溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python爬蟲怎么繞過登錄頁面”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python爬蟲怎么繞過登錄頁面”吧!
前言
很多時候我們做 Python 爬蟲時或者自動化測試時需要用到 selenium 庫,我們經常會卡在登錄的時候,登錄驗證碼是最頭疼的事情,特別是如今的文字驗證碼和圖形驗證碼。文字和圖形驗證碼還加了干擾線,本文就來講講怎么繞過登錄頁面。
登錄頁面的驗證,比如以下的圖形驗證碼。

還有我們基本都看過的 12306 的圖形驗證碼。
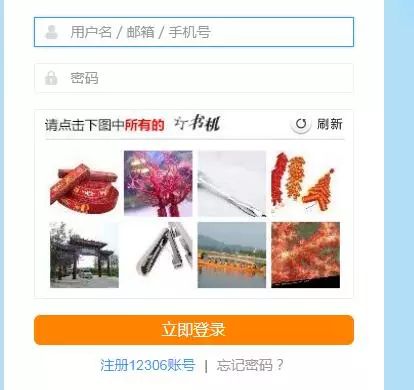
繞過登錄基本有兩種方法,第一種方法是登錄后查看網站的 cookie,請求 url 的時候把 cookie 帶上,第二種方法是啟動瀏覽器帶上瀏覽器的全部信息,包括添加的書簽和訪問網頁的 cookie 信息。
第一種 cookie 方法我們要分析別人網站的 cookie 值,找出相應的值然后添加進去,對于我們不熟的網站,他們可能也會做加密或者動態處理,所以有些網站也不是那么好操作。如果是自己公司的網站需要測試,我們可以詢問對應的開發那個 cookie 值是區分獨立用的值,拿出來放在請求里面就行。
比如我們登錄百度賬號比較費勁,每次都需要登錄也比較繁瑣,我們 F12 打開頁面調試工具,登錄后找到 www.baidu.com 文件,在 cookie 中,我們發現很多值,其中圖中圈起來的就是我們要找的值。
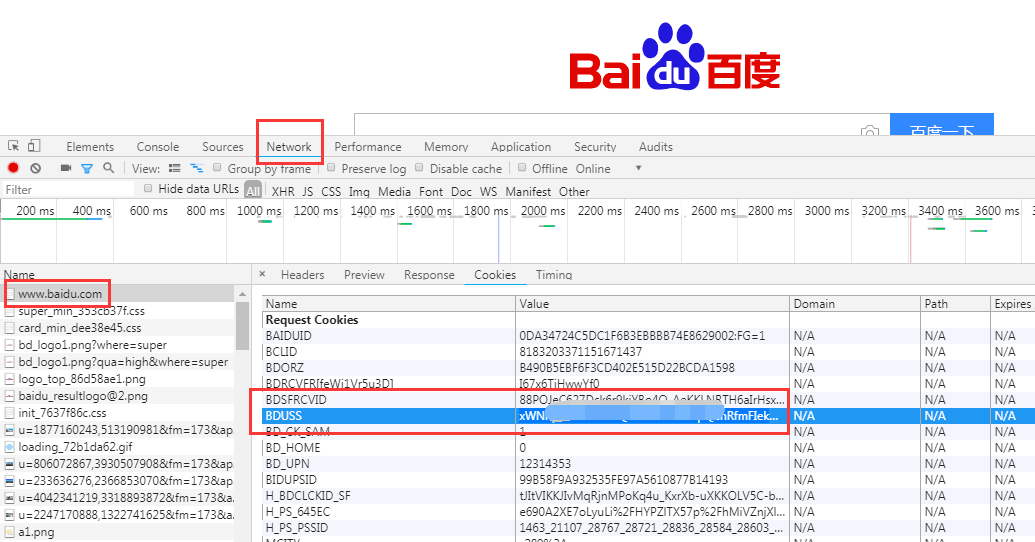
