溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么用R語言制作柱形圖”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
其實R語言本身就帶有各種作圖函數,比如plot、bar、pie等,而且語法非常簡單明了,為什么還要用ggplot2這種語法獨立性很強、自成體系的作圖包來作圖呢?
一個例子就能感受到:
plot(mpg$cty,mpg$hwy)#R語言內置散點圖函數(無需加載任何輔助工具包)
ggplot(mpg,aes(cty, hwy)) + geom_point(colour="steelblue")+labs(x = "City mpg", y = "Highway") #ggplot2包中的ggplot函數(需先加載ggplot2工具包支持)
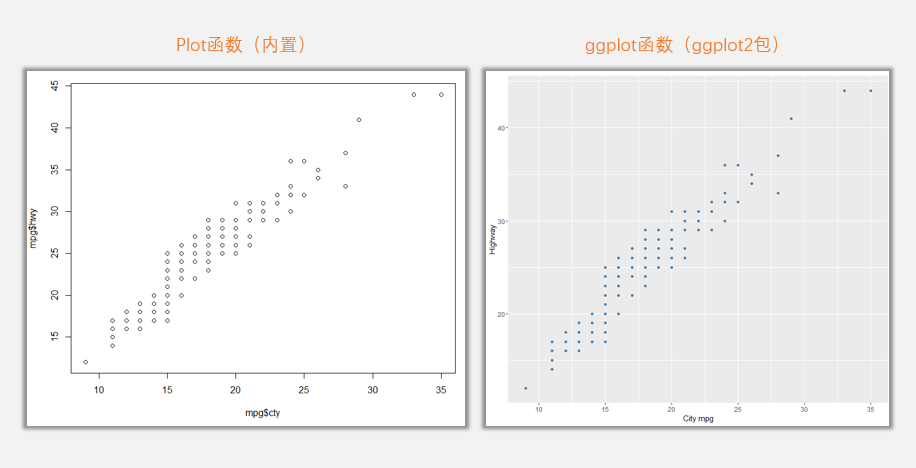
這只是一個很簡單的例子,兩個圖所表達的是同樣的數據變量,同樣的圖表形式,而且在精確度上幾乎毫無差異。
但是,即便兩種味道同樣的食物,外觀的好壞也會影響食欲,這兩個圖表給人的感受,就像是一款諾基亞手機與一款iPhone手機給人帶來的對比一樣,即便功能差異不大,但是外觀上的藝術感已經將兩者拉開了層次。
這也是為啥我曾經剛接觸R語言,還在糊里糊涂的學各種內置圖表函數時,突然看到大神們早已用上了ggplot,立馬選擇入門ggplot的原因。
今天給大家介紹ggplot函數中柱形圖的用法(一大家子呢,單序列柱形圖、簇狀柱形圖、堆積柱形圖、百分比堆積柱形圖、以及分面柱形圖)。
其實嚴格來講,在R預言的作圖函數中,是并不嚴格區分柱形圖與條形圖,因為二者無論是形式上還是功能上都表達著同樣的數據類型和信息。他們有一個通用的名稱——Barplot。
二者之間的轉換往往只需要添加一個額外的參數而已。
coord_flip()
今天先介紹柱形圖:
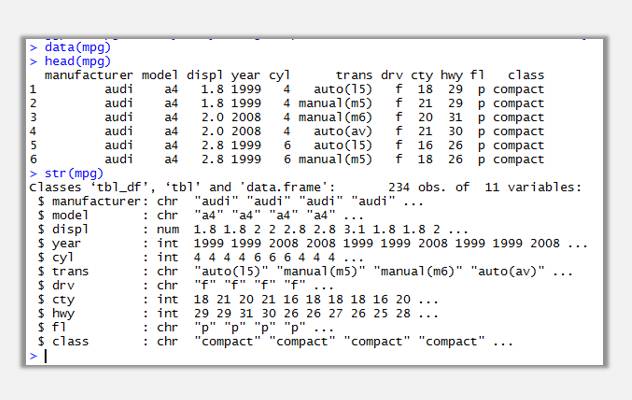
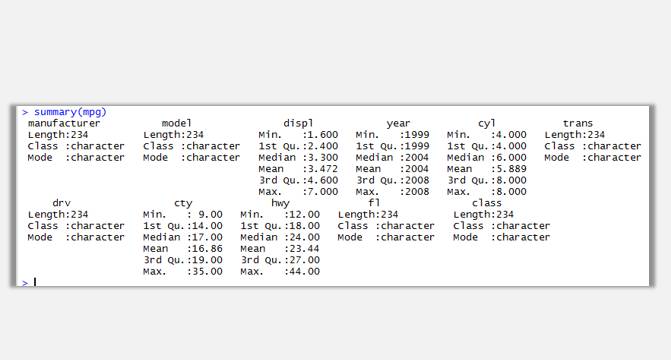
這里就暫且使用ggplot2包中內置的數據集mpg。
通過head(mpg)函數可以查看該數據集前6條記錄,通過str(mpg)查看數據集各變量類型,summary(mpg)可以查看該數據集簡單的統計匯總結果。
