溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
利用python怎么爬取抖音的評論數據?相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
python3 下載
fiddle 安裝及配置
手機模擬器下載
模擬器下載好之后, 打開模擬器
在應用市場下載抖音

對抖音進行fiddle配置,配置成功后就可以當手機一樣使用了
我們隨便打開一個視頻之后,fiddle就會刷新新的數據包
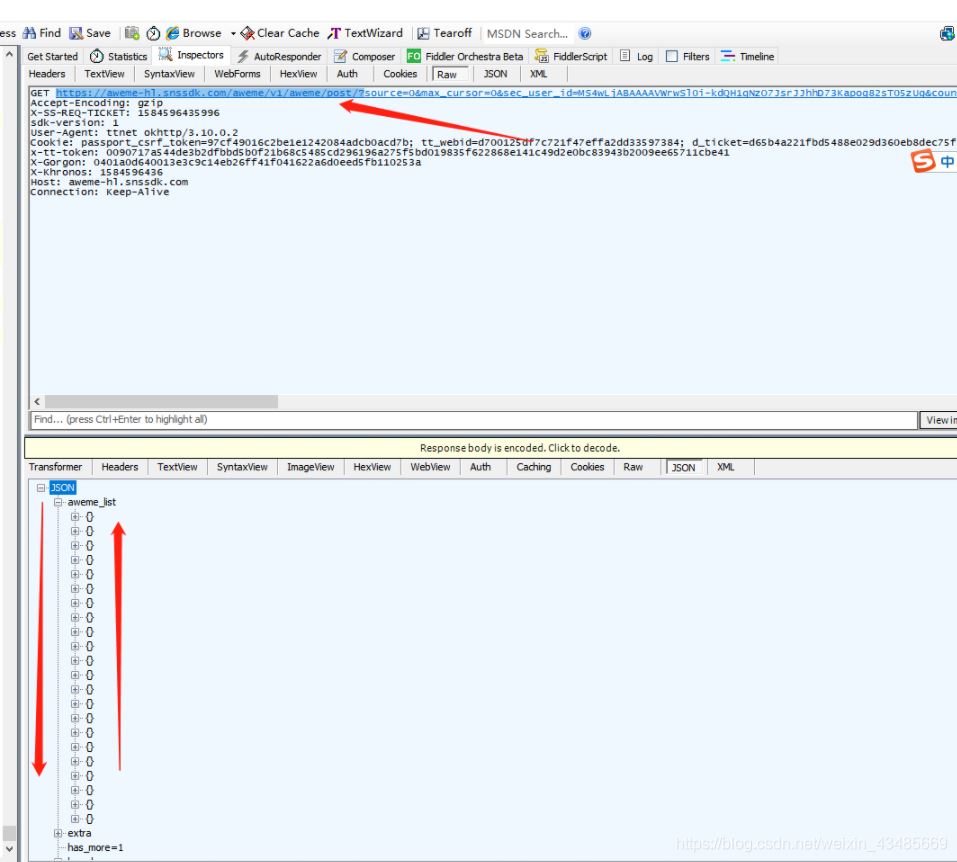
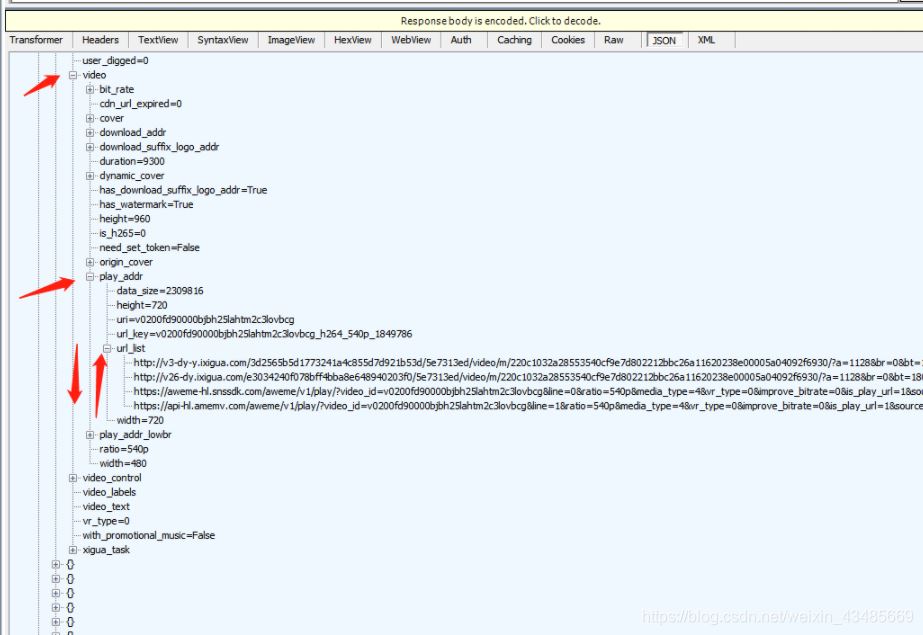
在json中找到視頻地址:
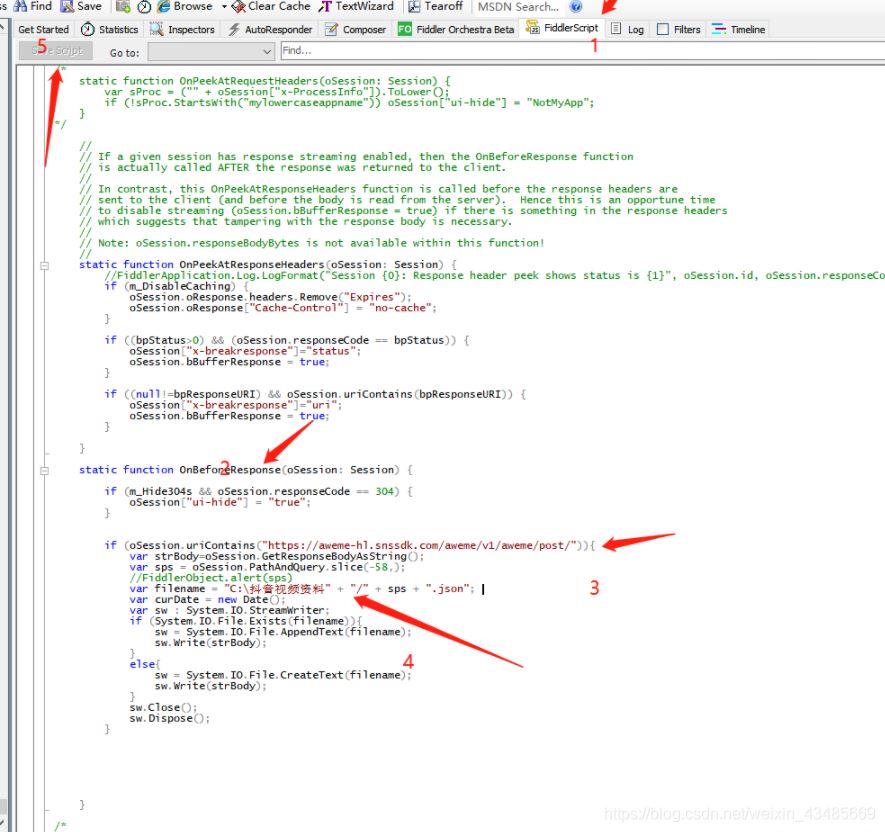
在fiddler中添加下載視頻代碼:注意兩點:
(1)get后面的路徑要隨時看進行更換
(2)下載的路徑要在fiddler下面自己新建
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
if (oSession.uriContains("https://aweme.snssdk.com/aweme/v1/general/search/single/")){
var strBody=oSession.GetResponseBodyAsString();
var sps = oSession.PathAndQuery.slice(-58,);
//FiddlerObject.alert(sps)
var timestamp=new Date().getTime();
var filename = "D:\抖音評論資料" + "/" + sps + timestamp + ".json";
var curDate = new Date();
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(strBody);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(strBody);
}
sw.Close();
sw.Dispose();此段代碼放到fiddler中的script的response中,如下圖:添加好之后別忘記保存!!
