溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎樣正確使用K均值聚類,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
聚類算法中的第一門課往往是K均值聚類(K-means),因為其簡單高效。本文主要談幾點初學者在使用K均值聚類時需要注意的地方。
1. 輸入數據一般需要做縮放,如標準化。原因很簡單,K均值是建立在距離度量上的,因此不同變量間如果維度差別過大,可能會造成少數變量“施加了過高的影響而造成壟斷”。
2. 如果輸入數據的變量類型不同,部分是數值型(numerical),部分是分類變量(categorical),需要做特別處理。方法1是將分類變量轉化為數值型,但缺點在于如果使用獨熱編碼(one hot encoding)可能會導致數據維度大幅度上升,如果使用標簽編碼(label encoding)無法很好的處理數據中的順序(order)。方法2是對于數值型變量和分類變量分開處理,并將結果結合起來,具體可以參考Python的實現[1],如K-mode和K-prototype。
3. 輸出結果非固定,多次運行結果可能不同。首先要意識到K-means中是有隨機性的,從初始化到收斂結果往往不同。一種看法是強行固定隨機性,比如設定sklearn中的random state為固定值。另一種看法是,如果你的K均值結果總在大幅度變化,比如不同簇中的數據量在多次運行中變化很大,那么K均值不適合你的數據,不要試圖穩定結果 [2]。
我個人傾向于后者的看法,K均值雖然易懂,但效果一般,如果多次運行的結果都不穩定,不建議使用K均值。我做了一個簡單的實驗,用K均值對某數據進行了5次聚類:
km = MiniBatchKMeans(n_clusters=5)for i in range(5): labels = km.fit_predict(seg_df_norm) label_dist = np.bincount(labels)/seg_df_norm.shape[0]*100 print(label_dist)
打印出每次簇中的數據量占比如下,可以看出幾次運行中每次簇中的數據比例都有很大差別。此處我們明白順序可以是隨機的,但占比應該是相對固定的,因此K均值不適合當前數據集。
[ 24.6071 5.414 25.4877 26.7451 17.7461][ 54.3728 19.0836 0.1314 26.3133 0.0988][ 12.9951 52.5879 4.6576 15.6268 14.1325][ 19.4527 44.2054 7.5121 24.9078 3.9221][ 21.3046 49.9233 2.1886 15.2255 11.358 ]
4. 運行時間往往可以得到優化,選擇最優的工具庫。基本上現在的K均值實現都是K-means++,速度都不錯。但當數據量過大時,依然可以使用其他方法,如MiniBatchKMeans [3]。上百萬個數據點往往可以在數秒鐘內完成聚類,推薦Sklearn的實現。
5. 高維數據上的有效性有限。建立在距離度量上的算法一般都有類似的問題,那就是在高維空間中距離的意義有了變化,且并非所有維度都有意義。這種情況下,K均值的結果往往不好,而通過劃分子空間的算法(sub-spacing method)效果可能更好。
6. 運行效率與性能之間的取舍。但數據量上升到一定程度時,如>10萬條數據,那么很多算法都不能使用。最近讀到的一篇對比不同算法性能隨數據量的變化很有意思 [4]。在作者的數據集上,當數據量超過一定程度時僅K均值和HDBSCAN可用。
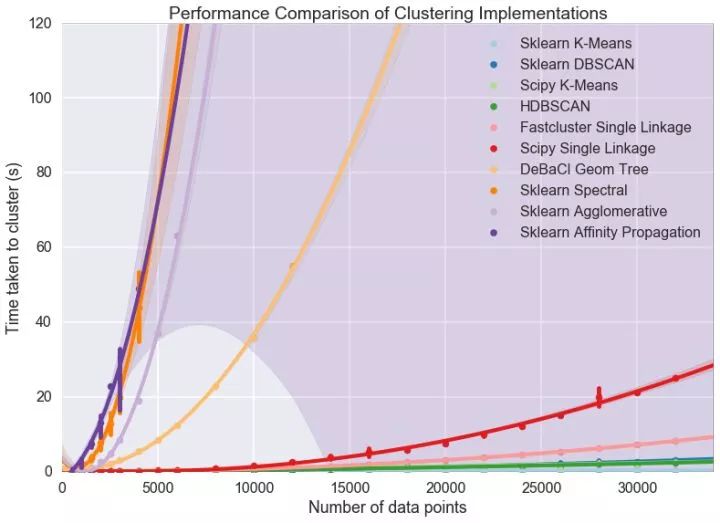
作者還做了下圖以供參考對比。在他的實驗中大部分算法如果超過了10萬條數據后等待時長就變得很高,可能會需要連夜運行。在我的實驗中,還會發現不少算法(SpectralClustering,AgglomerativeClustering等)面臨內存不夠的問題(memory error)。
File "C:\Users\xyz\AppData\Local\Continuum\anaconda3\lib\site-packages\scipy\spatial\distance.py", line 1652, in pdist dm = np.empty((m * (m - 1)) // 2, dtype=np.double) MemoryError
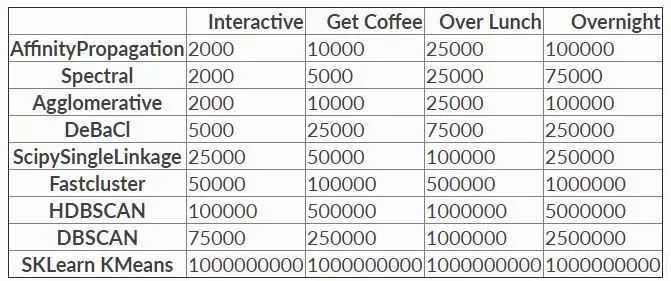
因此不難看出,K均值算法最大的優點就是運行速度快,能夠處理的數據量大,且易于理解。但缺點也很明顯,就是算法性能有限,在高維上可能不是最佳選項。
一個比較粗淺的結論是,在數據量不大時,可以優先嘗試其他算法。當數據量過大時,可以試試HDBSCAN。僅當數據量巨大,且無法降維或者降低數量時,再嘗試使用K均值。
一個顯著的問題信號是,如果多次運行K均值的結果都有很大差異,那么有很高的概率K均值不適合當前數據,要對結果謹慎的分析。
上述就是小編為大家分享的怎樣正確使用K均值聚類了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