單序列柱形圖:
ggplot(mpg,aes(class,displ))+geom_bar(stat="identity",fill="steelblue")
以上參數中,mpg是數據集名稱,aes內的參數依次是x值——class(分類變量),y值——displ(連續變量)。
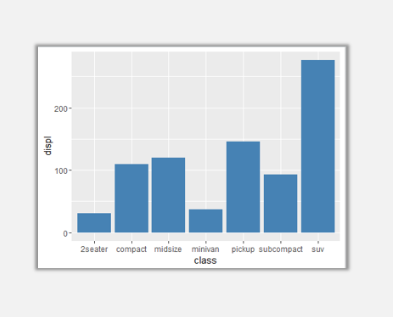
geom_bar是在ggplot坐標系系統之上添加的柱形圖圖層,stat是對其中的數值型變量所做的統計變換(默認為count),fill是顏色填充設定,可以是某一分類變量,也可以直接映射為顏色。
ggplot(mpg,aes(reorder(class,displ),displ)+geom_bar(stat="identity",fill="steelblue")
以上最簡單的單序列柱形圖,其實還有非常多的參數調整設定,這里不再一一詳解,感興趣可以參考ggplot2——數據分析與圖形藝術這本該包作者的書。
多系列簇狀柱形圖:
with(mpg,table(class,year))
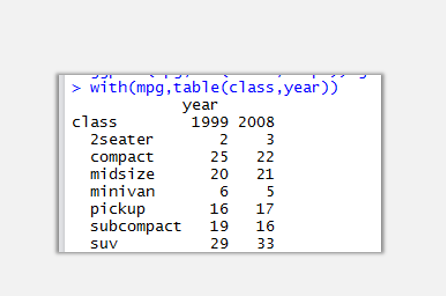
通過匯總可以看到class與year之間的交叉表關系,以下將以這兩個變量來制作系列簇狀柱形圖。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='identity')
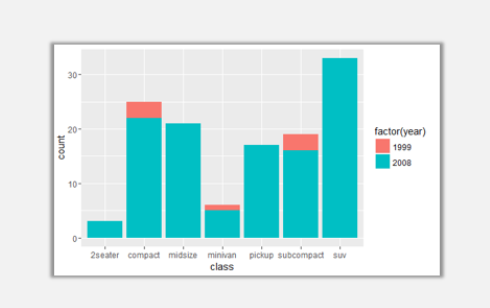
因為year是int型變量,所以在參數設定市需要用factor變成因子型。以上圖表是未做任何設定時的兩系列柱形圖,可以看到兩個系列位置重疊無法看到無法看清楚1999年的柱形圖實際高度。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='identity',alpha=0.3)
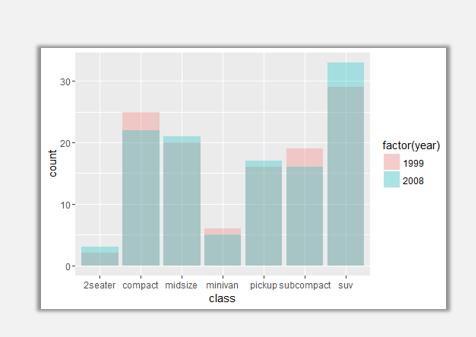
即便是通過alpha參數來設置柱形圖的透明度,也還是很難將1999年與2008年的柱形圖清晰的區別開。這里我們想要看到的效果是,1999年與2008年的柱形圖互不重疊而是并列放置。需要調整postion參數。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='dodge')
