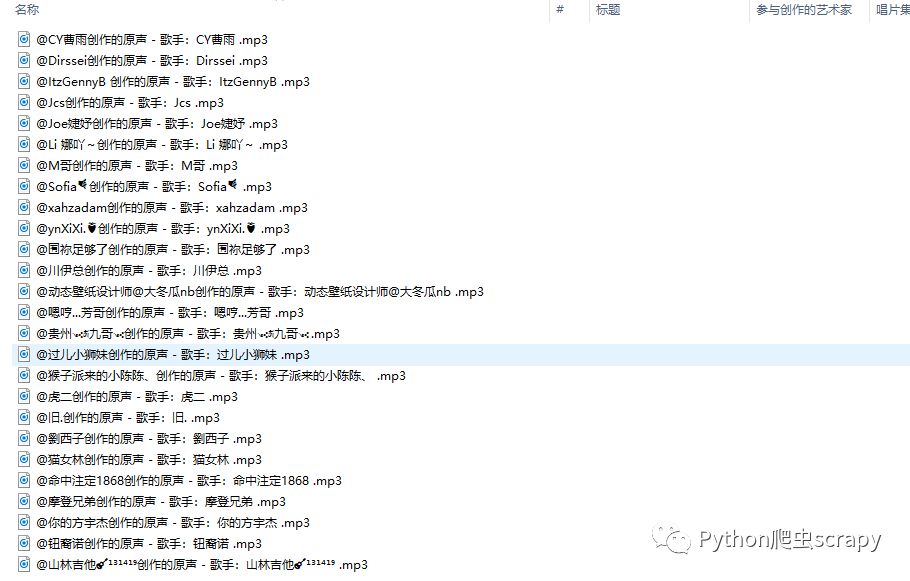
獲取音樂的網址https://kuaiyinshi.com/hot/music/?source=dou-yin&page=1
打開該網頁F12,F5刷新
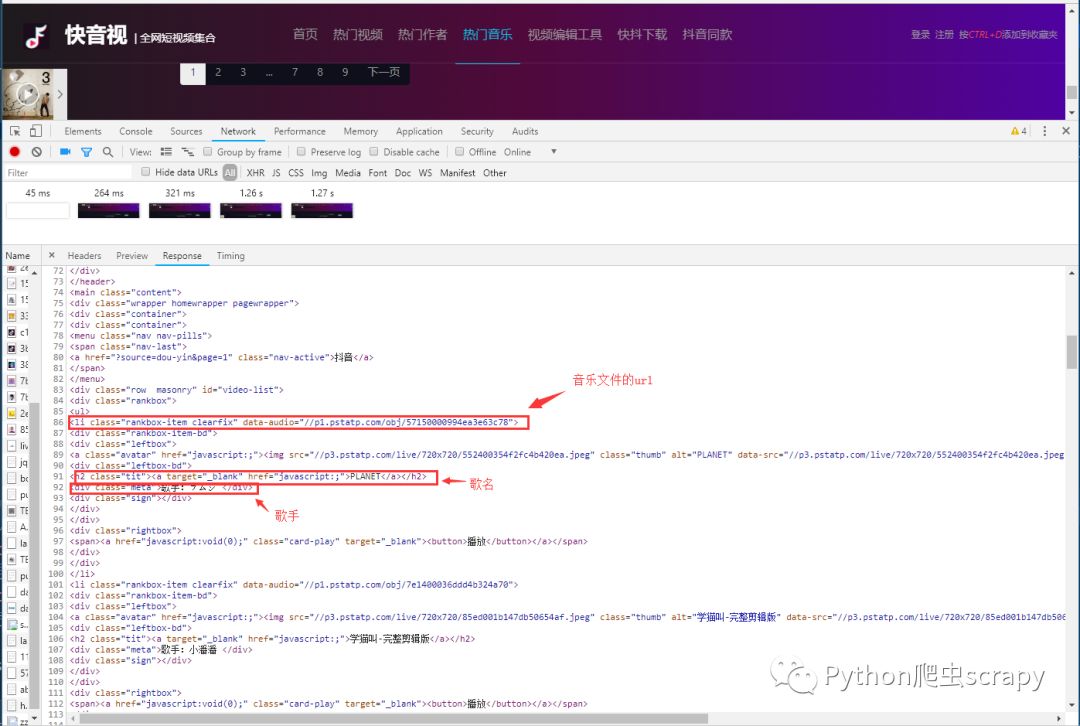
做義工只需要以上的數據
根據beautifulsoup去獲取,直接上代碼
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 保存路徑
save_path = "G:\\Music\\douyin\\"
url = "https://kuaiyinshi.com/hot/music/?source=dou-yin&page=1"
# 獲取響應
res = requests.get(url, headers=headers)
# 使用beautifulsoup解析
soup = BeautifulSoup(res.text, 'lxml')
# 選擇標簽獲取最大頁數
max_page = soup.select('li.page-item > a')[-2].text
# 循環請求
for page in range(int(max_page)):
page_url = "https://kuaiyinshi.com/hot/music/?source=dou-yin&page={}".format(page + 1)
page_res = requests.get(page_url, headers=headers)
soup = BeautifulSoup(page_res.text, 'lxml')
lis = soup.select('li.rankbox-item')
singers = soup.select('div.meta')
music_names = soup.select('h3.tit > a')
for i in range(len(lis)):
music_url = "http:" + lis[i].get('data-audio')
print("歌名:" + music_names[i].text, singers[i].text, "鏈接:" + music_url)
try:
download_file(music_url,
save_path + music_names[i].text + ' - ' + singers[i].text.replace('/', ' ') + ".mp3")
except:
pass
print("第{}頁完成~~~".format(page + 1))
time.sleep(1)將獲取到的文件的url傳遞到下載函數中
def download_file(src, file_path):
# 響應體工作流
r = requests.get(src, stream=True)
# 打開文件
f = open(file_path, "wb")
# for chunk in r.iter_content(chunk_size=512):
# if chunk:
# f.write(chunk)
for data in tqdm(r.iter_content(chunk_size=512)):
#tqdm進度條的使用,for data in tqdm(iterable)
f.write(data)
return file_path接下來就是關于響應體工作流的說明

默認情況下,當你進行網絡請求后,響應體會立即被下載。你可以通過 stream 參數覆蓋這個行為,推遲下載響應體直到訪問 Response.content 屬性:
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master' r = requests.get(tarball_url, stream=True)
此時僅有響應頭被下載下來了,連接保持打開狀態,因此允許我們根據條件獲取內容:
if int(r.headers['content-length']) < TOO_LONG: content = r.content ...
你可以進一步使用 Response.iter_content 和 Response.iter_lines 方法來控制工作流,或者以 Response.raw 從底層 urllib3 的 urllib3.HTTPResponse <urllib3.response.HTTPResponse讀取。
如果你在請求中把 stream 設為 True,Requests 無法將連接釋放回連接池,除非你 消耗了所有的數據,或者調用了 Response.close。 這樣會帶來連接效率低下的問題。如果你發現你在使用stream=True 的同時還在部分讀取請求的 body(或者完全沒有讀取 body),那么你就應該考慮使用 contextlib.closing (文檔), 如下所示:
from contextlib import closing with closing(requests.get('http://httpbin.org/get', stream=True)) as r: # 在此處理響應。
以上是“python爬蟲如何爬取抖音熱門音樂”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