程序執行代碼:
import os
import json
import time
import requests
import re
import csv
class Douyin(object):
def __init__(self):
pass
self.url1 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885929189950737676&cursor=0&count=20&address_book_access=1&gps_access=1&forward_page_type=1&channel_id=0&city=310000&hotsoon_filtered_count=0&hotsoon_has_more=0&follower_count=0&is_familiar=0&page_source=0&os_api=25&device_type=VOG-AL00&ssmix=a&manifest_version_code=110301&dpi=240&uuid=868594157367551&app_name=aweme&version_name=11.3.0&ts=1603350069&cpu_support64=false&app_type=normal&ac=wifi&host_abi=armeabi-v7a&channel=aweGW&update_version_code=11309900&_rticket=1603350070959&device_platform=android&iid=1758845207590062&version_code=110300&mac_address=b0%3Ac4%3A2d%3Ad0%3Aed%3A38&cdid=7974198e-c4c0-49c2-bfaa-43686052706e&openudid=d0c6cffa7067bedd&device_id=844047245117672&resolution=720*1280&device_brand=HUAWEI&language=zh&os_version=7.1.2&aid=1128&mcc_mnc=46000'
self.url2 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885163969477086479&cursor=0&count=20'
self.header = {
'Accept-Encoding': 'gzip',
'X-SS-REQ-TICKET': '1603350070957',
'sdk-version': '1',
'Cookie': 'install_id=1758845207590062; ttreq=1$34f012b99d70a66f681dc3d1f0b438fc1b161af3; d_ticket=77247c94236bf8055c233f8cabb6a5ddf3231; odin_tt=fccb20add45a15f08a2519eadcaaf22cba4b3f8f1fceec300a088407c2daf81ea76b260ef6c81dbc86dfedfea011f68c25238f9b3984fe4f5909441dfd1cc9c2; sid_guard=6de18a966e69dcbbf076f629a2ef6511%7C1603345424%7C5184000%7CMon%2C+21-Dec-2020+05%3A43%3A44+GMT; uid_tt=ba98af780b4e337f01463cf98a8afafd; sid_tt=6de18a966e69dcbbf076f629a2ef6511; sessionid=6de18a966e69dcbbf076f629a2ef6511',
'x-tt-token': '006de18a966e69dcbbf076f629a2ef651189d3f6f73fd3d6319b543d50d2e2e5a4cf3e383f8da81f07e049bcf850de07d331',
'X-Gorgon': '0404d8210000a6a3dca0dbc6b11483a82420c9a94dd050a3e511',
'X-Khronos': '1603350070',
'Host': 'aweme.nssdk.com',
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
}
self.add = 'D:\抖音評論資料'
