溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用UCSC XENA綜合性分析某一個基因在癌癥當中的作用,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
今天我們就基于UCSC XENA來簡單的設計一個簡單的課題。
之前在介紹ICGC數據庫使用的時候,我們可以通過ICGC數據庫來進行整個基因組的檢索。比如來查看某個或者某幾個腫瘤當中突變最多的基因是哪個。但是在UCSC XENA當中我們需要有一定的檢索目標。我們沒有辦法去尋找變化最大的基因。我們只能在提前知道某一個基因之后。然后才能進行相關的查詢。但是UCSC XENA比ICGC好的地方在于。ICGC只能查詢突變相關的信息,而在XENA當中,我們則可以檢索和這個基因所有相關的信息以及和臨床特征的相關性。
由于XENA只能檢索指定的基因來進行檢索,所以我們在檢測的第一步需要選擇一個目標基因。為了方便選擇,我們使用GEPIA2來尋找COAD當中最有差異的前10的基因來進行后續的分析
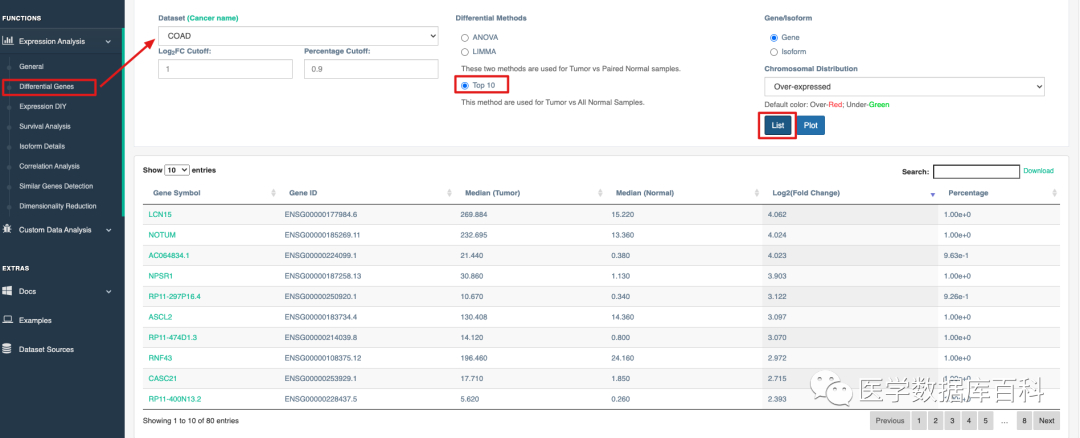
經過這樣的篩選,我們一共獲得了五個在COAD當中高表達的基因。這十個基因分別是:LCN15 ,NOTUM ,NPSR1,ASCL2 ,RNF43。
經過這樣的篩選,我們知道了這幾個基因是和COAD的發生有關系的。但是對于COAD臨床參數的影響,我們不是很清楚。所以進一步的我們想要看COAD當中這十個基因的作用有多大
在XENA當中。我們要做的第一步就是選擇目標癌種,我們可以在數據集選擇的界面輸入關鍵詞就可以獲得相關的數據集了。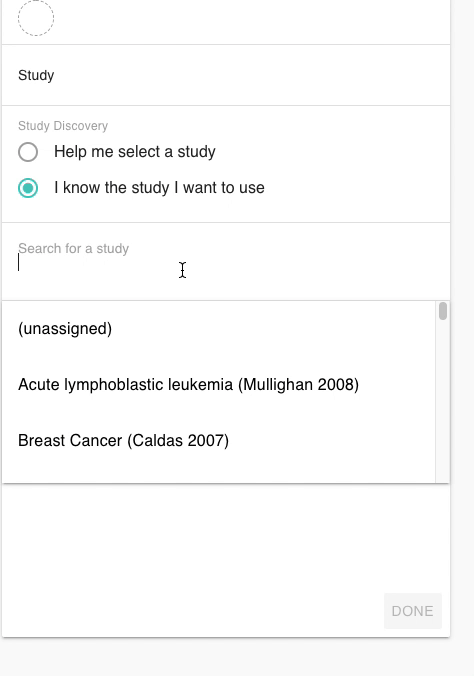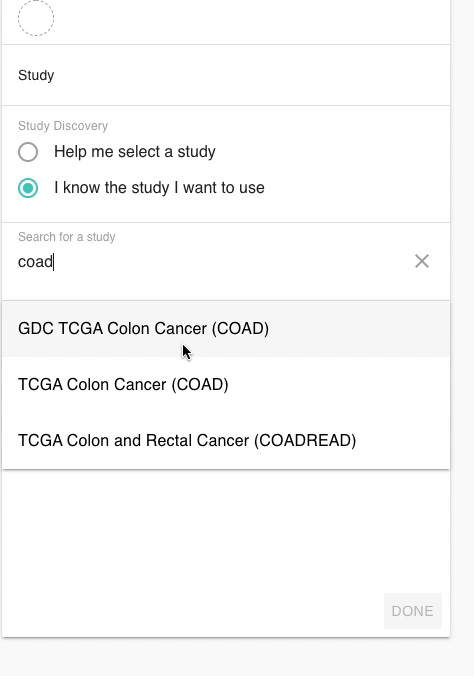