溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python如何爬取抖音用戶詳細數據,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
首先在搭建好的環境中通過Fiddle抓取用戶數據包。<br/> <br/>
<br/>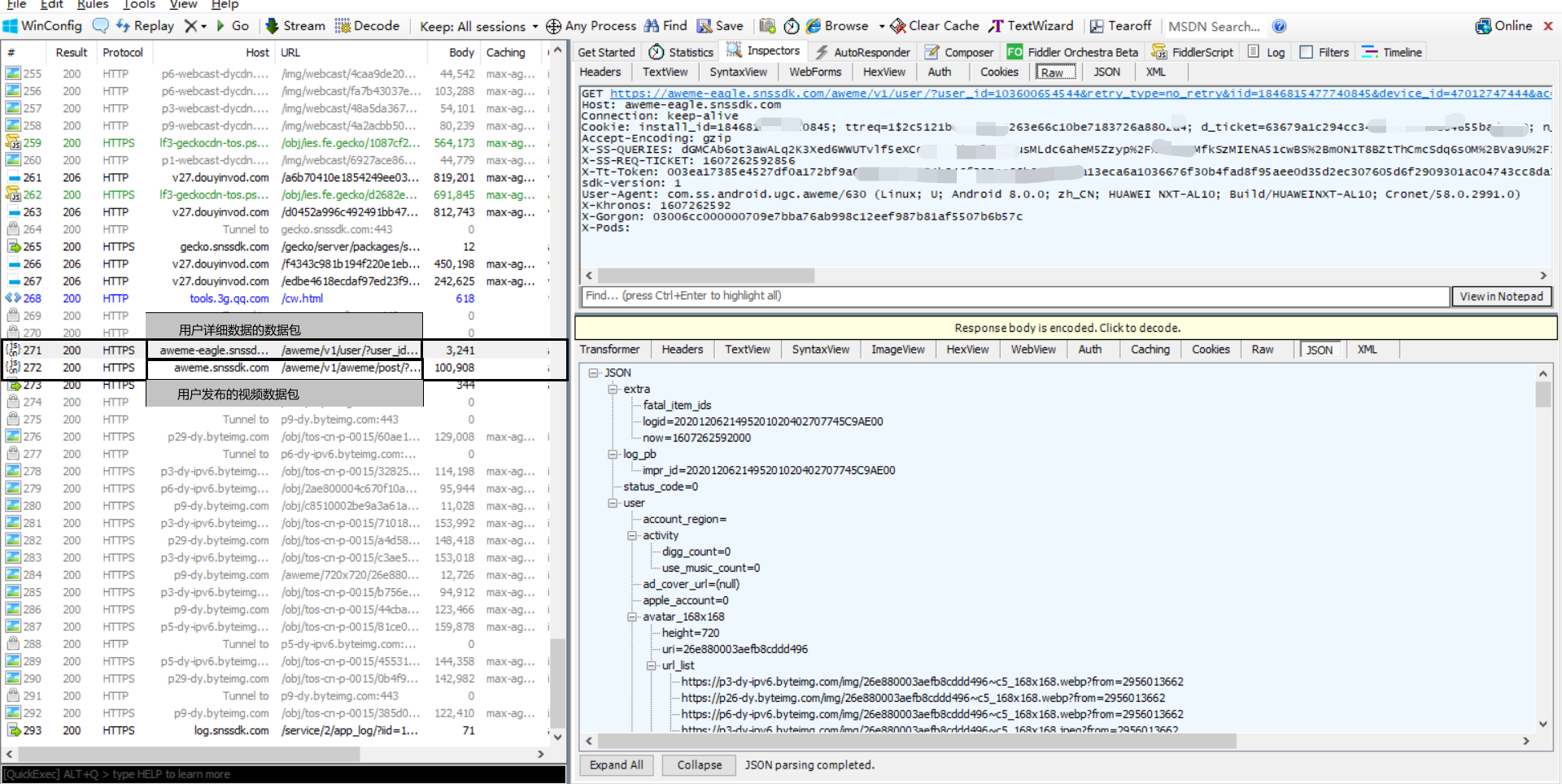
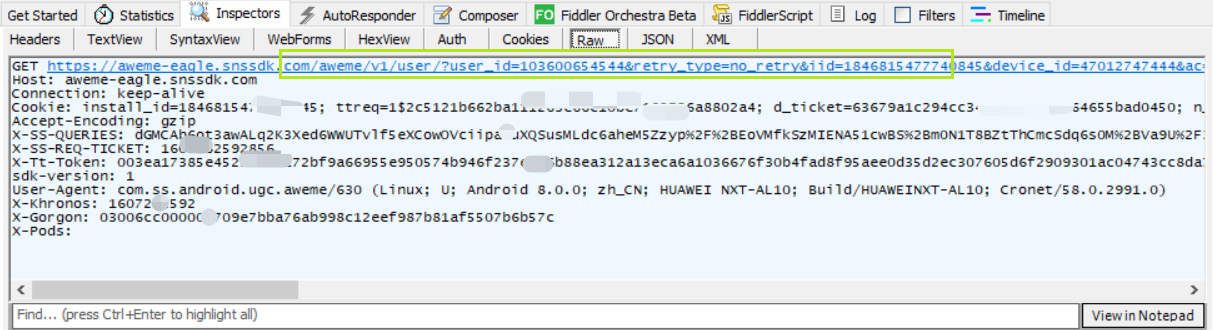
請求頭字段 | 字段 | 字段值 | | --- | --- | | 請求方法 | GET | | 請求的api | GET后面的 | | 請求的協議 | api后面的,系http1.1 | | 請求的目的主機域名 | aweme-eagle.snssdk.com | | 連接信息 | keep-alive | | Cookie | 你自己的cookies | | Accept-Encoding 編碼信息 | gzip | | X-SS-QUERIES | 請求的query | | token | 你自己的token | | sdk版本 | 1 | | User-Agent | 用戶代理 | | X-Khronos | 咱也不知道是啥,但是本質上就是個時間戳 | | X-Gorgon | 加密驗證的部分 | | X-Pods | 咱也不知道是啥,但是貌似沒有用 |
請求的api分析
 <br/>我們知道了請求的api以及請求頭里面都包含了哪些信息,我們就可以通過手動構造對應的請求參數來爬取用戶的數據了。我已經在前面的文章獲取到了1W+ 的用戶的uid以及sec_user_id的數據了,然后我們就可以通過這些數據來爬取用戶的詳細數據。
<br/>我們知道了請求的api以及請求頭里面都包含了哪些信息,我們就可以通過手動構造對應的請求參數來爬取用戶的數據了。我已經在前面的文章獲取到了1W+ 的用戶的uid以及sec_user_id的數據了,然后我們就可以通過這些數據來爬取用戶的詳細數據。
 <br/>
<br/> <br/>
<br/>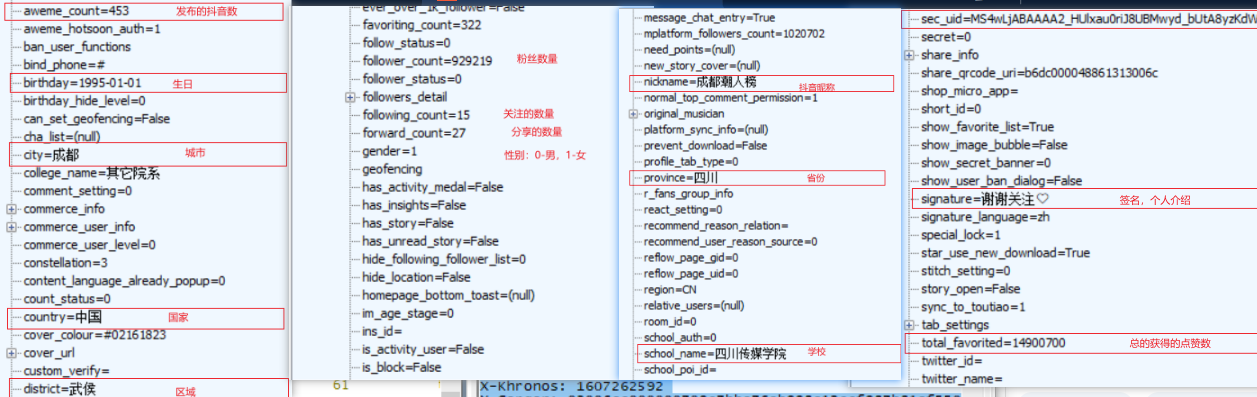 <br/>
<br/>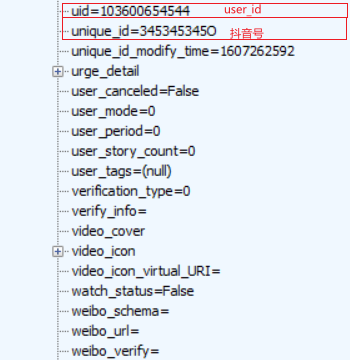
在文章《抖音爬蟲教程,從0到1,獲取抖音用戶數據》 我們已經介紹了爬取抖音關注列表的api及其構造方法,其實獲取用戶詳細信息和獲取用戶的關注列表的api基本一致,主要都是需要我們自行填充用戶的user_id以及用戶的sec_user_id還有一大堆的時間戳信息,其他的信息都是不變的。下面我們構造獲取用戶詳細信息的api<br/>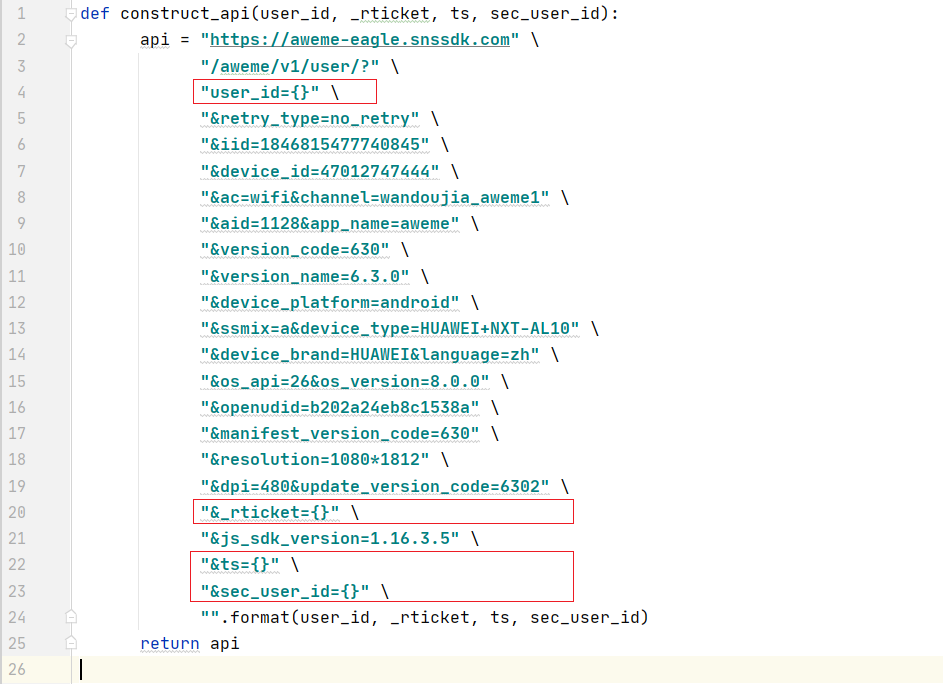