我們在訪問 baidu 鏈接的時候加上這個 cookie 值,這樣就是直接登錄后的百度賬號了。
我們要 selenium 啟動瀏覽器時,需要下載后對應的驅動文件并放在 Python 安裝的根目錄下,比如我會用到谷歌 Chrome 瀏覽器和 Firefox 火狐瀏覽器。
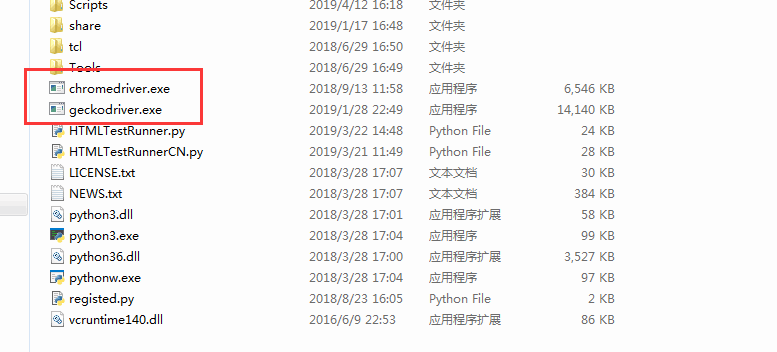 谷歌瀏覽器驅動下載地址:
谷歌瀏覽器驅動下載地址:
http://chromedriver.storage.googleapis.com/index.html
火狐瀏覽器驅動下載地址:
https://github.com/mozilla/geckodriver/releases/
我們每次打開瀏覽器做相應操作時,對應的緩存和 cookie 會保存到瀏覽器默認的路徑下,我們先查看個人資料路徑,以 chrome 為例,我們在地址欄輸入 chrome://version/

圖中的個人資料路徑就是我們需要的,我們去掉后面的 \Default,然后在路徑前加上「–user-data-dir=」就拼接出我們要的路徑了。
profile_directory = r'--user-data-dir=C:\Users\xxx\AppData\Local\Google\Chrome\User Data'
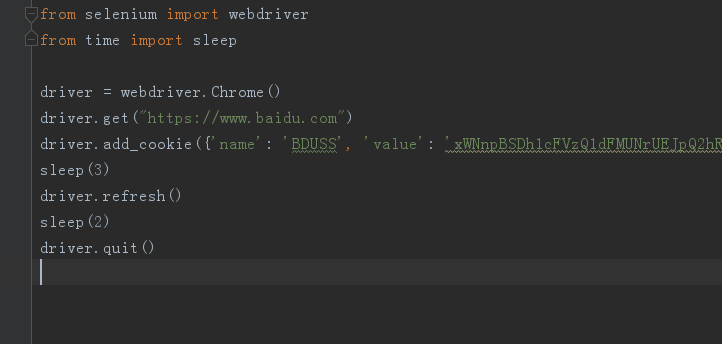
接下來,我們啟動瀏覽器的時候采用帶選項時的啟動,這種方式啟動瀏覽器需要注意,運行代碼前需要關閉所有的正在運行 chrome 程序,不然會報錯。全部代碼如下。

selenium 自動化啟動瀏覽器后我們會發現我之前保存的書簽完整在瀏覽器上方,baidu 賬號也是登錄的狀態。
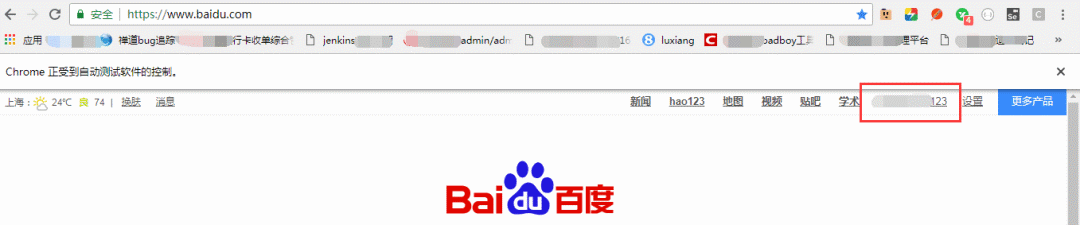 啟動 Firfox 瀏覽器繞過登錄