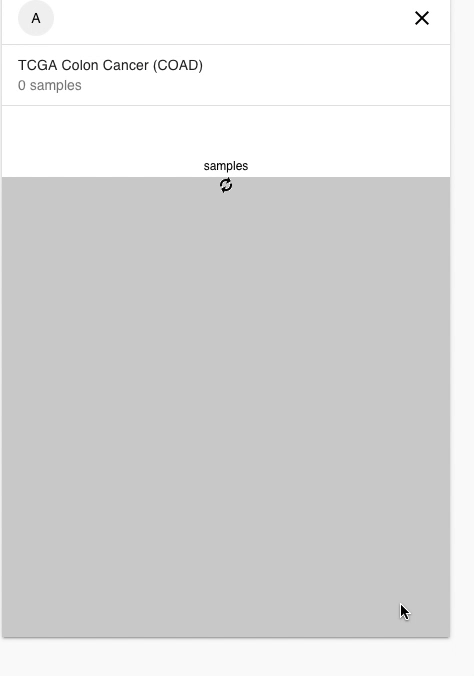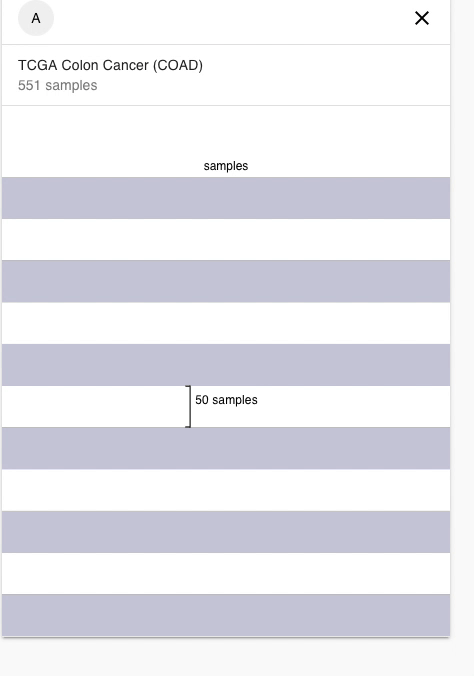
由于我們要對基因表達進行分析。所以第一步就是放置基因相關的表達信息。在XENA里面,對于多基因的表達信息提取,有兩種方式:
一種是直接把所有基因都放進去,這樣的話就可以在一個模塊當中獲得所有目標基因的表達信息,
另外一種的話就是一個基因一個基因的選擇。
前面一種除了可視化好一些,在后面和臨床參數分析方面,也可以一次性現實所有的結果,而后面一種則是可以來進行預后的KM分析。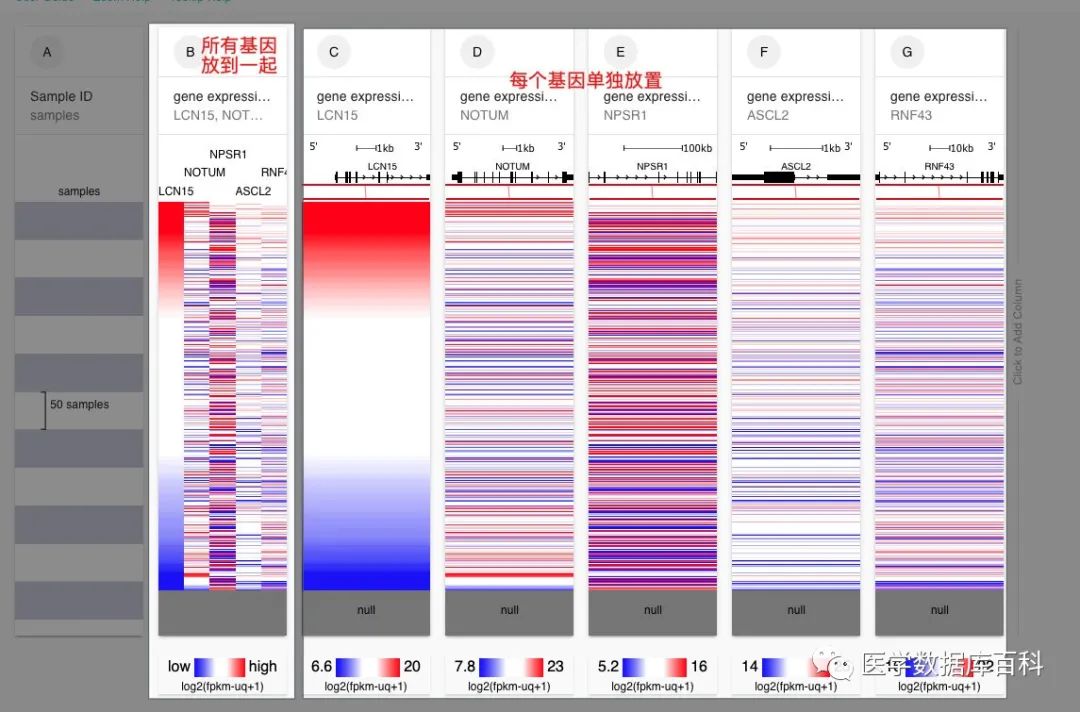
我們在做生信分析的時候,除了差異表達分析,做的第二多的可能就是預后分析了。在XENA 當中,我們對于每一個單數據的模塊,都可以進行預后分析。如果是連續性的,XENA會自動分成兩組來進行KM分析,如果是分類變量那么就可以直接進行分析了。