self.videos_list = os.listdir('D:\抖音評論資料')
def parse(self):
'鏈接,內容,發布人昵稱,發布時間,點贊數,評論數,分享數'
lists = []
for vid in self.videos_list:
a = open('D:\抖音評論資料\{}'.format(vid),encoding='utf-8')
content = json.load(a)
for con in content['data']:
meta = {}
try:
meta['title'] = con['aweme_info']['desc']
meta['author_name'] = con['aweme_info']['author']['nickname']
meta['u_name'] = con['aweme_info']['author']['unique_id']
meta['create_time'] = con['aweme_info']['create_time']
timeArray = time.localtime(meta['create_time'])
meta['create_time'] = time.strftime("%Y--%m--%d %H:%M:%S", timeArray)
meta['digg_count'] = con['aweme_info']['statistics']['digg_count']
meta['comment_count'] = con['aweme_info']['statistics']['comment_count']
meta['share_count'] = con['aweme_info']['statistics']['share_count']
meta['share_url'] = con['aweme_info']['share_url']
except:
meta['title'] = ''
meta['author_name'] = ''
meta['u_name'] = ''
meta['create_time'] = ''
meta['digg_count'] = ''
meta['comment_count'] = ''
meta['share_count'] = ''
meta['share_url'] = ''
if meta['u_name'] == '':
try:
meta['u_name'] = con['aweme_info']['music']['owner_handle']
except:
meta['u_name'] = ''
if meta['title'] == '':
pass
else:
lists.append(meta)
# print(meta)
return lists
def save_data(self, meta):
header = ['share_url', 'title', 'author_name', 'u_name', 'create_time', 'digg_count', 'comment_count', 'share_count']
print(meta)
with open('test.csv', 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader() # 寫入列名
writer.writerows(meta)
def run(self):
meta = self.parse()
self.save_data(meta)
if __name__ == '__main__':
douyin = Douyin()
douyin.run()運行代碼后在代碼執行目錄下會生成一個excel
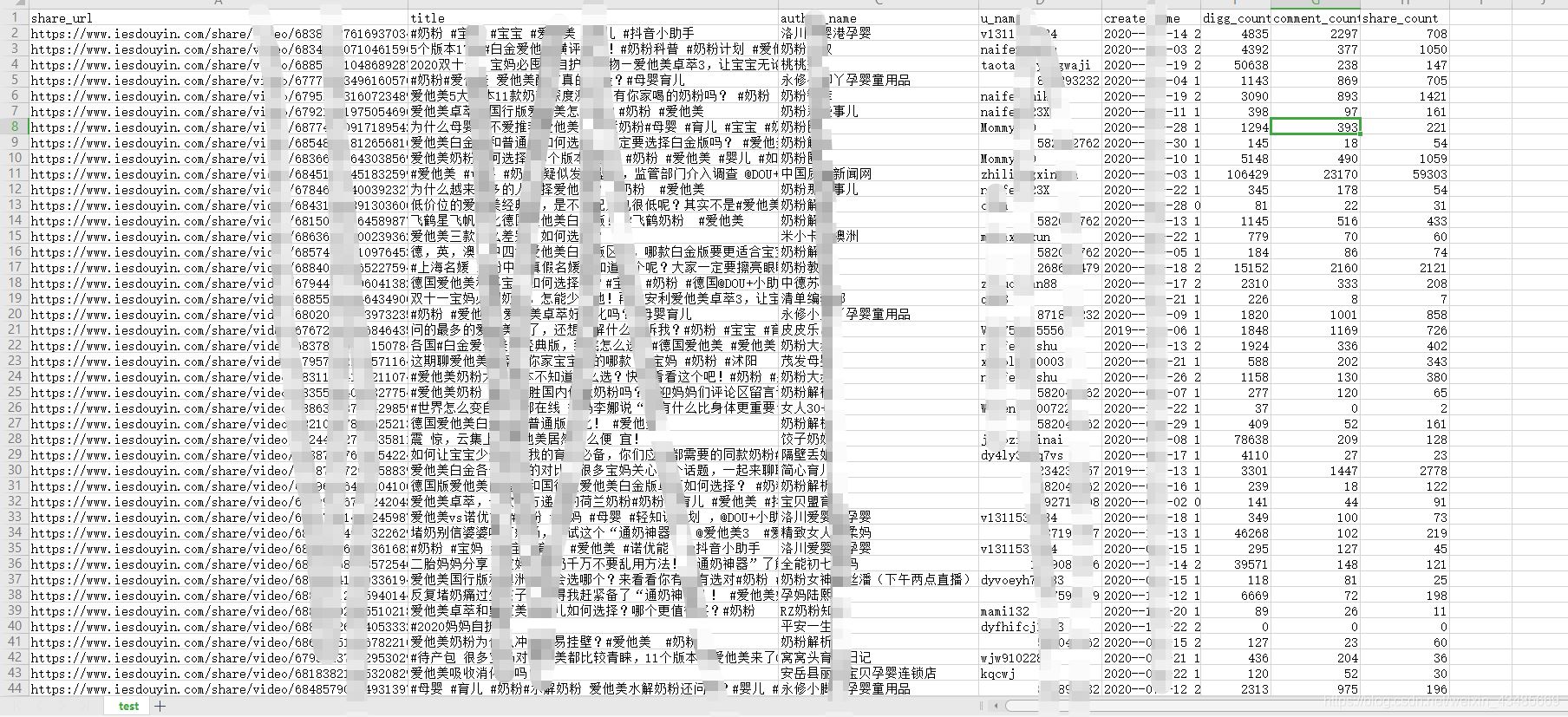
ps:抖音不會一次性返回整個評論數據包,每次往下滑動評論區會多出26條評論數據,我們就可以利用模擬器進行滑動操作。
點擊 更多>鼠標宏
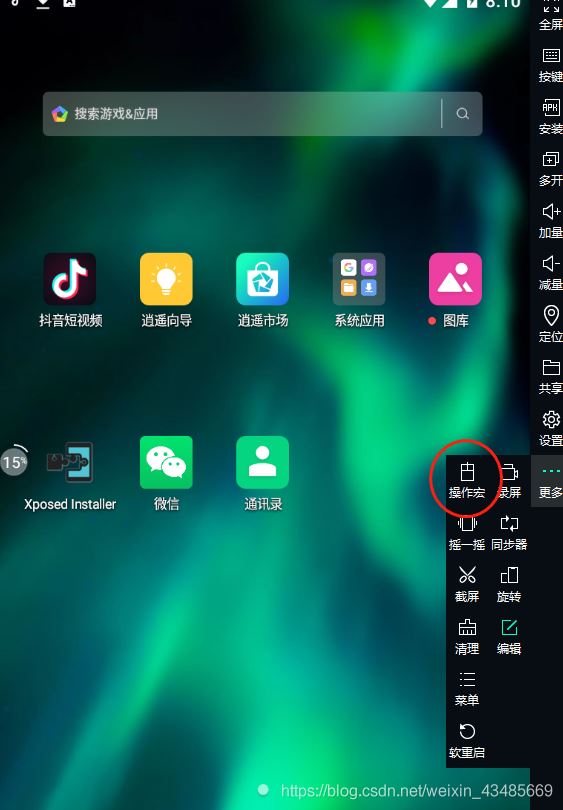
點擊錄屏之后,用鼠標往下滑動一次頁面

點擊停止,就會將你剛才的操作保存下來
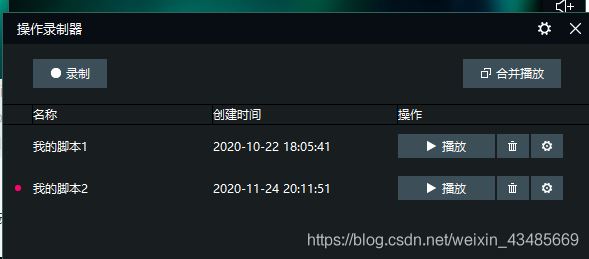
點擊設置 可以對剛才的操作進行循環播放,從而達到自動刷新評論區。

看完上述內容,你們掌握利用python怎么爬取抖音的評論數據的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





