溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何通過Python爬取網頁抖音熱門視頻,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
前言
抖音短視頻相信大家都聽過,也不陌生對吧!可以看到海量的短視頻,涵蓋了各大行業。個人覺得抖音有毒,刷著刷著根本停不下來,一看時間就是凌晨3、4點。今天帶大家爬取抖音網頁版的視頻數據!一睹為快吧
1、系統分析網頁性質
2、正則提取數據(難點)
3、海量音頻數據保存
python 3.6
pycharm
requests
re
1、分析目標網頁,確定爬取的url路徑,headers參數
2、發送請求 -- requests 模擬瀏覽器發送請求,獲取響應數據
3、解析數據 -- 正則表達式
4、保存數據 -- 保存在目標文件夾中

1、導入工具
base_url = 'http://douyin.bm8.com.cn/d_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}2、分析目標網頁,確定爬取的url路徑,headers參數
base_url = 'http://douyin.bm8.com.cn/d_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}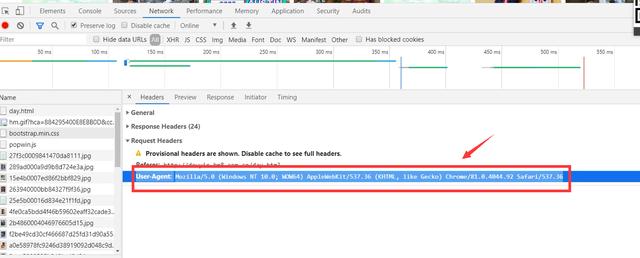
3、發送請求 -- requests 模擬瀏覽器發送請求,獲取響應數據
response = requests.get(url=base_url, headers=headers) html_data = response.text
4、解析數據 -- 正則表達式
pattern = re.compile('onclick="open1\(\'(.*?)\',\'(.*?)\',\'\'\)')
result = pattern.findall(html_data)
print(result)5、構建一個for循環
for page in range(8, 10):
print('===================正在取第{}頁數據================='.format(page))
# 1、分析目標網頁,確定爬取的url路徑,headers參數
base_url = 'http://douyin.bm8.com.cn/d_{}.html'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}6、處理文件名非法字符
def change_title(title): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? ">
7、保存數據 -- 保存在目標文件夾中
for title, url in result:
# 請求抖音視頻數據
data = requests.get(url=url, headers=headers).content
new_title = change_title(title)
with open('videos\\' + new_title + '.mp4', mode='wb') as f:
f.write(data)
print('保存完成:', title)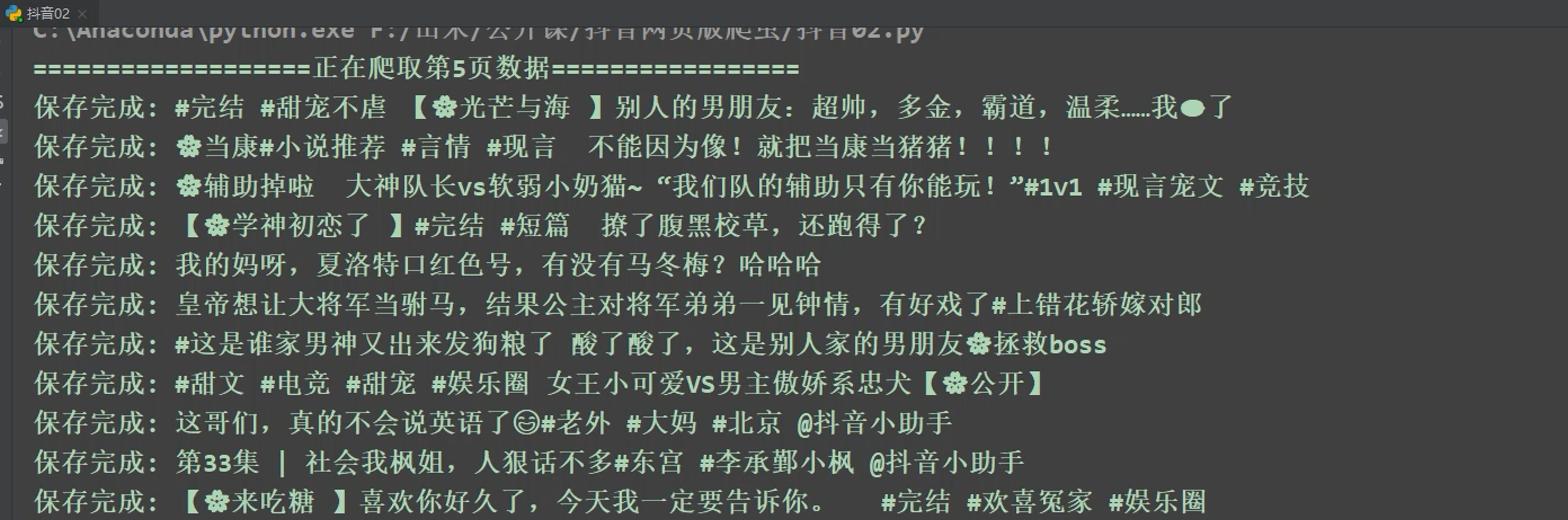
看完上述內容,你們掌握如何通過Python爬取網頁抖音熱門視頻的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