PS:上面我們也說了。對于預后分析的時候,基因的表達是要單純一個模塊的。所以對于融合到一起的結果。我們是不能進行分析的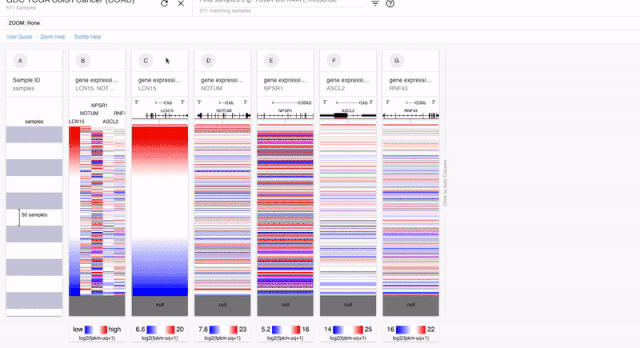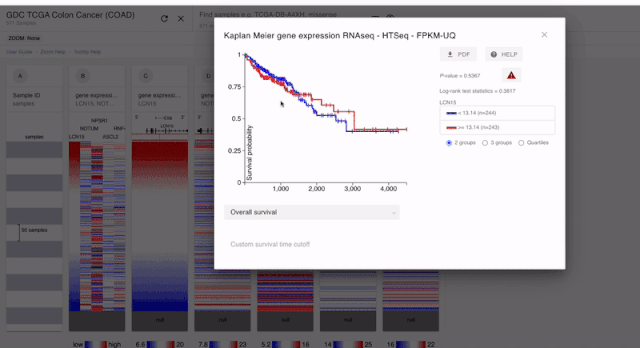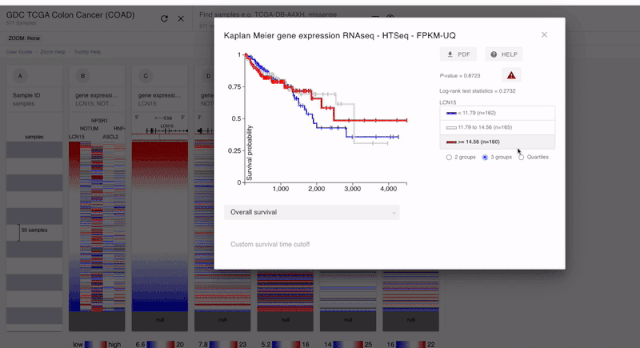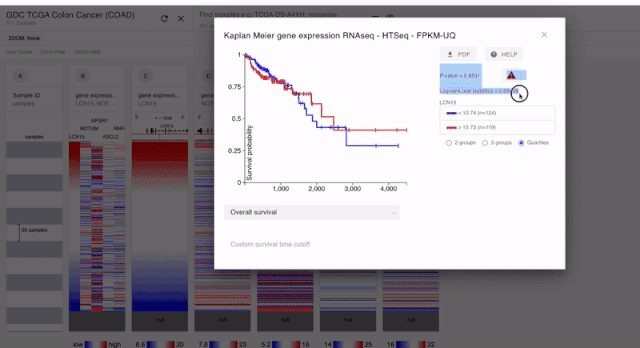
通過以上的分析,我們就可以獲得五個基因的預后分析的結果了。經過分析,我們發現這五個基因和預后都沒有關系????。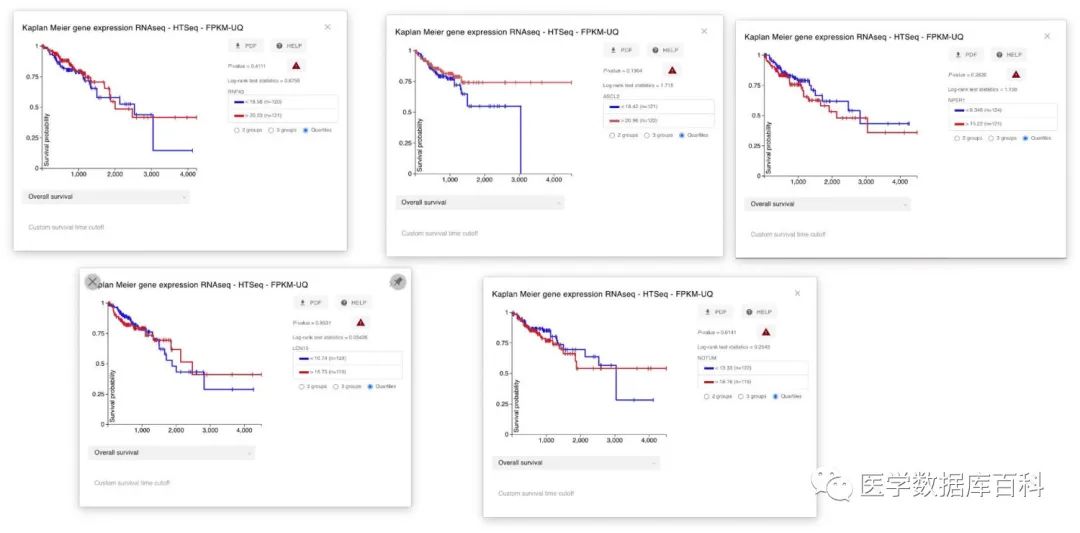
如果XENA只是可以做和預后相關的分析的話,那么其實很多數據庫都是可以做的(GEPIA, Cbio等等)。XENA更好的一點在于,它提供了TCGA里面所有相關的臨床病理參數的結果。我們可以做其他數據庫做不了的臨床參數的分析。