將position參數調整為dodge之后,達到了我們想要的效果,此時兩個序列并列,可以清晰的看到彼此高度。
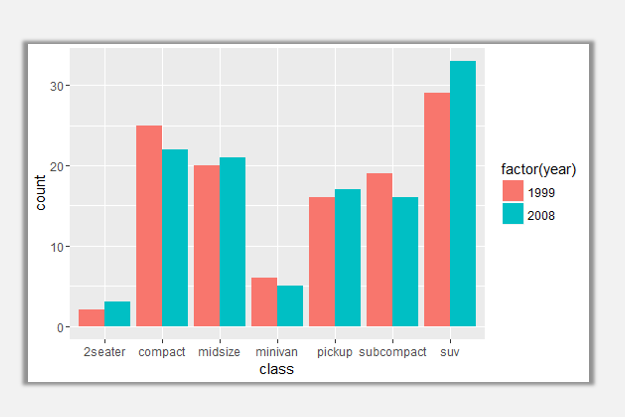
當然我們也可以設置兩個序列堆疊。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='stack')
通過設定position參數為stack,我們可以以堆疊形式處理兩年的指標,同樣達到目標。
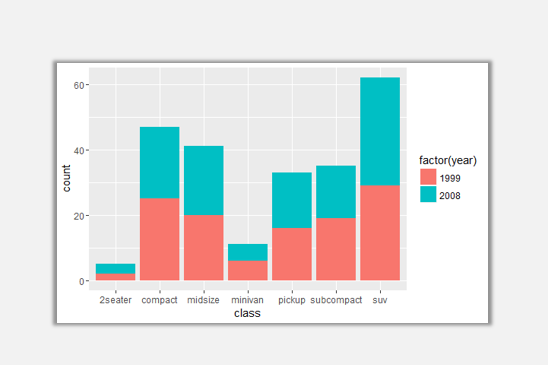
如果我們想要觀察每一個品類中兩年度所占份額百分比,同樣也可以通過修改position參數實現。
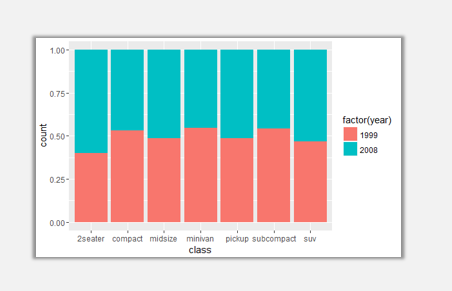
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')
此時便可以得到各品類兩年數據份額占比,仔細觀察你會發現,圖例顏色順序與圖表中顏色順序相反,果然到處都是坑啊。
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='stack')+guides(fill = guide_legend(reverse = TRUE))
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+ guides(fill = guide_legend(reverse = TRUE))
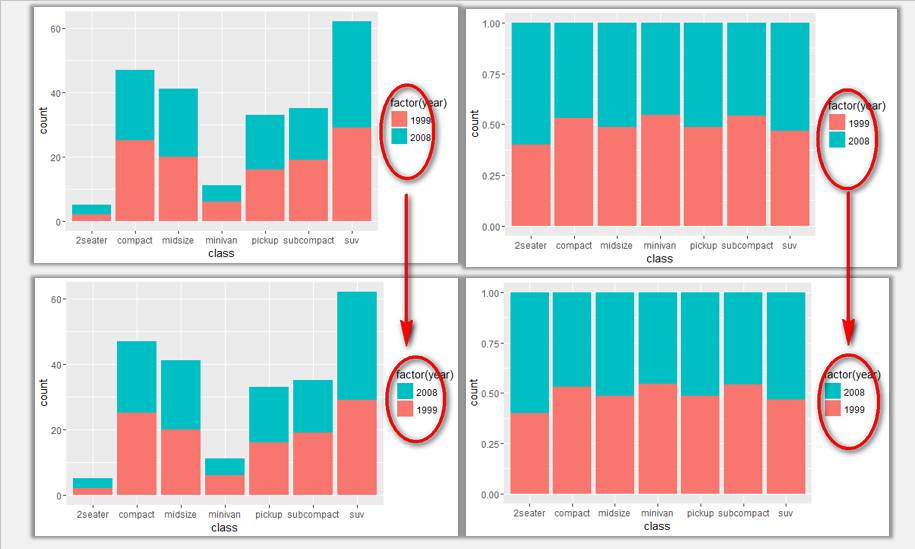
通過設定柱形圖填充順序與圖例顯示順序,使得圖例中的顏色順序與圖表中一致。
最后一種圖表類型是分面組圖:
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+facet_grid(. ~ drv)
ggplot(data=mpg,aes(x=class,fill=factor(year)))+geom_bar(position='fill')+facet_grid(drv~.)