啟動 Firfox 瀏覽器繞過登錄
Firfox 火狐瀏覽也可以這樣啟動它,設置略有不同。
首先,查看配置文件的存儲路徑,查看方法:幫助–故障排除信息–配置文件夾,把里面的路徑復制過來就行。
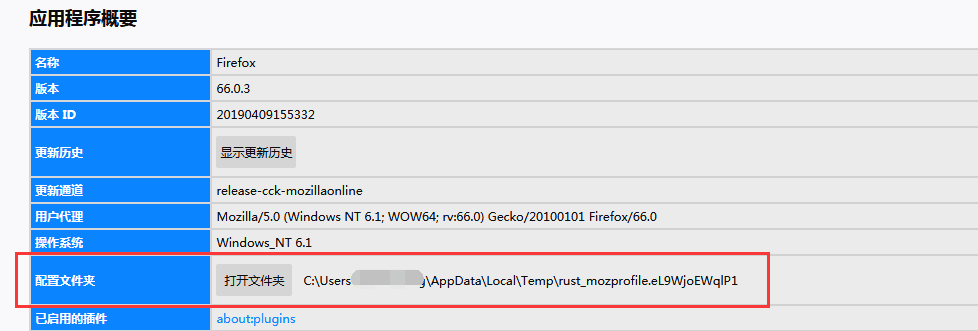
同樣,我們把路徑放在變量中。
profile_path = <span class="hljs-string">r'C:\Users\guixianyang\AppData\Roaming\Mozilla\Firefox\Profiles\dvm6wqam.default'</span>
我們也在火狐瀏覽器中登錄好百度的賬號,用 selenium 自動化啟動帶配置文件的火狐瀏覽器,也會發現啟動時已經啟動了瀏覽器安裝的插件和登錄好的百度賬號。

文中第一個圖是簡書登錄時的圖形驗證碼,我們登錄簡書后(cookie 有一定的時效,貌似有 10 天半個月左右),把上面代碼中的鏈接換成簡書的,再用上面的方法覺可以實現繞過登錄頁的圖形驗證碼。
比如我直接打開我的簡書個人主頁
https://www.jianshu.com/u/52353ffa8b86
自動化啟動后也是保留了登錄的狀態。
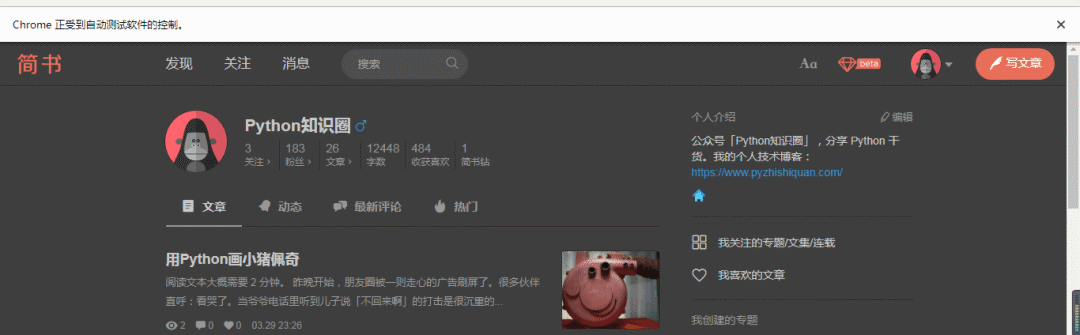
網站的登錄大門已被打開,接下來就可以做自己想做的事情了,比如爬蟲、自動化測試驗證之類的。
感謝各位的閱讀,以上就是“Python爬蟲怎么繞過登錄頁面”的內容了,經過本文的學習后,相信大家對Python爬蟲怎么繞過登錄頁面這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