比如:TNM分期這種的。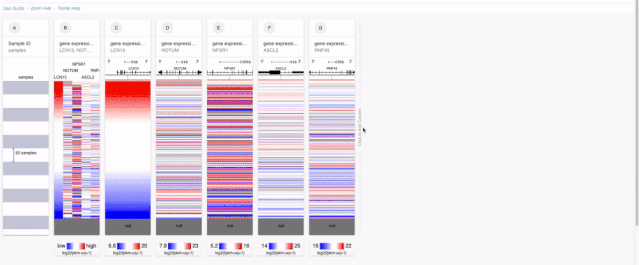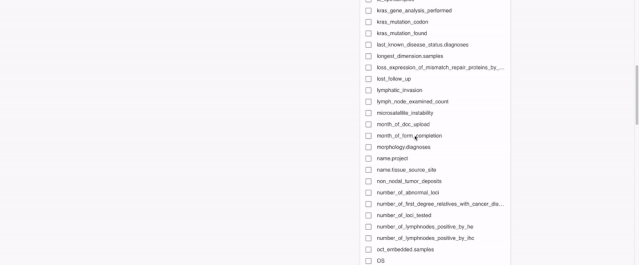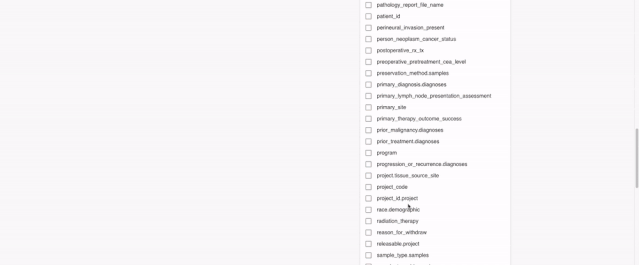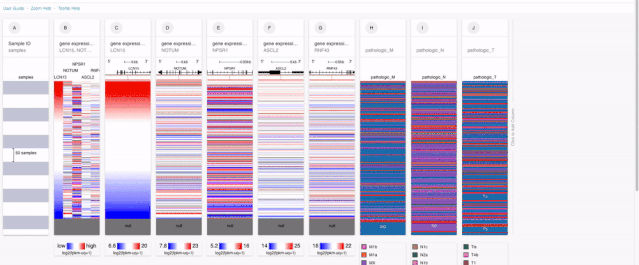
經過一頓的數據添加,我們最終就得到了在COAD當中含有基因表達以及TNM分期數據的數據集。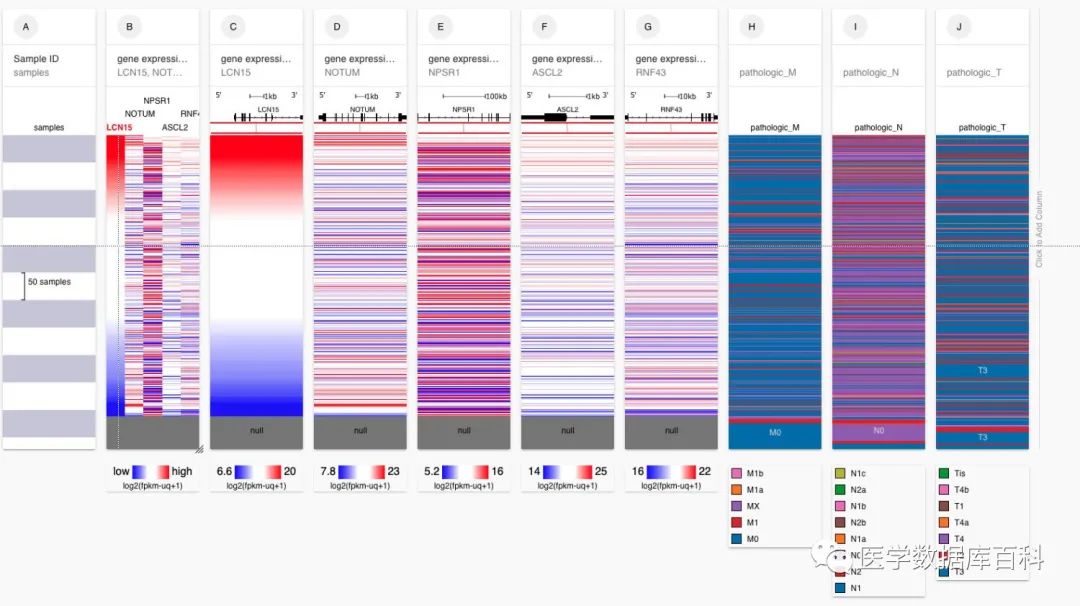
在得到最終想要分析的數據之后,我們發現由于XENA提供的沒有經過修改的數據,所以類似臨床數據是需要經過處理的。例如M分期當中:就包含:M0, M1, M1a, M1b以及Mx這個不確定分期的數據變量。