除此之外,我們還可以套用現有主題、對圖表各細分元素進行精修(圖例、坐標軸標簽、數據標簽、柱形間距、背景及顏色主題等),這些細節有很多的專用參數進行調整設置,詳細內容還是最好看看哈德利那本專著,會理解的比較透徹。
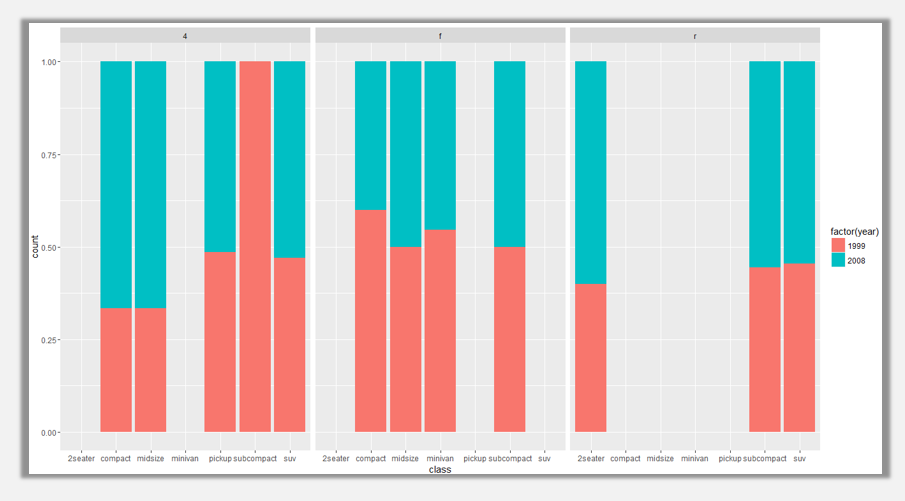

通過設定分面參數:facet_grid,我們可以將某一分類變量做成每一個分類項的分面組圖。
但是考慮到大家日常在excel中作圖比較多一點兒,R語言中的作圖方法與excel截然不同:
excel中通過匯總過后的寬數據作圖(也是office能夠識別的唯一格式)
但是R語言秉承的作圖規則是標準數據源(長數據,也就是類型數據庫格式的數據源)
圖表所支持的數據存儲格式的巨大差別往往成為初學者在R語言圖表面前磕磕碰碰、引起困惑的重大原因。(本人也是初學者哦~)
所以,想要玩轉R語言可視化,必須能夠適應長數據這種標準數據存儲格式的特點。理解變量類型是如何對圖表呈現產生的影響。
想要適應R語言作圖:個人覺得有兩條路子可以參考:
1、假設你已經完全沉浸在或者無法脫離excel的寬數據作圖形式,這樣也就意味著你導入的數據集往往也是寬數據格式。你需要非常熟練的使用R語言中的數據重塑輔助工具包:dplyr、tidyr、reshape2等將寬數據重塑為R作圖支持的長數據格式。好處是可以循序漸進的適應R語言作圖數據的習慣,但是需要額外學很多數據重塑工具與函數。
2、假如你對于長數據有很好的理解(比如經常用統計分析軟件,大部分都接觸的標準長數據,也就是一維表),那么你完全可以直接在excel中將寬數據轉化為長數據(二維轉一維),或者直接將數據庫中的長數據導入R,只需做一些基本的設定即可,至少不會在數據長寬格式轉換上浪費太多時間和精力。
我比較提倡第二種,因為,excel不是標準的可視化軟件(雖說功能不可小覷,但是因為兼顧著數據匯總的辦公屬性,所以對于數據存儲的格式沒有做過多的設定,靈活性太高,為了適應這種情景,微軟的工程師們所開發的圖表引擎也要使用這種匯總后的二維數據表作為作圖數據,這很明顯,因為從數據庫剛導出的一維表(長數據),很多場合是不適合直接在excel中作圖的)。
而像Eviews、SPSS、Stata以及R、Python等專業的統計分析工具甚至Tableau、PowerBI等數據可視化軟件,都是默認接受長數據作圖的。(在數據導入前都會做變量格式設定,盡管也會提供一些長寬數據轉換的工具)。
“怎么用R語言制作柱形圖”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