def construct_api(user_id, _rticket, ts, sec_user_id):
"""
api 構造函數
:param user_id: 用戶的id
:param _rticket: 時間戳
:param ts: 時間戳
:param sec_user_id: 用戶的加密的id
:return: api
"""
api = "https://aweme-eagle.snssdk.com" \
"/aweme/v1/user/?" \
"user_id={}" \
"&retry_type=no_retry" \
"&iid=1846815477740845" \
"&device_id=47012747444" \
"&ac=wifi&channel=wandoujia_aweme1" \
"&aid=1128&app_name=aweme" \
"&version_code=630" \
"&version_name=6.3.0" \
"&device_platform=android" \
"&ssmix=a&device_type=HUAWEI+NXT-AL10" \
"&device_brand=HUAWEI&language=zh" \
"&os_api=26&os_version=8.0.0" \
"&openudid=b202a24eb8c1538a" \
"&manifest_version_code=630" \
"&resolution=1080*1812" \
"&dpi=480&update_version_code=6302" \
"&_rticket={}" \
"&js_sdk_version=1.16.3.5" \
"&ts={}" \
"&sec_user_id={}" \
"".format(user_id, _rticket, ts, sec_user_id)
return api上文我們已經分析了請求頭,請求頭的構造也比較方便,大部分內容都是固定的,需要我們填充的主要還是幾個時間戳以及對應的X-Gorgon,其中X-Gorgon的構造方法比較復雜,但是要注意填入正確的Cookie和Token你才能獲得可用的X-Gorgon,否則你的Gorgon就是不可用的。下圖是請求頭里面的主要信息:<br/>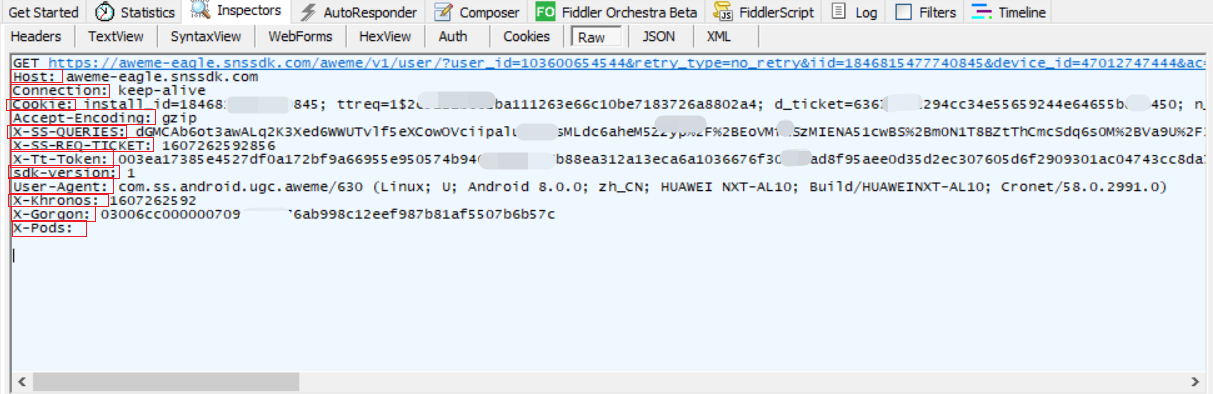 <br/>下面我寫了一個構造請求頭的函數:
