溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python 中怎么實現一個k-means 均值聚類算法,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
scikti-learn 將機器學習分為4個領域,分別是分類(classification)、聚類(clustering)、回歸(regression)和降維(dimensionality reduction)。k-means均值算法雖然是聚類算法中比較簡單的一種,卻包含了豐富的思想內容,非常適合作為初學者的入門習題。
關于 k-means 均值聚類算法的原理介紹、實現代碼,網上有很多,但運行效率似乎都有點問題。今天稍微有點空閑,寫了一個不足20行的 k-means 均值聚類算法,1萬個樣本平均耗時20毫秒(10次均值)。同樣的數據樣本,網上流行的算法平均耗時3000毫秒(10次均值)。差距竟然達百倍以上,令我深感意外,不由得再次向 numpy 獻上膝蓋!
以下是我的代碼,包含注釋、空行總共26行,有效代碼16行。
1import numpy as np 2 3def kmeans_xufive(ds, k): 4 """k-means聚類算法 5 6 k - 指定分簇數量 7 ds - ndarray(m, n),m個樣本的數據集,每個樣本n個屬性值 8 """ 9 10 m, n = ds.shape # m:樣本數量,n:每個樣本的屬性值個數 11 result = np.empty(m, dtype=np.int) # m個樣本的聚類結果 12 cores = np.empty((k, n)) # k個質心 13 cores = ds[np.random.choice(np.arange(m), k, replace=False)] # 從m個數據樣本中不重復地隨機選擇k個樣本作為質心 14 15 while True: # 迭代計算 16 d = np.square(np.repeat(ds, k, axis=0).reshape(m, k, n) - cores) 17 distance = np.sqrt(np.sum(d, axis=2)) # ndarray(m, k),每個樣本距離k個質心的距離,共有m行 18 index_min = np.argmin(distance, axis=1) # 每個樣本距離最近的質心索引序號 19 20 if (index_min == result).all(): # 如果樣本聚類沒有改變 21 return result, cores # 則返回聚類結果和質心數據 22 23 result[:] = index_min # 重新分類 24 for i in range(k): # 遍歷質心集 25 items = ds[result==i] # 找出對應當前質心的子樣本集 26 cores[i] = np.mean(items, axis=0) # 以子樣本集的均值作為當前質心的位置
這是網上比較流行的 k-means 均值聚類算法代碼,包含注釋、空行總共57行,有效代碼37行。
1import numpy as np 2 3# 加載數據 4def loadDataSet(fileName): 5 data = np.loadtxt(fileName,delimiter='\t') 6 return data 7 8# 歐氏距離計算 9def distEclud(x,y): 10 return np.sqrt(np.sum((x-y)**2)) # 計算歐氏距離 11 12# 為給定數據集構建一個包含K個隨機質心的集合 13def randCent(dataSet,k): 14 m,n = dataSet.shape 15 centroids = np.zeros((k,n)) 16 for i in range(k): 17 index = int(np.random.uniform(0,m)) # 18 centroids[i,:] = dataSet[index,:] 19 return centroids 20 21# k均值聚類 22def kmeans_open(dataSet,k): 23 24 m = np.shape(dataSet)[0] #行的數目 25 # 第一列存樣本屬于哪一簇 26 # 第二列存樣本的到簇的中心點的誤差 27 clusterAssment = np.mat(np.zeros((m,2))) 28 clusterChange = True 29 30 # 第1步 初始化centroids 31 centroids = randCent(dataSet,k) 32 while clusterChange: 33 clusterChange = False 34 35 # 遍歷所有的樣本(行數) 36 for i in range(m): 37 minDist = 100000.0 38 minIndex = -1 39 40 # 遍歷所有的質心 41 #第2步 找出最近的質心 42 for j in range(k): 43 # 計算該樣本到質心的歐式距離 44 distance = distEclud(centroids[j,:],dataSet[i,:]) 45 if distance < minDist: 46 minDist = distance 47 minIndex = j 48 # 第 3 步:更新每一行樣本所屬的簇 49 if clusterAssment[i,0] != minIndex: 50 clusterChange = True 51 clusterAssment[i,:] = minIndex,minDist**2 52 #第 4 步:更新質心 53 for j in range(k): 54 pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 獲取簇類所有的點 55 centroids[j,:] = np.mean(pointsInCluster,axis=0) # 對矩陣的行求均值 56 57 return clusterAssment.A[:,0], centroids
函數create_data_set(),用于生成測試數據。可變參數 cores 是多個三元組,每一個三元組分別是質心的x坐標、y坐標和對應該質心的數據點的數量。
1def create_data_set(*cores): 2 """生成k-means聚類測試用數據集""" 3 4 ds = list() 5 for x0, y0, z0 in cores: 6 x = np.random.normal(x0, 0.1+np.random.random()/3, z0) 7 y = np.random.normal(y0, 0.1+np.random.random()/3, z0) 8 ds.append(np.stack((x,y), axis=1)) 9 10 return np.vstack(ds)
測試代碼如下:
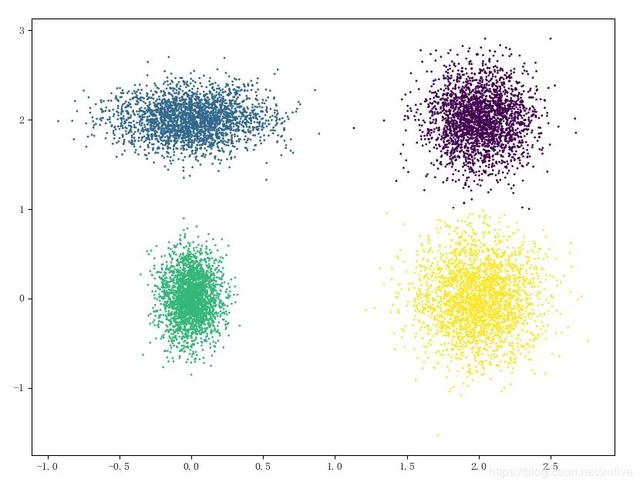
1import time 2import matplotlib.pyplot as plt 3 4k = 4 5ds = create_data_set((0,0,2500), (0,2,2500), (2,0,2500), (2,2,2500)) 6 7t0 = time.time() 8result, cores = kmeans_xufive(ds, k) 9t = time.time() - t0 10 11plt.scatter(ds[:,0], ds[:,1], s=1, c=result.astype(np.int)) 12plt.scatter(cores[:,0], cores[:,1], marker='x', c=np.arange(k)) 13plt.show() 14 15print(u'使用kmeans_xufive算法,1萬個樣本點,耗時%f0.3秒'%t) 16 17t0 = time.time() 18result, cores = kmeans_open(ds, k) 19t = time.time() - t0 20 21plt.scatter(ds[:,0], ds[:,1], s=1, c=result.astype(np.int)) 22plt.scatter(cores[:,0], cores[:,1], marker='x', c=np.arange(k)) 23plt.show() 24 25print(u'使用kmeans_open算法,1萬個樣本點,耗時%f0.3秒'%t)
測試結果如下:
1PS D:\XufiveGit\CSDN\code> py -3 .\k-means.py 2使用kmeans_xufive算法,1萬個樣本點,耗時0.0156550.3秒 3使用kmeans_open算法,1萬個樣本點,耗時3.9990890.3秒
效果如下:
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