這個時候,最直接的方法,就是我們點擊Download然后下載到所有的原始數據之后,然后自己來處理數據,然后進行統計分析。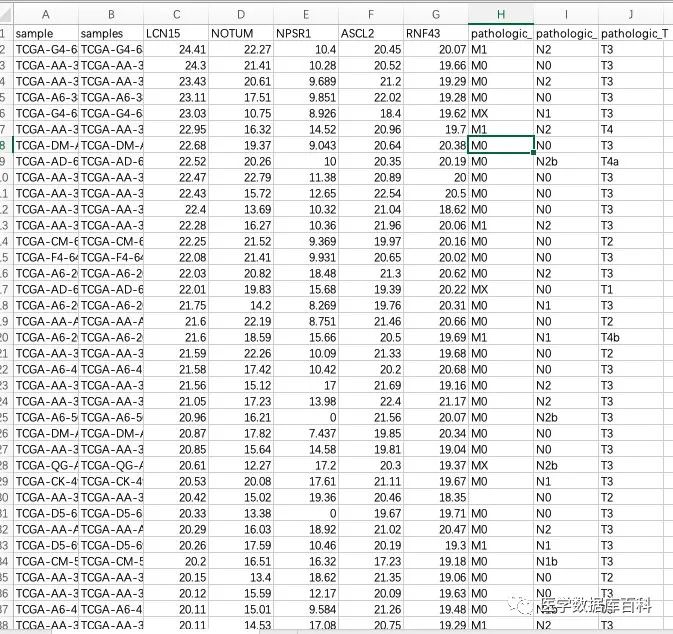
如果說,那我自己對于數據的處理和分析不是很熟練,那這個時候就可以利用XENA自帶的篩選功能來進行分析了。
這里我們利用M分期為例來進行演示XENA的篩選分析。由于操作過程教程。所以就簡單的做了一個視頻。關于XENA具體的篩選原則可以參考: https://ucsc-xena.gitbook.io/project/overview-of-features/filter-and-subgrouping
最終通過分析,我們得到了NOTUM在M分期當中存在差異表達。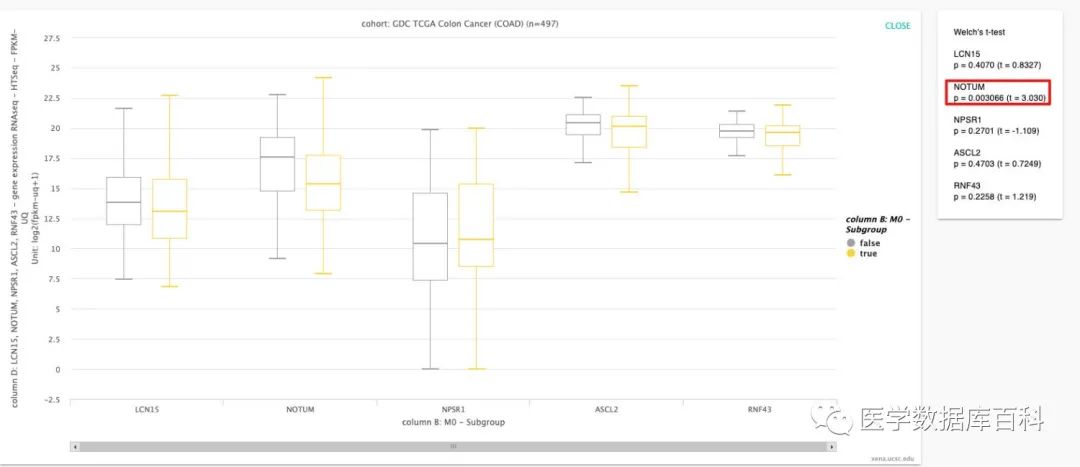
關于如何使用UCSC XENA綜合性分析某一個基因在癌癥當中的作用問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