<br/>下面我寫了一個構造請求頭的函數:
def construct_header(user_id, sec_user_id, cookie, query, token, user_agent, _rticket, ts):
"""
構造請求頭,需要傳入的參數如下
:param user_id: 要爬取的用戶的uid
:param sec_user_id: 要爬取的用戶的加密的id
:param cookie: cookie
:param query: 請求的query
:param token: 你的token
:param user_agent: 請求的user_agent
:param _rticket: 時間戳(毫秒級)
:param ts: 時間戳(秒級)
:return: 構造好的請求頭:headers
"""
api = construct_api(user_id, _rticket, ts, sec_user_id)
headers = {
"Host": "aweme-eagle.snssdk.com",
"Connection": "keep-alive",
"Cookie": cookie,
"Accept-Encoding": "gzip",
"X-SS-QUERIES": query,
"X-SS-REQ-TICKET": _rticket,
"X-Tt-Token": token,
"sdk-version": "1",
"User-Agent": user_agent
}
x_gorgon = get_gorgon(api, cookie, token, query)
headers["X-Khronos"] = ts
headers["X-Gorgon"] = x_gorgon
print(headers)
return headers
def get_gorgon(url, cookies, token, query):
"""
獲取headers里面的X-Gorgon
:param url: 請求的api
:param cookies: 你的cookie
:param token: 你的token
:param query: 你的query
:return: gorgon
"""
# 發起請求獲取X-Gorgon
headers = {
"dou-url": url, # 填寫對應的請求的api
"dou-cookies": cookies, # 填寫你的cookies
"dou-token": token, # 填寫你的token
"dou-queries": query # 填寫你的請求的queries
}
gorgon_host = "http://8.131.59.252:8080"
res = requests.get(gorgon_host, headers=headers)
gorgon = ""
if res.status_code == 200:
print("請求成功")
res_gorgon = json.loads(res.text)
if res_gorgon.get("status") == 0:
print("成功獲取 X-Gorgon")
print(res_gorgon.get("X-gorgon")) # 你就可以用來爬數據了
gorgon = res_gorgon.get("X-gorgon")
else:
print("獲取 X-Gorgon 失敗")
print(res_gorgon.get("reason"))
raise ValueError(res_gorgon.get("reason"))
else:
print("請求發送錯誤/可能是你的網絡錯誤,也可能是我的錯誤,但是大概率是你那邊的錯誤")
raise ValueError("請求發送錯誤/可能是你的網絡錯誤,也可能是我的錯誤,但是大概率是你那邊的錯誤")
return gorgondef get_user_detail_info(cookie, query, token, user_agent, user_id, sec_user_id):
"""
爬取用戶數據
:param cookie: 你自己的cookie
:param query: 你自己的query
:param token: 你自己的token
:param user_agent: 你自己的User-Agent
:param user_id: 用戶的uid
:param sec_user_id: 用戶的加密的uid
:return: response
"""
_rticket = str(time.time() * 1000).split(".")[0]
ts = str(time.time()).split(".")[0]
api = construct_api(user_id, _rticket, ts, sec_user_id)
headers = construct_header(user_id, sec_user_id, cookie, query, token, user_agent, _rticket, ts)
print(api)
req = request.Request(api)
for key in headers:
req.add_header(key, headers[key])
with request.urlopen(req) as f:
data = f.read()
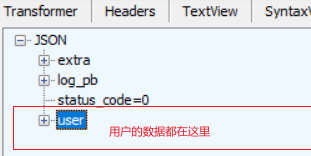
return gzip.decompress(data).decode()根據上面對響應數據的分析,其對應的響應數據是json格式的,而且數據特別多,分析了一下,我找了一些對我比較有用的數據:
# 用戶的抖音號 unique_id=345345345O # 用戶的user_id uid=103600654544 # 用戶的 sec_user_id sec_uid=MS4wLjABAAAA2_HUlxau0riJ8UBMwyd_bUtA8yzKdWepfg9nUc5wQy0 # 頭像地址 avatar_uri=26e880003aefb8cddd496 # 用戶的昵稱 nickname=成都潮人榜 # 用戶的簽名 signature=謝謝關注? # 用戶的出生日期 birthday=1995-01-01 # 用戶的國家 country=中國 # 用戶的省份 province=四川 # 用戶的城市 city=成都 # 用戶所在的區域 district=武侯 # 用戶的粉絲數 follower_count=929219 # 用戶的關注數 following_count=15 # 發布的抖音數量 aweme_count=453 # 發布的動態數量 dongtai_count=480 # 用戶點贊的視頻數 favoriting_count=322 # 總共被點贊的次數 total_favorited=14900700
if __name__ == '__main__': cookie = "" # 你自己的cookie token = "" # 你自己的token query = "" # 你自己的query user_agent = "" # 你自己的user-agent user_id = 103600654544 sec_user_id = "MS4wLjABAAAA2_HUlxau0riJ8UBMwyd_bUtA8yzKdWepfg9nUc5wQy0" res = get_user_detail_info(cookie,query, token, user_agent, user_id, sec_user_id) print(res)
感謝你能夠認真閱讀完這篇文章,希望小編分享的“python如何爬取抖音用戶詳細數據”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





